We are excited to announce the completely refreshed Cisco Enterprise Agreement (EA), passionately built from scratch for our customers.
Customers are telling us they want a simpler way to consume technology. They need to easily manage software, respond to consistent changes, and get the most value from their investment. For these reasons, we are introducing the Cisco Enterprise Agreement. Nothing like this has ever been done before at Cisco.
Every company is working on their digital transformation, which is about creating new customer experiences, transforming processes and business models, and empowering workforce efficiency and innovation. However, digital transformation requires a digital ready infrastructure that is built to enable networking, collaboration, and security. Fortunately, this is exactly what the Cisco Enterprise Agreement offers. With Cisco EA, customers can buy, deploy, and manage software in a single agreement across Cisco’s best in class portfolios for networking, collaboration, and security. For networking, we include our innovative Cisco ONE Software offers for data center, WAN, and access. For collaboration, get the latest and greatest software innovation like Spark for messaging, meetings, and calling. Lastly, secure everything with the most complete security portfolio in the industry for any email, web, and policy needs.
Our agreement has two key value propositions. The Cisco EA makes it simpler, and it delivers more value.
Here is how we make it simpler. First, the terms of this agreement are standardized on one contract for three or 5-years no matter what you purchase. Second, access to a single license management portal with a real-time consumption view is granted with the Cisco EA. Third, say goodbye to box-by-box contracts and instead get blanket, enterprise-wide and co-terminated service coverage. Fourth, Cisco infrastructure software includes license portability for flexible deployment across physical, virtual, and cloud. We completely refreshed the Cisco EA to remove complexity.
We also deliver more value. First, the Cisco EA includes a generous 20 percent growth allowance for additional software and services used during your multiyear term at no charge. Second, is our unique True-Forward process, a customer-friendly substitute for true ups that eliminates retroactive fees by only adjusting for overages in the next billing period. Third, enjoy investment protection as your existing software earns credit towards a Cisco EA. We deliver more value to make it easy to manage your growth.
Already, the Cisco Enterprise Agreement is gaining momentum with positive feedback from partners and over one hundred customers. To learn more, visit the following URLs.
With today’s announcement of the Cisco Enterprise Agreement (EA) we’re changing the way our customers purchase, deploy and adopt Cisco technology. This is another big step forward as we continue to evolve our software business strategy to make it simpler, easier and more rewarding for customers take advantage of Cisco software as they undergo the transformation to digital business.
The Cisco EA is a single, simple agreement that lets our customers easily consume the products and services they need today, in areas like collaboration, infrastructure and security, and to scale and add additional capabilities as they grow – simply and without penalty. The Cisco EA simplifies access to the latest Cisco products and services, and gives customers the ability to deploy and use products and services on their budget and schedule.
We’re always looking at ways to make it easier for customers to get the most value out of their Cisco software today and as they grow. Two years ago, we introduced Cisco ONE Software, a simple, flexible, more valuable way for customers to consume infrastructure software delivered through suites. Since then, more than 18,000 customers – including 98 of the Fortune 100 – have realized the benefits of Cisco ONE. 39% of Cisco ONE customers have already adopted new capabilities included in the suites, with another 50% planning to use new capabilities over time.
Cisco EA stacks up well against any enterprise agreement out there. But we didn’t introduce Cisco EA to be like everyone else. We’ve added important differentiators. We’ve built in a growth allowance, so customers can exceed their agreed upon entitlement amount up to 20 percent without additional cost. No one else does that.
Our True Forward feature is a game changer. Most vendors offer what they call “true up,” a periodic review of a customer’s software usage. If the customer is using more than the original entitlement, the vendor then bills the customer retroactively for the over-usage. That’s basically a penalty for success! We never back bill under True Forward. Cisco EA is designed to encourage our customers to grow not to penalize them. We want to see customers grow and win with us.
You’ve heard people say Cisco is becoming a software company, but that’s not accurate. We’ve always been a great hardware company. And software has always been a big part of our business. The Cisco EA is aligned with our strategy as we transform to become an increasingly software-centric company, transforming the way we make our software available to our customers. This puts us in a unique position as we leverage our leadership in both hardware and software, and in the capabilities only we can offer as both work together to deliver customer value.
I joined Cisco last year after 24 years at Microsoft, because I took a careful look at Cisco and saw tremendous opportunity. Cisco has an incredible portfolio, fantastic customer base and unparalleled experience and reputation in building the network, and a leader in collaboration and security. So now I’m excited to be part of our next stage as we emerge uniquely positioned as a global leader in both hardware and software.
We’re listening carefully to customers. At Cisco, we sometimes call this time of year “AB season,” because we do a series of targeted customer advisory boards. Along with dozens of other Cisco executives, I’ve been meeting with senior executives from our top customer and partner companies, learning about their businesses and what they need in an enterprise agreement. We’ve always known that customers want the most value for their IT investments and these meetings only confirmed that. We’re in the software business. We want to sell software. And we understand that the only way to do that is to create an environment in which customers can easily realize business value from their Cisco software purchases.
Cisco will continue to lead in the hardware business and software. I have no doubt about that. And Cisco EA will be a big part of it. I urge you to take a look at it.
Growing up in Britain, a fair share of our history lessons covered the black death. It was a truly horrible plague that affected all without prejudice, ravaging the young and old throughout towns, cities, countries and the continent with seemingly no end.
Surprisingly, it’s hard to remember everything from that class (hey, it was quite a while ago!), but one thing that does stick is how simple the path was to eliminating the disease: practising simple hygiene. Hygiene doesn’t necessarily kill every single pathogen, but it dramatically reduces the attack surface.
Today, hygiene is something we take for granted. We expect people to take reasonable care of themselves, whether at home, in a fast food restaurant, or on a plane. Hygiene is a good thing.
The Recent Plague: WannaCry
Security researchers are clear: WannaCry was not a particularly smart or advanced threat; it simply took advantage of an incredibly widespread exploit. It thrived because of a complete lack of data centre hygiene, allowing it to spread widely. The Cisco Talos team wrote an excellent and widely shared blog on WannaCry.
So, what’s data centre hygiene, you ask?
Much like human hygiene, it relates to two easily understood practices to protect yourself and others:
Stay clean, and keep your immunisations up to date.
