Service Providers today are at a critical inflection point as they work to transform their networks, and indeed, their businesses. ACG Research took an in-depth look at the industry trends driving this digital transformation and the steps necessary to ensure success.
Some of ACG’s key findings include:
Service providers must embrace digital transformation to meet market needs and remain competitive.
The digital transformation is complex and requires that the operator create the right ecosystem as they undertake it.
At the heart of that ecosystem is the right partner, which brings the right scale, technology, solutions, and services to successfully shepherd the operator through this multifaceted, typically multi-year process.
A tight relationship with the right partner is essential for success.
To gain additional depth and perspective, ACG’s CEO, Ray Mota, sat down with Cisco’s vice president of Service Provider Technologies, Yvette Kanouff, to talk about the opportunities and challenges she sees in today’s service provider industry.
Our data shows that there are 5 to 10 breaches per 1000 seats every week. That number is staggering and exemplifies the limits of traditional prevention. Most of these attacks will be done using repackaged malware distributed by known threat actors. We also see that such attacks not only remain undetected for a very long time, but tend to escalate with further malware. A typical scenario starts as a seemingly innocent download of a free tool bundled with adware that later on injects malicious advertisements through the web browser. Only later, when more data is collected, we see other malware ranging from info stealers and banking Trojans to ransomware. And finally, any stolen data will be used against you – in a targeted attack. How do we effectively respond to this?
Let’s use Cisco’s advanced security portfolio for breach detection and mitigation to address these problems. I will show you how we can take an unknown infection or a full-scale breach (that passed the perimeter defenses), figure out how it happened, and walk back from it faster than ever before. To successfully do so, let’s focus on a 3-step process:
Breach Detection and Prioritization – reveal the presence of a breach and its objectives
Threat Containment – swift action is required to prevent the acute risk of data leaks
Final Response and Remediation – more thorough analysis of the root cause and proper cleaning
Breach Detection and Prioritization
Detecting a breach is the most challenging of the three steps. A breach indicates that the attacker has penetrated all defenses and is likely going to impersonate somebody else and use gathered information for further malicious actions. There are two types of attacks resulting in a breach. The first type represents established attackers using new or polymorphic variants of malware. The second is completely new attacks or attackers that do not have coverage in security databases and feeds, and thus require a generic analytics-based detection system.
Before we even get to investigate anything, the analyst has to decide how to prioritize. To be highly actionable we want the risk to be determined automatically and aggregated with as much context as possible. This is hard. Remember that we are likely dealing with malware that managed to infect the endpoint – chances are that nobody really knows the exact origin and purpose. Generating a unique sample, domain and communication pattern has become a commodity. Also, the actual malicious mission often varies – the attackers are opportunistic and might steer the malware after their initial foothold. While the actual malicious activity cannot be fully predicted, having a good estimate of the attacker’s intent helps tremendously. Here are the techniques used by Cisco to solve this:
Campaign attribution by behavioral similarity of command and control communication – Cognitive Threat Analytics (CTA) provides risk rating natively based on observed behavior for every single detection. Moreover, whenever an attribution to a known malicious campaign can be made through behavioral similarity, the campaign description is given with details on the techniques, intents and recommended remediation steps
Attack prediction by global sandboxing database correlation – Threat Grid estimates likelihood of a particular mission based on previously observed behavior from malware of the same origin or behavior. This corresponds to the arsenal that the adversary has and probability that it will be utilized
Detecting executed malware and presence of IoCs with retrospection – AMP for Endpoints records file activity, regardless of the file’s disposition. If malicious behavior is spotted later on, AMP sends your security team a retrospective alert, that contains the complete history of the threat: where the malware came from, where it’s been, and what it’s doing
Threat Containment
Breaches can result in data loss within a matter of hours so the goal of this phase is to follow traces from command and control channels to individual processes and files so that they can be stopped and removed. The same traces are also used to estimate the spread. The key here is speed and automation – this is not a forensics exercise. The security architecture must help us reveal those traces and apply quick and dirty cuts that will disrupt an ongoing attack. We should also block malicious domains and IPs that correspond to the attack. This step includes:
