
In my last entry in this space, entitled Function-as-a-Service 101: What is it?, I introduced the concepts, players, and basic usage of Function-as-a-Service (FaaS). But how are people actually using it? Welcome to Function-as-a-Service 201: Common Architectures.
Back in December at AWS re:Invent, the definitive talk on this topic was led by AWS Solution Architects Drew Dennis and Maitreya Ranganth who brought along BMC R&D Architect Ajoy Kumar to discuss his specific use of the technology. The video of the session is about an hour long, but I’ll summarize the four patterns discussed from the slides, although I’ll cover them in an order from most to least likely used when getting started with serverless.
Pattern 1: Batch Processing
The simplest pattern, and the one that is the easiest to get started with without interrupting your main user interactions is Batch Processing:
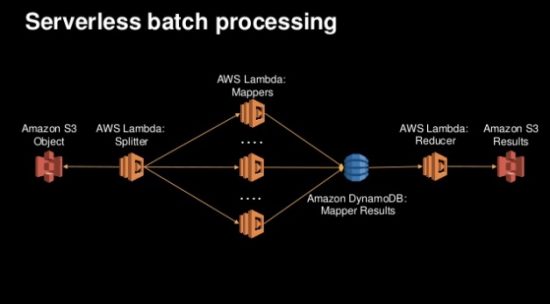
The example shown here utilizes Lambda and the AWS events ecosystem to set up Map/Reduce processing that begins with files being placed in S3, has one Lambda function act as a splitter to as set of mappers, who all write their results to a DynamoDB, which in turn triggers a reducer to then put the final results in a separate S3 bucket. It is important to note that this is just one batch example and that any batch processing system can similarly be set up as a set of cascading events, most of which won’t be quite as complex as Map/Reduce. Getting started with serverless architectures by creating a simple Lambda function that processes some data and gets kicked off by the cron event capability in CloudWatch is a good, easy to understand learning exercise.
Pattern 2: Operations Automation
The next simplest pattern is to automate operations tasks that happen repeatedly whenever some specific resource is created or destroyed. The example given in the session automated the creation of a friendly DNS name for a newly launched EC2 instance:
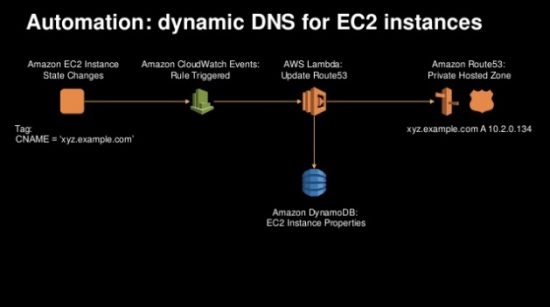
Here, a CloudWatch event gets generated when the EC2 instance comes up, which triggers the launch of a Lambda function written to interact with Route 53 for DNS management and has the result captured in a DynamoDB table. Again, this is one example but the nanoservice approach that serverless functions provide makes it easy to bite off little pieces of operations like this so that they can get reliably executed through automation. Similar approaches using bash scripting in Linux environments has been used for decades, but here the advantage is that you have a set of built-in ecosystem triggers that can be used to trigger the execution of the function.
Pattern 3: 3-Tier Web Application
After cutting your teeth with implementations of the first two patterns, you’ll be ready for something more substantial and user-facing like a 3-tier Web Application:
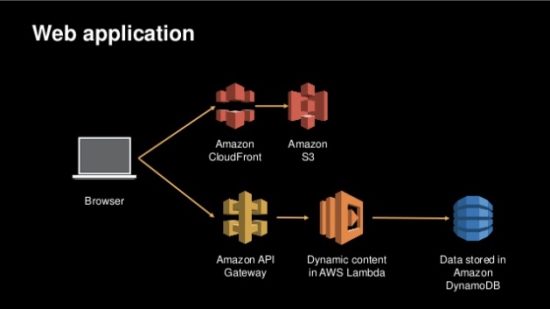
Unlike the previous two examples, there is less variation in the use of this pattern. An S3 bucket is configured with static HTTP hosting for HTML, Javascript, and CSS files and cached using CloudFront. Once those files are loaded in a browser, the Javascript invokes individual REST API calls formed by putting API Gateway in front of individual Lambda functions backed by calls to DynamoDB tables. A Web Application constructed in this way might also make use of Cognito for authentication and IAM for authorization of the API Gateway calls, but a wide variety of mobile and browser-based applications can be quickly built using this pattern.
Pattern 4: Stream Processing
A slightly more complicated pattern for serverless that involves large amounts of data has to do with Stream Processing:
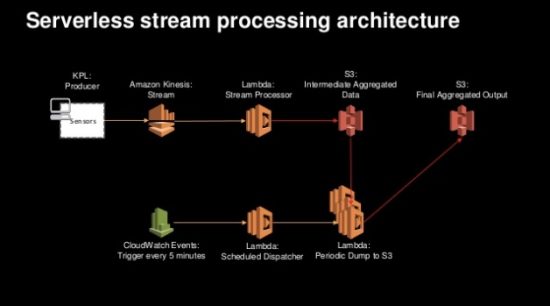
This final pattern uses on set of Lambda functions to take data off a Kinesis stream and quickly store it in an S3 bucket while a second set of Lambda functions gets kicked off by cron through CloudWatch to process the data and aggregate it to a separate S3 bucket. In this scenario, data coming off the Kinesis stream is happening frequently enough and at large enough volume that it doesn’t make sense to trigger a set of processing Lambda functions based on S3 put events. Instead, the cron timer instantiates the post-processing at regular intervals keeping the number of function invocations, and the overall cost of the solution given how Lambda is billed, down to a more reasonable and predictable number.
Summary & Next Time
From the examples given here, two things are clear about serverless application architectures. First, they involve more than just the FaaS runtime like Lambda but include other services like databases, loggers, and API front ends. The trick is figuring out how to use the event system to cascade a set of functions that holistically create a solution to whatever your problem is you are trying to solve.
Second, the learning curve is not insurmountable and can generate value as you overcome it. Playing around with batch and operational problems with serverless solutions is a great way to learn the ecosystem, its benefits, and its limitations.
Finally, for next time we’ll explore new frontiers where Cisco is contributing to the serverless community with a new class of product that enables developers to marry serverless concepts with Cisco routers and switches already pervasive throughout the buildings we all walk through every day.