In the data centre world, this is equivalent to keeping all (yes all!) of your servers up to date with every security patch.
Limit interaction with others to only what is necessary.
Limit interaction with others to only what is necessary.
It’s a simple statement. And a simple idea. But it’s hard to do.
Whitelisting is the data centre version of ‘limiting interaction with others to only what is necessary.’
The Australian Signals Directorate (the counterpart to the USA’s NSA) posted a field notice in April 2012 specifically instructing government entities to begin moving towards whitelisting.
In technical terms, it means that all communication is blocked by default and you must specifically enable communication to only those who are deemed necessary.
It is the data centre equivalent to your mum’s advice of ‘don’t talk to strangers.’
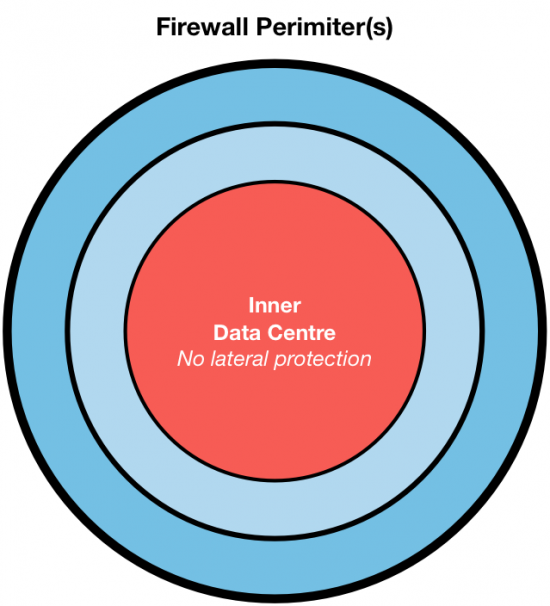
For many years, unfortunately, this advice has gone unheeded; a dangerous majority of data centres simply do not whitelist traffic. Usually network segmentation consists of a few boundaries, heroically guarded by firewalls, checking all whom enter or exit, but once inside the trusted zones, lateral movement is not controlled, save the limited isolation that VLANs and subnets provide (hint: it’s not much).
Perimeter security is traditionally given the lion’s share of attention. It’s effective, and easier than whitelisting. But it doesn’t solve every problem, leaving the inner data centre open for attack.
Whitelisting doesn’t replace your VLANs, subnets, and firewalls. We found the Cisco NGFWs were particularly effective at blocking WannaCry traffic. Bolstering one line of defence must not come at the expense of lowering your guard on another.
But whitelisting is hard…
It’s no secret – whitelisting can (and often will) break production applications if not performed with thorough care and attention. It’s the same reason why, even though Microsoft released a patch for WannaCry an entire month prior (the day of which the Cisco Talos team released detection signatures), so many were left unprotected: organisational inertia.
When presented with the very real choice of breaking business critical applications at the cost of improving security, the decision is often taken to continue operating as is, with the hope that we won’t be targeted and it will all just simply blow over.
Conventional wisdom. But what happens when the attack is indiscriminate and you end up as collateral damage?
So, back to why is it hard? First, what’s not hard: implementing whitelisting. There are many solutions on the market that promise to implement your whitelist for you, sold under many guises, the most common term being “micro-segmentation”.
Most solutions will do what you are looking for, save one incredibly important and oft overlooked point: they won’t help you derive what your whitelist should look like – that’s the really hard part. Without that knowledge, you are doomed from the start when implementing whitelisting.
Even the most advanced organisations simply cannot manually manage the complicated, interwoven set of dependencies that any real-world data centre application is a part of. Without that knowledge, you risk implementing incomplete or incorrect whitelists, which has the net effect of breaking the applications you intend to protect.
Analytics are here to save the day
By consuming huge amounts of detailed network and application telemetry, analytical tools can help you build that whitelist policy you so desperately need.
But what if you had access to an analytics platform that not only could understand and recommend your whitelisting, but could actually implement the whitelisting? By applying micro-segmentation in both the network and on your workloads, the platform constantly watches your network and applications, alerting you to out of policy behaviour. And it keeps track of every single conversation across your data centre 24/7, 365 days a year, for those times when you must know exactly what happened in the past.
The Cisco Tetration Analytics Platform
Cisco Tetration Analytics was built by a team of engineers dedicated to improving the hygiene of our customers’ data centres. We understand the real-world pressures and difficulties you face, and strive to provide you the knowledge and tools to transform and secure your data centre.
We don’t claim to hold a panacea for every threat you may face, but we do provide you with a simple and clear execution path to an infrastructure-agnostic, behavioural analytics-driven whitelist data centre, with the intent to help you rest well at night.
Sound interesting? Read on to find out how we can help you run an analytics-driven, secure data centre.
Before the attack – discover, enforce, harden
Whitelisting is not a reactive tool. You must begin the whitelisting on a sunny day, in preparation for the rainy day.
Tetration uses a combination of software agents and/or hardware sensors embedded in Nexus switches.
The software agent, a small lightweight piece of code installed on your workloads (e.g. bare metal servers, virtual machines, EC2 instances), uses no more than 3% CPU to gather detailed information about every single network packet exchanged by that workload, alongside related application context and behaviour as seen through the operating system. This data is streamed to your Tetration cluster over an encrypted link.
The hardware sensor captures meta-data from every packet passing through your switches to provide additional points that gather even more rich data, all of which the Tetration cluster artfully deduplicates, processes, compresses, and stores for your later retrieval via sub-second queries.
Different agent types help us monitor any type of data centre, on premises or in the cloud.
The goal: to capture a detailed record of every conversation in your data centre. Tetration is pervasive and always on, which is critical to application mapping and forensic analysis, and includes both traffic in and out of the data centre, and traffic between internal workloads at multi-terabit scale.