Following traces from C&C to a particular file on the endpoint – AMP for Endpoints integration with CTA makes it simple to tie C&C communication to a particular file or process on a host
Estimating the spread on the endpoint and in the network – Device and File Trajectory features in AMP for Endpoints show device and file level details, as well as provide information about other machines where the file was seen
Applying the policy to block malicious file and network communication across the entire environment – placing a file into quarantine and blocking communications with IP addresses and domains that represent C&C is a simple task in the AMP for Endpoints console using Outbreak Control features
Final Response and Remediation
Immediate reaction prevents the imminent risk of a data breach but is unlikely that the malware would be completely eradicated making the endpoint safe to use. First of all, there are likely other components and backup mechanisms of the attack. Second, we have not determined the root cause and we may still be vulnerable to reinfection. Finally, once malware is installed, it often hurts the security posture of the machine. As a result, the majority of breaches cannot be automatically cleaned and require a reimage of the endpoint. To prevent future attacks a policy update may also be required. This step includes:
Finding additional malicious activity on the endpoint – use Device Trajectory feature for visual representation of processes and file execution on your endpoints to get a better understanding of what preceded the infection and which other components could be involved
Analyzing the root cause – should be done before endpoint is reimaged to ensure the door is closed for attackers who try to get in using the same path. AMP for Endpoints helps determine the applications that were seen introducing malware into the network, as well as points out the vulnerabilities in those applications
Cleaning up the affected endpoints – due to the complex nature of infections these days, it’s almost impossible to record or predict all modifications that were done to the endpoint as a result of an active infection. Therefore, the most effective way of cleaning a breached machine is to send it for reimage. For the low or medium risk infections, you might be able to clean the infection using endpoint cleaning tools, however be careful and watch for reinfections if you choose to do so
Updating policies to prevent reinfection – after the cleaning is done, policies should be reviewed and updated accordingly
As we have seen, dealing with a breach takes several steps, that should be done very quickly, and requires that tools be used in a very orchestrated way. We need a powerful analytics platform to detect and prioritize the breach in the first place. After that, we collect contextual information about C2 communications and tie it back to malicious files or processes on the endpoint. We immediately block those files and communications in case the breach has a critical risk level (damaging to the organization, e.g. data exfiltration), and then automatically quarantine the endpoint. In our final response, we have more time to assess the endpoint, uncover other components of the attack, perform root cause analysis and clean up.
Remember, you only have hours before data stealing begins!
Review a practical example of how Incident Response can be done using Cisco’s Advanced Threat Solutions:
For more in-depth information on operationalizing Cisco’s Advanced Threat Solutions, review the Cisco Live session below:
Cisco Data Center solutions ignite innovation on campuses across the globe.
Our simple, automated, and secure data center architecture – a central plank in the Digital Education Platform – equips schools to integrate hybrid infrastructure into a unified engine for transformative innovation.
Run basic learning applications to power advanced research. Ensure exceptional experiences on the applications and services you deliver. Equip big data and advanced STEM applications to fuel groundbreaking research. Embrace hybrid transformation to grow the impact of technology on teaching and learning.
Got your attention? Watch the video below to see how Cisco Data Center solutions can power all this and more.
Manufacturing as a culture is data driven. Talk to anyone who has worked in the industry for some time—from an operator leading a cell to a manufacturing executive—and they should be able to point to the numbers around output, efficiency, and productivity, among others.
With this in mind, however, the manufacturing industry has been conservative when it comes to factory modernization projects. These projects can provide useful data that encompasses an immense amount of value to operations.
A recent article from the Manufacturers Alliance for Productivity and Innovation
(MAPI), demonstrates some of the reasons behind this approach:
How digital transformation can benefit system integrators
The upside to this digital transformation is that it will create new business models for companies that can understand the technology shifts while providing valuable guidance for manufacturing clients.
System integrators (SIs) will especially benefit from digital transformation. Their reputations are built on the implementation of critical manufacturing projects, as well as their expertise in developing them up. SIs have long been at the forefront of architecture design, installation, project management and training, and support of new technologies. The shift to digital manufacturing could also shift the conversation for SI’s from one-off projects to larger lifecycle projects and new annuity streams that ultimately deepen relationships with their manufacturing customers.
Join our business expansion strategies webinar
Recognizing this evolution—and based on conversations with industrial system integrators—we’ve partnered with the Control System Integrator Association (CSIA) to present an SI Top 5 Business Expansion Strategies webinar. This event is completely dedicated to the SI business and focuses on where SIs can make themselves more relevant and more integrated with their customers. In this webinar, SIs will learn about the technology affecting this space, as well as best practices, architecture design, and key considerations for working with customers. We’ll cover topics such as:
Unmanaged vs. managed switches
Designing security into architecture
Network considerations such as orchestration, automation, standards, and deployment
Wireless
Physical infrastructure
If you’re a CSIA member or an SI who wants to learn more, I invite you to join us on Thursday, September 14. You can register here. I hope you’ll join us, and we welcome any feedback on topics you’d like to see us cover in the future.
I also invite you to explore the following manufacturing topics:
The more they overthink the plumbing, the easier it is to stop up the drain. — Commander Montgomery Scott, on sabotaging the much-ballyhooed, transwarp-capable USS Excelsior.
Scotty crippled the newer Starfleet vessel so that the renegade Admiral James Kirk and his small band of loyal companions can steal the USS Enterprise out of spacedock. (They had to go search for Spock, if you recall.) His words played to the particular plot point in Star Trek III: The Search for Spock (1984), but they’re true of today’s IT world as well.
Technology is advancing fast, networks are bigger and more complex, objects ranging from household assistants (like Amazon Echo or Google Home) to sophisticated weapons systems are now part of the network, and more is coming every day. Meanwhile, the bad guys are moving just as fast if not faster seeking ways to break into systems to steal sensitive data, or just to cause disruption.
So, it’s noteworthy that with the stroke of a pen earlier this month, President Trump made U.S. Cyber Command a unified combatant command, taking it out from under U.S. Strategic Command.
The elevation of CYBERCOM fulfills a directive contained in the Fiscal Year 2017 National Defense Authorization Act, passed last November.
CYBERCOM had been a subordinate organization to U.S. Strategic Command since CYBERCOM was created in 2009. Raising its status “will strengthen our cyberspace operations and create more opportunities to improve our Nation’s defense,” Trump said in a statement released August 18.
The action is just another sign that the federal government is seriously committed to combating the cyber threat, which has recently been metastasizing into something more ominous than ever before. (Download the Cisco Midyear Cybersecurity Report for a detailed analysis.)
Hackers and cyber criminals are becoming more dangerous.
As the report details, attackers have gained the ability to lock systems and destroy data as part of their attacks. This might make the federal government an even more attractive target to some threat actors. These new abilities pose an immediate threat to the government’s sensitive and classified data, and necessary IT operations required to deliver on their missions.
Malicious actors are taking advantage of the ever-expanding attack surface that comes with the proliferation of handheld devices, the Internet of Things and other emerging platforms. The breadth and depth of recent ransomware attacks alone demonstrate how adept adversaries are at exploiting security gaps and vulnerabilities across devices and networks for maximum impact.
Like other organizations, federal and agencies experience lack of visibility into dynamic IT environments, “shadow IT” that complicates cyber defense strategies and a constant barrage of security alerts, all of which make the IT security environment more complex.
The creation of CYBERCOM eight years ago demonstrated that the government saw the potential of cyberattacks as a national security threat; the elevation shows that the perceived risk is even greater now — a correct perception, to be sure.
CYBERCOM Commander Adm. Mike Rogers said the key advantage of elevating the command is speed. “I believe that elevation plugs us more directly into the primary decision-making processes within the department, which is really optimized for combatant commanders. It also makes us faster because now I’ve got one less layer I have to work through,” he said, as quoted in C4ISRNET.