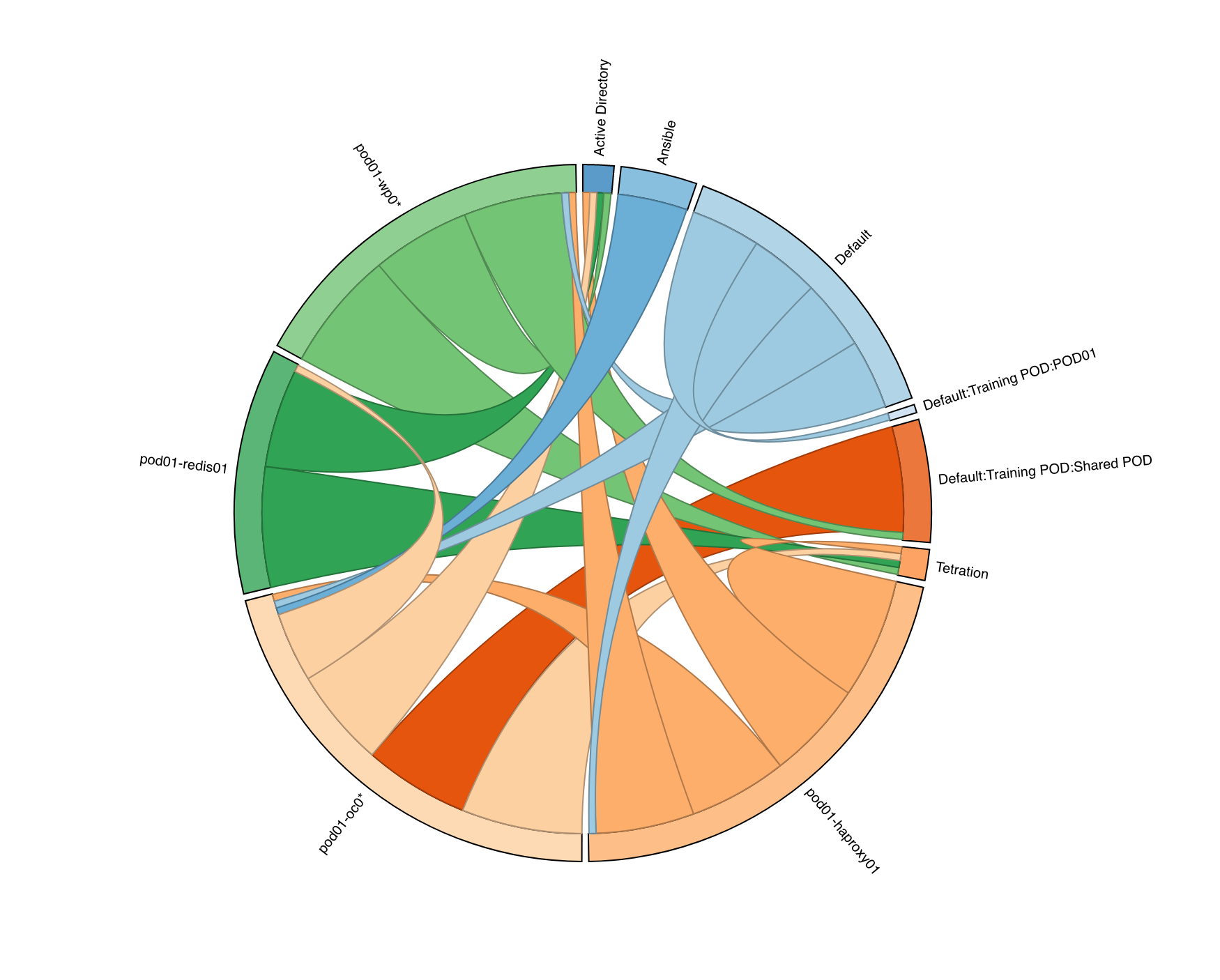
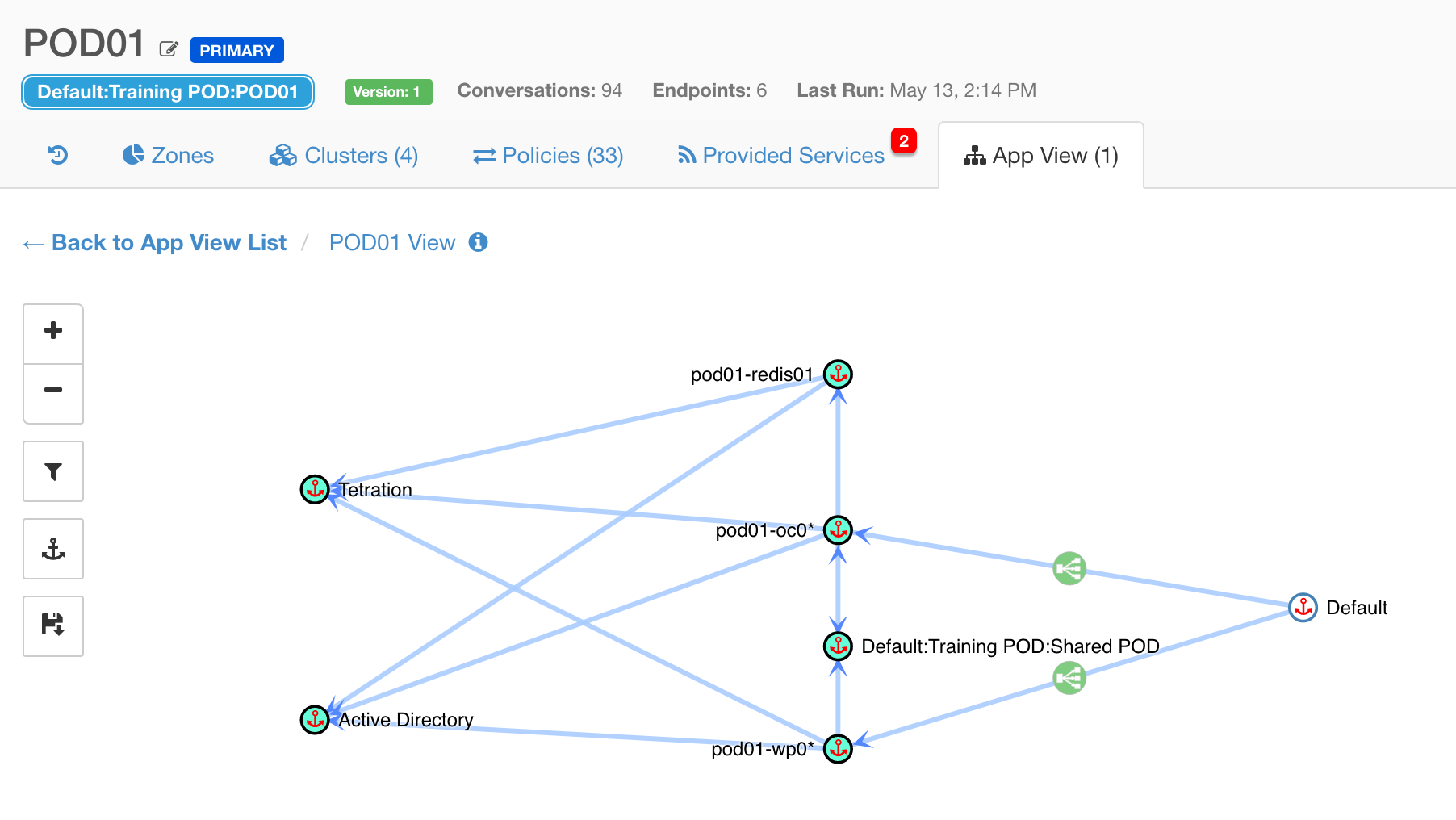
Based on the detailed conversation records and application information that tracks processes, arguments, and users, Tetration utilises behaviour driven, machine learning algorithms that automatically create a map of the applications in your data centre, how they connect together, and who should be talking to whom – even inside an application tier. It is, in essence, your whitelist.