Still unresolved is a push to separate CYBERCOM from the National Security Agency, which Rogers also commands. You can read a good analysis of the pros, cons and complications of such a split at Lawfare.com.
Ultimately, whether CYBERCOM splits from NSA or not, its elevation to a full command marks a new and heightened awareness of the risks of cyber exploits, which will surely be a strong step forward.
Fall is just around the corner, and communities around the world are preparing for change; for some, a change as they return to school, and for others, a change in the seasons. Cisco employees are also gearing up to “Be the Bridge” and become the change in their local communities.
Enter our second annual Global Service Month. This month-long initiative, which runs the length of September, is an incredible opportunity to celebrate Cisco’s commitment to making a collective impact in the communities where we live, work and play.
Cisco’s Global Service Month is also a part of My Making a Difference, one of Our People DealMoments that Matter. During the month, Cisco employees can come together and collaborate on numerous projects that address critical needs in different countries and give back on-campus, off-site, and virtually.
Last year, the program ran via a week-long initiative, spanning 26 countries, 85 Cisco office locations, more than 5,000 employees, and 20,000 volunteer hours. With all of the success of the past year and employee feedback that we can do even more, we decided to expand into a month-long program.
Global Service Month Co-Executive Sponsors once again include Karen Walker, SVP and Chief Marketing Officer, and Joe Cozzolino, SVP, Cisco Services, both strong advocates for empowering our employees to do good in the world and improve our communities at large.
As a global organization with employees who work both on-site and on a remote basis, we believe in the need to provide everyone with a diverse range of options to give their time, accommodating different schedules, geographies, and diverse styles of working.
In the spirit of this Cisco work culture, we have partnered with Missing Maps to provide virtual volunteering projects for teams that can gather around a conference table, dial in via TelePresence, or join from their desks from any location around the world.
What is Missing Maps?
A collaboration between multiple humanitarian organizations, including the American Red Cross, to map out the most vulnerable places in the developing world. Through this unique opportunity, people around the globe can use an open website to identify roads, structures and other key features on maps for use by first responders and aid agencies. Many of the places where disasters occur are literally “missing” from any map. The project enables first responders better access to relief efforts around the world.
The Cisco Foundation provided early stage support for the development of the Missing Maps platform in 2015 and the American Red Cross has been a longtime strategic partner of Cisco’s, with over US$21 million in donations to local, national, and international Red Cross programs.
Every dollar invested in disaster preparedness saves US$7 in disaster response, and mapping unmapped and vulnerable areas is a critical step to increasing the preparedness of relief agencies and communities to respond quickly and effectively in times of crisis.
Cisco Operations: Virtual Map-A-Thons During Global Service Month
Several Cisco business functions are conducting “Map-A-Thons” within their own organizations – an excellent teamwork opportunity! Cisco’s Operations, led by SVP, Rebecca Jacoby, is taking the lead in making a difference. As one of the largest organizations within Cisco, with almost 8000 employee across many geographies, organizing a singular, site-level event for Operations can be challenging.
Last year, the group had success in leading several giving back activities, and wanted to continue their momentum by coming together as one, cohesive Operations team, aligned with Global Service Month.
Cisco Operations is challenging their team to volunteer one hour with Missing Maps, in addition to the variety of giving back events spanning the group’s eight functions across the globe. In the spirit of friendly competition, the top individual Operations “mappers” from each of the eight functions will receive a mentoring session with an Operations leader.
With an organization of global scale, opportunities like Missing Maps enable virtual teams to collaborate, communicate and build new in-roads – both with colleagues and virtually!
Today, with disasters around the world that affect or displace millions, helping first responders to identify roads, buildings and other features aids those on the ground to make better-informed decisions during times of urgent need. No matter where you are in the world, you can lend a hand.
To join the Missing Maps “Map-a-Thons,” Cisco employees do not need to be a part of Operations. Multiple Map-a-Thons are planned throughout September, with a number of Virtual Map-a-Thons planned for September 12.
Beyond Global Service Month, to help employees Be the Bridge to their communities all year, Cisco provides five calendar days per year of paid volunteer-time-off through our Time2Give employee benefit, a matching gifts program through the Cisco Foundation, and other global programs that align with our employees’ passions.
Together, we can all make a difference. Throughout September, spread the word on social media and share your stories by using #ServiceMonth, #WeAreCisco, and #BeTheBridge hashtags.
When I was asked to write my experiences preparing to present in the DevNet Zone at Cisco Live 2017, the first thought that came to mind was, “The greatest trick I ever played was convincing the room I was an expert.” Now I may be taking some artistic liberties with Kevin Spacey’s monologue from the 1995 movie ‘The Usual Suspects’ (which in turn paraphrased the 19th century philosopher Charles Baudelaire), but that phrase accurately represents my six weeks leading up to Las Vegas.
Overflow audience for my “Introduction to NETCONF, RESTCONF,
and YANG” workshop in the DevNet Zone at Cisco Live 2017
Before I provide details on how I pulled off my trick it would be helpful if I provided a little background. At the start of the year I was asked if I had any interest in presenting an “Introduction to NETCONF, RESTCONF, and YANG” with a companion lab. The thought was if the material was presented by a traditional network engineer it would be better received.
The term traditional network engineer is a pretty accurate description of my career. I would describe myself as the typical BGP/QOS/Spanning-Tree network engineer. Significant portions of my career have been spent designing, deploying and supporting large scale WAN networks.
Like many of my peers I’m just starting to dip my toes into network programmability by teaching myself a little Python. But by no means would I have considered myself anything more than a novice.
Armed with the knowledge that I had 6 months to buckle down and learn the material I signed up to present a DEVNET classroom session at CLUS, and create a couple of guided learning labs. Now this would be a much better story if I led the reader to believe that I couldn’t spell YANG when I started to create the content. In reality, I had a good understanding of what function NETCONF, RESTCONF and YANG provide. I could explain why one might use them in a network. What I didn’t have was a strong grasp of how someone would go about writing the corresponding code.
My starting point was the Network Programmability for Network Engineers learning labs on DEVNET. Specifically, I started with “Introduction to Device Level Interfaces.” The content was a perfect mix of instructional content mixed in with hands on labs. If you are just starting down the path of Network Programmability I highly suggest you start with the Learning Labs. While I’m very proud of the content of my recorded session at Cisco Live, the Learning Labs are a great resource. In fact, I may have ‘paraphrased’ some of the content. More on that later.
After building my foundation with the learning labs, it was time to get my hands dirty and start digging into some code. I don’t know about anyone else but I’ve always likened learning a programming language to learning a second language in high school. I found that I was able to read a second language much easier than I could write. To this day if someone says something to me in Spanish, provided they are speaking slowly, I can usually figure out what they are saying. My issue has always been formulating the words, so I reached out and asked someone for help.
In my case help came in the form of a couple of scripts written by a co-worker. The scripts weren’t anything overly complex. One pulled the hostname from a router. The other pulled interface statistics. By using a script for which I knew the expected output I could reverse engineer the code. More importantly I also had someone that I could practice ‘talking’ to when I tried to make code changes.
The last step to convincing Cisco Live of my expertise in writing code was the result of some bad planning. As a companion to my presentation I was asked to write some guided labs for the DevNet Zone workbench sessions. The labs were designed to use a virtual router running on the student’s laptop. Armed with my borrowed code, the students and I would walk through examples of using NETCONF to pull configuration details from the router. The students would also use Postman to get hands on experience using RESTCONF. My plan was flawless until I realized a week before Cisco Live that I still hadn’t found a way to get a startup configuration on the router.
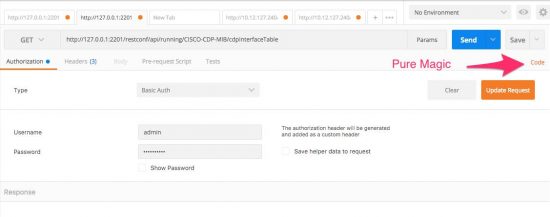
Facing a pending deadline I decided I was going to write a Python script that would provision 2 interfaces on the router. What I found is that while I could explain in a clear concise manner how NETCONF with a YANG data model could be used to accomplish this task, my attempt at a script resulted in more errors than a 100 Mbps half-duplex link. After wasting the better part of a day without success I gave up and went back to the drawing board. It was at this point I found the magic of RESTCONF and Postman.