Conversation diagrams show which tiers are talking and how much.
Application views help you understand how tiers are connected and what policies have been discovered
You can read more about the Application Insight capabilities of Tetration in this whitepaper.
After discovering your whitelist, the next step is to enforce it across your data centre. While the whitelist is exportable from Tetration in open formats, ready for use in Cisco ACI or other network devices, one of my favourite features is the ability to push the whitelist into the firewall of every workload in your environment, Linux or Windows, on premises or in the cloud using our agent.
This hardens your data centre to the point where only necessary interactions are carried out. Nothing more.
Click the green button.
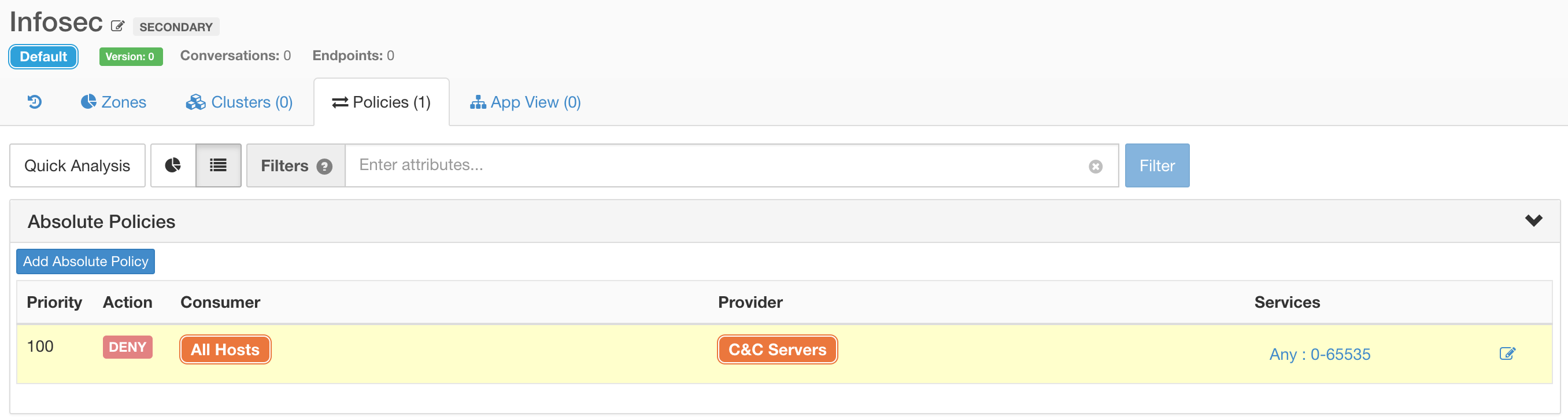
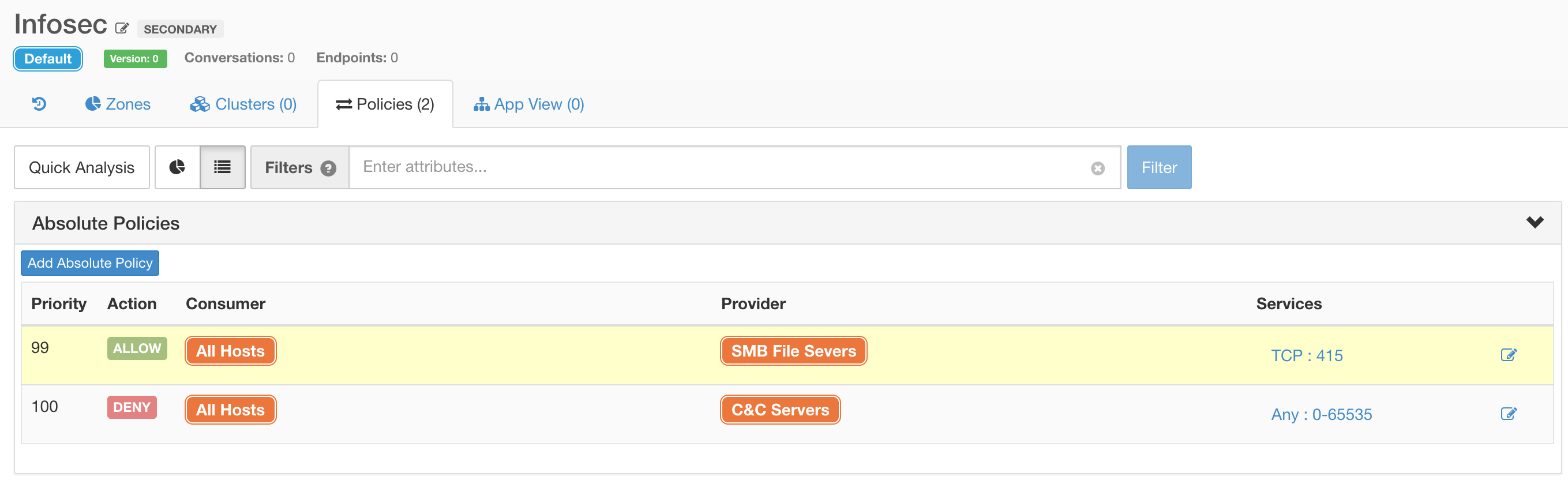
After automatically analysing your applications, you can overlay extra security policies that capture your intent, automatically translating that into the necessary firewall rules on workloads. Simple expressions like DENY communication from “All Hosts” to “WannaCry C&C Servers” can be captured and enforced across the entire data centre.