Screenshot above shows how easy it is to convert API calls to code using Postman
Postman is an amazing open source tool for creating and sending REST calls to a device. In the lab the students would use the tool to create REST URIs to pull various interface statistics. The final step of the lab was to use Postman to modify an interface configuration. More importantly Postman has a built in function that allows you to convert any REST call to various programming languages. With Postman I could quickly create my interface configuration, test it with the tool and convert it to Python.
After that it was a simple process of tying 3-4 basic Python scripts with a bash executable and I’ve got a fully configured router without ever touching the CLI. It was at that point that I began feeling I should be on the billboard in front of Mandalay Bay, not Chris Angel.
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Welcome back to our blog post series exploring the intersection of neurology + mindfulness and innovation + entrepreneurship. In our previous post we set the stage for our exploration of how recent discoveries in neuroscience, along with centuries-old mindfulness practices, could shed light into the complex space of entrepreneurship and innovation. We highlighted six areas of interesting intersection. In this post, we explore the second and third of our intersections of interest.
Intersection No. 2: An unchecked ego is an obstacle to innovation.
A follow up to our first observation, “Innovation does not exist without failure,” is that a big ego can be a great obstacle to innovation. Those who have a big ego may fall in love with their idea too soon, because they might perceive it as an extension of themselves. Or as a proxy for their self-worth, something related to the process of identification with the self.
However, one of the core principles of Silicon Valley innovation is your initial idea is not as good as you think – and it’s probably worse than you believe. That’s why iteration is so important.
In fact, there are stories of major companies starting in a very different way than what made them successful. And it’s the founders’ abilities to pivot (technical term for turning aspects of your business around), which led them to success. This is particularly difficult if you have a big ego.
Someone with a big ego identification problem, who sees an idea as an extension of himself/herself, will put more effort into proving their idea right versus putting the energy into making the necessary adjustments. Mindfulness practice can help with the dis-identification process that would then allow the innovator to part ways with the initial idea effortlessly, evolving from a subjective (egocentric) perspective into an objective (mindful) one.
A robust mindfulness practice helps us have a rotation in consciousness from the egocentric perspective to a more objective clear seeing perspective. This is referred to in psychological literature as “re-perceiving” or “dis-identification.” This helps individuals understand that their value doesn’t come from their ideas being right (or from the innovations or ventures being successful, for that matter) but from being.
But is a large ego necessary for success? If so, why would I want to practice mindfulness to prevent my ego from getting in the way? There a couple of ways out of this conundrum. First, in some cases, successful entrepreneurs have needed to grow out of their egocentric ways—at least until they’re back at a level of functionality. And, in other cases, what matters (to quote Ash Maurya) is to, “Love the problem, not your solution.”
Intersection No. 3: If you can’t control your attention, you can’t innovate.
Innovation is challenging, requiring relentless focus. This is pursued in many ways by successful entrepreneurs—whether its’ Bezo’s day 1 or Google’s laser focus founding mission statement—there are plenty of examples of the importance of staying focused.
Harvard research shows that on average our minds wander 47 percent of the time. This poses interesting questions: Are successful innovators supposed to be successful being able to use their minds at will only 53 percent of the time? And, is that even desirable? Isn’t some mind wandering needed to have creative insights?
Let’s begin with the issue of percent of the time the mind wanders: We can train and stabilize our attention so the mind wanders less. Cultivating this laser like attention is essential, and a mindfulness practice is a great way to achieve this goal.
This takes us to the second point: Is all mind wandering undesirable? No, but we need to distinguish between involuntary mind wandering and deliberate mind wandering. The former usually takes place when the mind is being hijacked by ruminative anxious judgmental thoughts, which contribute nothing to innovation. The latter, however, happens when we deliberately, consciously choose to let our mind roam freely as we seek the solution to a challenge. Having the ability to choose when to let our minds roam freely–and when to focus on our tasks at hand is a crucial asset for innovators.