Or, for example ensuring that SMBv1 ports are blocked to all hosts that are not specifically designated as file servers.
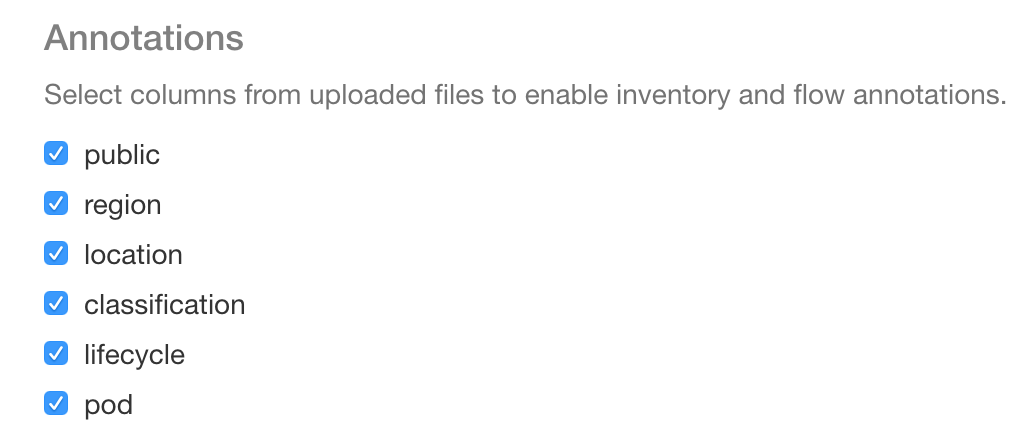
The Tetration platform can be easily taught new information about workloads, which in turn can be used to enhance whitelist policy, in the form of annotations for both internal and external entities via our Open API. External tools can be used to generate feeds streamed into Tetration as annotations, for example the Cisco Talos industry-respected security feed.
Annotations allow you to associate up to 32 custom key-value pairs to every workload.
During the attack – detect, block, defend
Well implemented whitelisting should help block the majority of incidents where malicious code spreads from machine to machine like wildfire, as the network traffic will simply not be allowed. If using Tetration enforcement, non-compliant traffic will be automatically blocked by the workload before it has the chance to touch the network.
Whitelisting is not the end-all for the gamut of attack types, and during an incident, it is vital to move swiftly with accurate information. Tetration monitors every single packet as it traverses your data centre network. If that packet is not in compliance with your whitelist, it is recorded, and alerts are generated alarming you to take action. Alerts can be streamed out to an Apache Kafka broker, allowing you to integrate Tetration with your SIEM, ticketing systems, or wider security toolset.
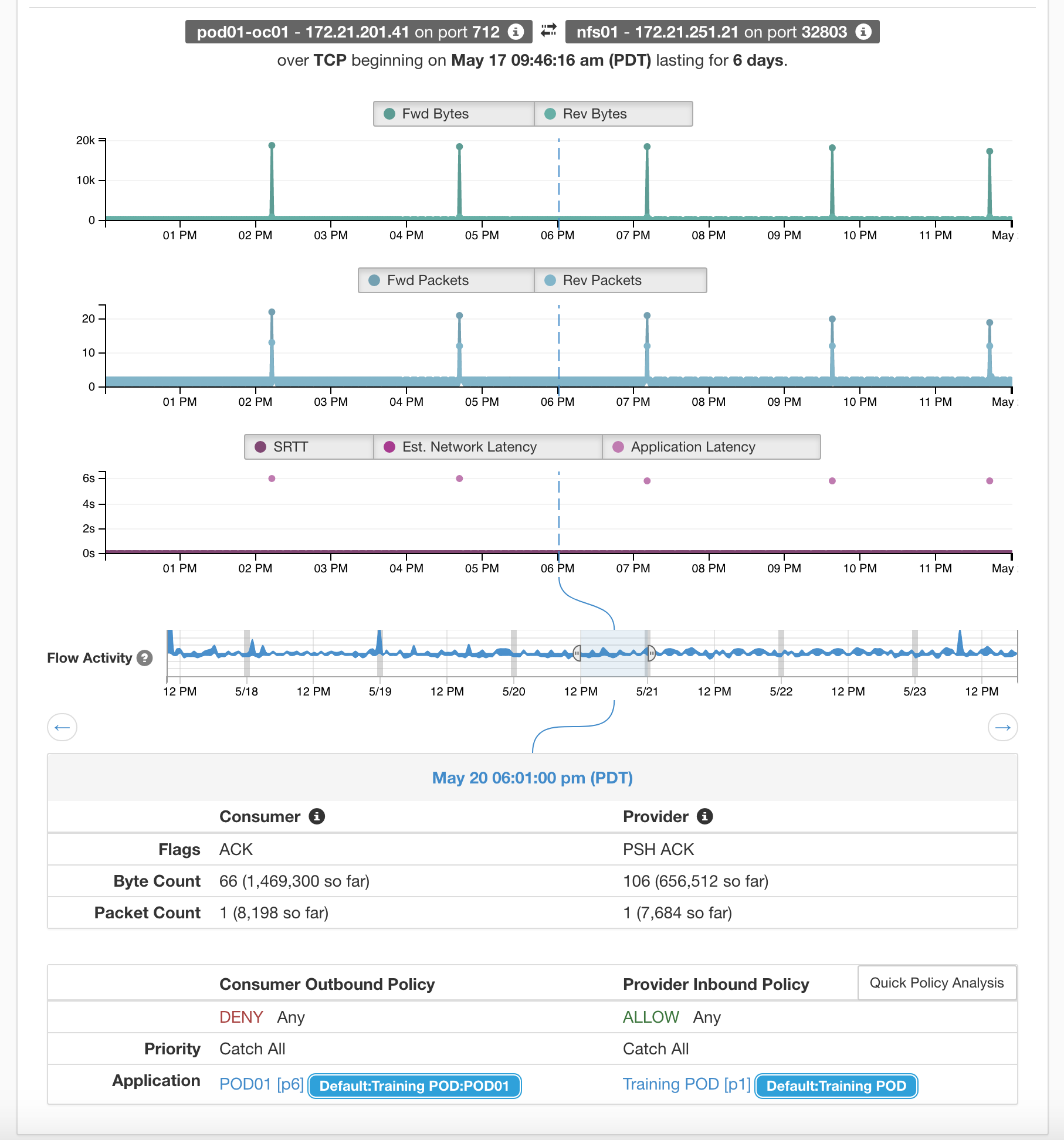
Tetration policy analysis can help you instantly track down who is generating non-compliant traffic, correlate it to your intent, and with a simple stroke of policy, compromised endpoints can be instantly isolated.
This conversation was marked as “escaped” because it was in direct violation of the client side policy
For more information on Tetration Policy Analysis please read this white paper
Post-incident, Tetration can quickly help you determine how far and wide the attack reached through the detailed record of each and every conversation. This entirely eliminates the need for guessing; the data is there, processed and ready for your analysis. Because of the always-on nature of Tetration, there is no rush to scramble to deploy network TAPs or SPANs to capture traffic.
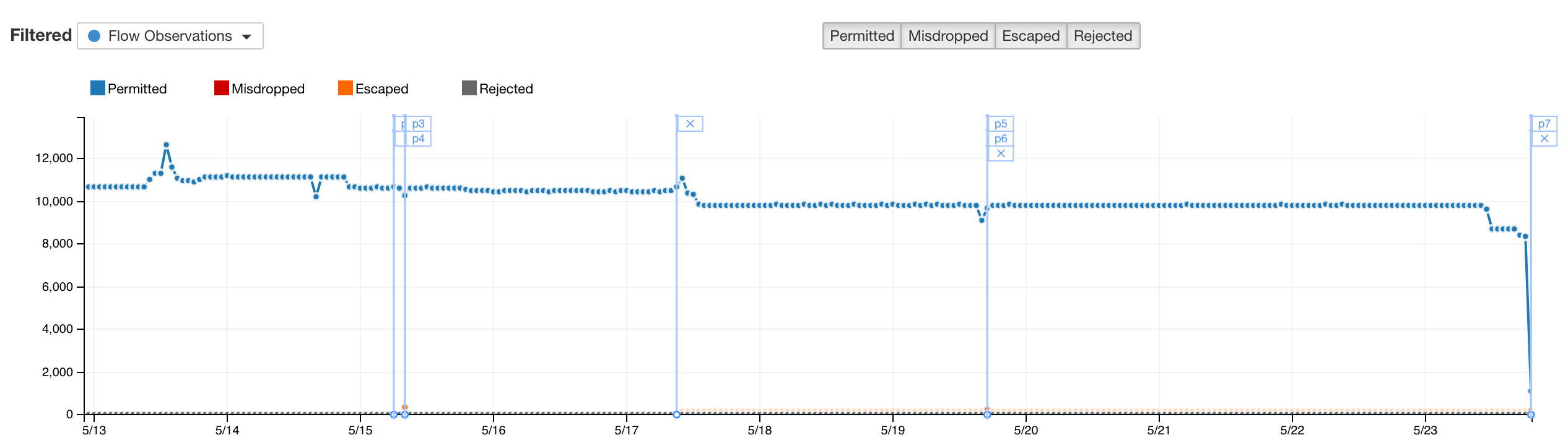
Complex queries that straddle both network and application attributes can be expressed and returned in sub-second time. For example, searching for SMBv1 traffic over the WannaCry period shows a significant spike in traffic volume.
Detailed analysis can be performed using Tetration Apps. A full featured Python and Scala environment accessed via Jupyter notebooks executed with access to the entire data lake, combined with the processing power of the Tetration cluster, allows for crawling through terabytes of data in minutes, and with forensic-grade resolution.
In short, no single solution on its own would detect and prevent WannaCry, but Tetration, along with other security products would dramatically reduce the risk by limiting the attack surface, as well as by dynamically updating the data centre security policies based on attributes and events.
Digital transformation is about technology. But, when it comes to creating sustainable smart cities, it is important to understand uniqueness, what makes the community tick and keeps people happily and proudly living there. Through the secure connectivity of digital transformation, cities and communities can become smarter and more connected, while also reinforcing and reflecting the city’s soul rather than submitting to impersonal or homogenized change. But, where do we begin? It is not a simple task to understand what will be valuable for our cities, the people that live there, and for the bottom line.
Digital city initiatives around the world can generate as much as $2.3 trillion over the next seven years. That’s a whole lot of opportunity afforded by digitally-charged transformation. We anticipate at least nine key areas that will drive these cost savings, build efficiencies like never before, and help to generate revenue for thriving communities. It is here, where smart cities and communities can kick-start the digital makeover that will benefit their residents, economies, environments, and fuel their soul.
https://www.youtube.com/watch?v=CLzX4bX3Ln4
Countries, cities, municipalities, schools, health facilities, and beyond are all shining brilliantly in every corner of the world with their digital success. Just as Kansas City and their CIO Bob Bennett know, truly smart and connected transformation begins with a solid network foundation.
Houston had a problem. Its fire department was responding to far too many ambulance calls that didn’t require acute or emergency care. By equipping its emergency responders with technology-enabled solutions, they are now eliminating the patients’ burden of emergency room visits by 80 percent, saving the city an estimated $928,000 annually, and allowing its workforce to operate more effectively.
Greater Copenhagen determined that only about 30 percent of its scheduled waste pickups were met with full garbage bins. Its SmartBin solutions use sensor-enabled waste collection when a bin reaches capacity, which cuts fuel costs and allows for more effective use of sanitation crews.
Through its Safe City initiative, Pune, India deployed more than 1200 video cameras along with a state-of-the-art command and control center. The city has been able to mitigate car thefts and other common crimes, while also speeding response times following events like traffic collisions and fires.
By using roadway sensor and video technologies, Stockholm has implemented congestion charging, decreasing traffic by 20 percent in designated areas, cutting toxic emissions by 2 to 3 percent, and increasing public transportation usage by 2 to 3 percent.