Entrepreneurs need to take this to the next level. They have the extra task of helping their teams focus their attention on what matters to the company. Daniel Goleman explains more.
Join us for our upcoming posts to explore our fourth and fifth intersections of neuroscience, mindfulness, entrepreneurship, and innovation:
What we practice grows stronger
We suffer when we resist what is
We would love to read and respond to your comments. Please post below.
Co-Author: Shauna Shapiro
Shauna is a professor, author, speaker, and internationally recognized expert in mindfulness. Dr. Shapiro has published over 150 journal articles and chapters, and coauthored the critically acclaimed texts, The Art and Science of Mindfulness, and Mindful Discipline. She was an invited TEDx speaker, her 2017 Talk has been rated one of the top 10 TED-talks on Mindfulness. With twenty years of meditation experience studying in Thailand, Nepal and in the West, Dr. Shapiro brings an embodied sense of mindfulness to her scientific work. Dr. Shapiro is the recipient of the American Council of Learned Societies teaching award, acknowledging her outstanding contributions to graduate education, as well as a Contemplative Practice Fellow of the Mind and Life Institute, co-founded by the Dalai Lama. Dr. Shapiro has been invited to present her work to the King of Thailand, the Danish government, and the World Council for Psychotherapy in Beijing, China, as well as to Fortune 100 Companies including Cisco Systems, Genentech and Google. Her work has been featured in Wired magazine, USA Today, Shape, Dr. Oz, the Huffington Post, Yoga Journal, and the American Psychologist.
In my last entry in this space, entitled Function-as-a-Service 101: What is it?, I introduced the concepts, players, and basic usage of Function-as-a-Service (FaaS). But how are people actually using it? Welcome to Function-as-a-Service 201: Common Architectures.
Back in December at AWS re:Invent, the definitive talk on this topic was led by AWS Solution Architects Drew Dennis and Maitreya Ranganth who brought along BMC R&D Architect Ajoy Kumar to discuss his specific use of the technology. The video of the session is about an hour long, but I’ll summarize the four patterns discussed from the slides, although I’ll cover them in an order from most to least likely used when getting started with serverless.
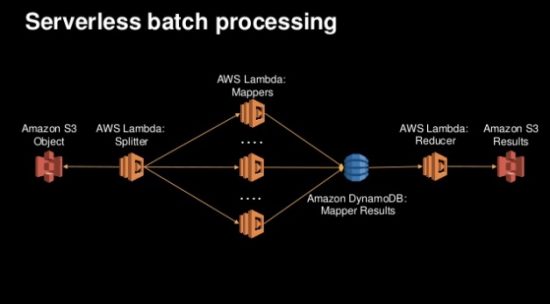
Pattern 1: Batch Processing
The simplest pattern, and the one that is the easiest to get started with without interrupting your main user interactions is Batch Processing:
The example shown here utilizes Lambda and the AWS events ecosystem to set up Map/Reduce processing that begins with files being placed in S3, has one Lambda function act as a splitter to as set of mappers, who all write their results to a DynamoDB, which in turn triggers a reducer to then put the final results in a separate S3 bucket. It is important to note that this is just one batch example and that any batch processing system can similarly be set up as a set of cascading events, most of which won’t be quite as complex as Map/Reduce. Getting started with serverless architectures by creating a simple Lambda function that processes some data and gets kicked off by the cron event capability in CloudWatch is a good, easy to understand learning exercise.