Tourist hot spots like New York City are deploying simple, interactive digital kiosks to provide informational things like directions, restaurant suggestions, and public transit schedules. These kiosks also function as a sensor to collect data about citywide conditions for things like air quality, public safety, and traffic status.
But, all of this could be fruitless effort if the network backbone is not secure. Comprehensive cybersecurity will be critical to the success and growth of digital initiatives, helping cities protect their investments and the products of their innovation. With a secure next-generation network in place, the opportunities to thrive are vast and continue to grow.
Each week, the Cisco team and some amazing smart city advocates will be posting here on Tuesday to bring you the latest. Stay tuned until then by:
Human Trafficking is one of the largest problems the world faces today. But My Choices Foundation, a nonprofit organization based in India, is using big data analytics to help fight it. How are they doing it? With technology partners, effective education and outreach.
While many organizations work to rescue girls and prosecute the traffickers, Operation Red Alert, a program of My Choices Foundation, is a prevention program designed to help parents, teachers, village leaders and children to understand how the traffickers work so they can block their efforts. Poor village girls are typically targeted by traffickers with promises that the girls are being offered wonderful opportunities for an education, jobs or marriage. But with over 600,000 villages in India, Operation Red Alert needed help to determine which areas were most at risk to prioritize their education efforts.
Check out this video that explains how My Choices Foundation took Big Data and helped make an impact by saving lives.
https://www.youtube.com/watch?v=wUUl_sqP31E
My Choices Foundation works with Quantium, an Australian analytics company that develops ground-breaking analytical applications that give insights into consumer needs, behaviors, and media consumption by analyzing consumer transaction data. Quantium used Cisco UCS hardware and MapR software to build this robust platform.
Quantium brings together proprietary data, technology and innovative data scientists to enable the development of ground-breaking analytical applications, and develops insights into consumer needs, behaviors, and media consumption by analyzing consumer transaction data. Quantium upgraded its legacy server platform with Cisco® UCS to gain centralized management and the computing power needed to process complex algorithms in a dense, scalable form factor that also reduces power consumption. Cisco Nexus® 9000 switches provide a simplified network with the scalable bandwidth to meet their current and future requirements. The MapR Converged Data Platform enables organizations to create intelligent applications that fully integrate analytics with operational processes in real time. The MapR Platform provides the multi-tenancy, high-speed performance and scale needed to power the Operation Red Alert data platform.
Rigorous testing by Quantium demonstrated that the MapR-Cisco platform decreased query processing time by 92 percent, a performance increase of 12.5 times the legacy platform. With the Cisco-MapR solution, Quantium’s data scientists can design complex queries that run against multi-terabyte data sets and get more accurate results in just minutes rather than hours or days. In addition, the more powerful platform drives innovation because scientists can shorten development time by testing alternative scenarios quickly and accurately.
“UCS gives us the agility that’s key to supporting our iterative approach to analytics,” said Simon Reid, Group Executive for Technology at Quantium. “For example, with the analytics for Operation Red Alert we’re fine-tuning the algorithm, adding more hypothesis and more granular data to improve our predictive capabilities. MapR adds performance security and the ability to segregate multiple data sets from multiple data partners for Operation Red Alert.”
Beers with Talos Episode 5 “It Has Been 0-days Since This Term was Abused” is now available. Beers with Talos offers a topical, fast-paced, and slightly irreverent take on cybersecurity issues. If you are an executive, a grizzled SOC vet, or a n00b, you will take something away from each episode. We won’t promise it’s anything good… but it’s something.
In this episode: Craig, Joel, Matt, Nigel and Mitch cover the potential of Samba echoing WannaCry and blocking SMB ports (but you already did that, RIGHT?). There is also some history lessons to give proper usage guidance on words like 0-days, backdoors, and other terms that the industry loves to hype and abuse for extra clicks.
You want to create an amazing, customer-first shopping experience. You also want to empower your associates to do their best work. The two goals may be related, but they are separate. To accomplish them both together, you need the right customer, associate, and business data — together with the right digital capabilities. If you’re wondering how to share more useful tools and information with associates, how to virtualize customer support and service, and how to gain automated processes, join our next Cisco Chat, “Associate Productivity in the Digital Age,” on Thursday, June 1st, at 10 a.m. PST.
In addition to myself, we’ll be joined by two retail experts in the Chat. Bill Zujewski (@BillZujewski), EVP of Marketing at Tulip Retail, and Susan Reda (@Susan_Reda), Editor of STORESMedia will be sharing their unique insights and perspectives. Together we’ll walk through the new landscape of retail in the digital age, and answer any questions you may bring as well.
To participate in the chat:
Make sure you’re logged into your Twitter account.
Search for the #CiscoChat hashtag and click on the Live tab.
The chat will be moderated by the Cisco Retail team on Twitter (@CiscoRetail). Be sure to follow this account to participate. The Cisco Retail team will begin welcoming guests at 10 a.m. PST (1 p.m. EST) and posting questions for discussion.
If you need multiple tweets to answer a question, please preface each tweet with “1A, 2A,” etc., in order to make it easier for others to follow the conversation.
Be sure to use the #CiscoChat hashtag at the end of each tweet so that others can find your contributions to the discussion.
Remember to bring your own questions to participate in the Chat. See you there!
Cisco to Demonstrate Full Duplex DOCSIS 3.1 (“FDX”)
By John Chapman, Cisco Fellow, CTO, Cable Access, Cisco
It occurred to me recently that it was in 1997 that the first DOCSIS-based cable modems first entered the market in a meaningful way. Five years ago, in 2012, we celebrated the 15-year birthday of DOCSIS (with cake, even!); this year, at age 20, I’m gratified and excited to share what I think is one of the biggest developments since the original DOCSIS 1.0 specification — if not the biggest.
I’m talking about a proof of concept demonstration we’re hosting with Intel in our booth at ANGA COM this week, of the first Full Duplex (abbreviated “FDX”) DOCSIS setup. It’s one of the biggest developments since the original DOCSIS because it positions the industry to achieve fiber-equivalent speeds — without replacing the “last mile” of coaxial plant.