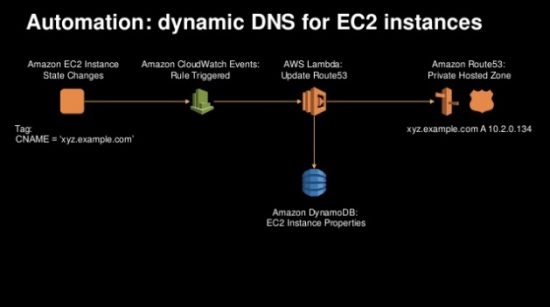
Pattern 2: Operations Automation
The next simplest pattern is to automate operations tasks that happen repeatedly whenever some specific resource is created or destroyed. The example given in the session automated the creation of a friendly DNS name for a newly launched EC2 instance:
Here, a CloudWatch event gets generated when the EC2 instance comes up, which triggers the launch of a Lambda function written to interact with Route 53 for DNS management and has the result captured in a DynamoDB table. Again, this is one example but the nanoservice approach that serverless functions provide makes it easy to bite off little pieces of operations like this so that they can get reliably executed through automation. Similar approaches using bash scripting in Linux environments has been used for decades, but here the advantage is that you have a set of built-in ecosystem triggers that can be used to trigger the execution of the function.
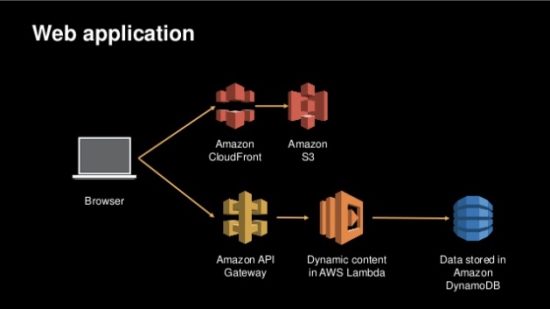
Pattern 3: 3-Tier Web Application
After cutting your teeth with implementations of the first two patterns, you’ll be ready for something more substantial and user-facing like a 3-tier Web Application:
Unlike the previous two examples, there is less variation in the use of this pattern. An S3 bucket is configured with static HTTP hosting for HTML, Javascript, and CSS files and cached using CloudFront. Once those files are loaded in a browser, the Javascript invokes individual REST API calls formed by putting API Gateway in front of individual Lambda functions backed by calls to DynamoDB tables. A Web Application constructed in this way might also make use of Cognito for authentication and IAM for authorization of the API Gateway calls, but a wide variety of mobile and browser-based applications can be quickly built using this pattern.
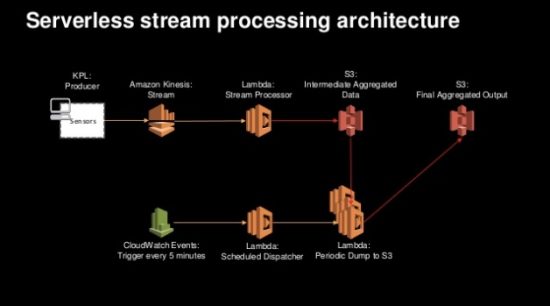
Pattern 4: Stream Processing
A slightly more complicated pattern for serverless that involves large amounts of data has to do with Stream Processing:
This final pattern uses on set of Lambda functions to take data off a Kinesis stream and quickly store it in an S3 bucket while a second set of Lambda functions gets kicked off by cron through CloudWatch to process the data and aggregate it to a separate S3 bucket. In this scenario, data coming off the Kinesis stream is happening frequently enough and at large enough volume that it doesn’t make sense to trigger a set of processing Lambda functions based on S3 put events. Instead, the cron timer instantiates the post-processing at regular intervals keeping the number of function invocations, and the overall cost of the solution given how Lambda is billed, down to a more reasonable and predictable number.
Summary & Next Time
From the examples given here, two things are clear about serverless application architectures. First, they involve more than just the FaaS runtime like Lambda but include other services like databases, loggers, and API front ends. The trick is figuring out how to use the event system to cascade a set of functions that holistically create a solution to whatever your problem is you are trying to solve.
Second, the learning curve is not insurmountable and can generate value as you overcome it. Playing around with batch and operational problems with serverless solutions is a great way to learn the ecosystem, its benefits, and its limitations.
Finally, for next time we’ll explore new frontiers where Cisco is contributing to the serverless community with a new class of product that enables developers to marry serverless concepts with Cisco routers and switches already pervasive throughout the buildings we all walk through every day.