It’s also big because it enables the upstream path to eventually achieve speeds of 5 Gbps! Today, four ATDMA carriers in the upstream provide about 100 Mbps of capacity. So this would be a 50x increase in upstream capacity! And this is done without removing spectrum from the downstream path. Instead, the spectrum is shared between the upstream and downstream paths.
Now. Let me level-set right here, right now: This is not a ‘this year’ thing. It’s not a next year thing. It’s probably not even a 2019 thing. FDX DOCSIS builds upon several other technology and business trends in the cable industry that are just starting to unfold:
The first trend is the deployment of DOCSIS 3.1 with OFDM. FDX DOCSIS is an extension to the DOCSIS 3.1 architecture and only works with OFDM/OFDMA channels.
The second trend is the deep fiber architecture that migrates the HFC plant from N+5 (optical node plus 5 amplifiers) to an N+0, passive plant architecture. FDX DOCSIS assumes a passive plant between the optical node and the CM.
The third trend is the use of Remote PHY technology where the CMTS PHY is placed in the node.
The fourth trend will be FDX DOCSIS that places an echo canceller in the Remote PHY node, which is located in an N+0 plant, along with more upstream channels.
With an all-DOCSIS downstream plant, and with DOCSIS 3.1, service providers can ultimately achieve speeds of 10 Gigabits per second in the downstream. Now, with FDX DOCSIS, the upstream can be extended to 5 Gbps. If a node were to contain one forward path and two reverse paths, then that optical node would have 10 Gbps capacity in both the downstream and upstream. This would match the 10 Gbps wavelength used to feed the digital optical node. This means that a 1×2 DOCSIS MAC domain with DOCSIS 3.1 and FDX would have symmetrical 10 Gbps capacity, and be equivalent to a fiber wavelength, and is a legitimate extension to fiber — without actually running fiber.
Why a proof of concept that “only” does 96 MHz symmetrical, when the end game is 576 MHz of shared spectrum? Because by necessity, proofs of concept must rely on current technology — and today’s cable modems “top out” at an upstream spectral location of 204 MHz. The 96 MHz shared spectrum in the demo will have a downstream rate of 890 Mbps (with 4K QAM) and an upstream rate of 680 Mbps (with 1K QAM). (Ultimately, we can expand the upstream return path from 42 MHz where it is now to a top frequency of 684 MHz, with a downstream start at 108 MHz, and no I’m not kidding — but that’s fodder for another blog.)
Here’s what you’ll see, should you be in Cologne at ANGA COM: a 96 MHz chunk of spectrum, located between 108 MHz and 204 MHz, with traffic moving simultaneously up and downstream. The intent is to show that a node can transmit and receive at the same time, on the same spectrum. This was heretofore impossible, because of the way amplifiers, taps, and diplex filters were “notched” to transmit, in one direction only at a given frequency.
Intel’s contribution (thanks again!) is its FPGA (Field Programmable Gate Array) silicon, valuable for its role in rapidly responding to marketplace developments — like FDX. Only a fully programmable, DOCSIS 3.1 Remote PHY system on chip (SoC) platform, connected across an HFC plant to Intel’s latest “Puma” cable modem silicon, enabled us to create the FDX demo. The Remote PHY Device (RPD) with FDX in the optical node is running OpenRPD open source software.
The magic of it is our (substantial) FDX work on echo cancellation. One way to envision this is to think about the noise-canceling headphones people tend to wear on airplanes. The headphones listen to the ambient noise of the plane, and create an inverse signal that cancels it out. In the case of FDX DOCSIS, what one modem transmits, the other sees as noise. An FDX echo canceller, like we’re demonstrating in Cologne, removes multiples of such “echos.”
Why is this happening? Ultimately, echo cancellation is an example of what can be achieved — when you have a whole lot of gates, and a whole lot of DSP horsepower.
FDX ultimately puts to rest — both logically and economically — the question of whether and when the time will come to sunset DOCSIS, and replace it with fiber to the premise.
The answer is probably never, because FDX creates what is essentially a fiber equivalent, throughput-wise, with coax. Moving 10 Gbps downstream, toward nodes, is already within reach; two upstream node ports running FDX yields 10 Gigs upstream. Why dig up yards to take fiber to the side of the house, when the bandwidth is already there?
I’ve been working on a new bundle of Cisco HyperFlex offered with Cisco CloudCenter. And I’m excited to share some details — because I’ve got that “Wow, this is a really great opportunity for Cisco customers” feeling, that I only sometimes get while working for a large tech vendor.
Together, these two powerful solutions help you take the next step with a hybrid IT strategy built on a HyperFlex infrastructure foundation. The HyperFlex with CloudCenter bundle is now offered at promotional price, with added incentives that fund implementation services for the offering. So now is a great time to take a look.
In this post, I’ll share 5 things you should know about this powerful combined solution.
1 – Cloud Experience Everywhere
Flexible and scalable infrastructure services are a key component of digital transformation and the foundation for Hybrid IT service delivery. But not if your infrastructure services are stuck behind a traditional help desk “ticket and wait” style service delivery front end, and a manual application deployment process back end.
HyperFlex with CloudCenter now delivers a cloud experience to users with a click button service – including deployment and management of VM or full application stack – without the cumbersome IT consumer experience of the past. Users get a drop-down menu that lets them pick the workload and choose where to deploy. And a simple tag-based policy engine provides guardrails that guide automation and user decisions as they work across both HyperFlex and public cloud environments.
With CloudCenter added to HyperFlex, you can make your agile and flexible hyper converged infrastructure services easy to consume, and give users the cloud experience they expect both on premises and in public cloud.
2 – Hybrid Cloud Scale
HyperFlex is known for its “Scale out” architecture that makes it easy to add compute and storage nodes, and easy to add resources to workloads within a node. But that can be limited to on premises infrastructure, and isolated from a hybrid IT service delivery strategy.
CloudCenter turns HyperFlex into what I call a hybrid “Scale out, Scale out” architecture. You still get HyperFlex legendary ease of adding compute and storage resources to “Scale out” on premises. But now it is also easy to “Scale out” by deploying workloads to the public cloud. Since CloudCenter architecture abstracts the underlying nuances of both vSphere on HyperFlex as well as your choice of public cloud, users can simply choose where to deploy workloads. IT can set policies that taps public cloud capacity on demand, on schedule, or based on compliance or security rules. You can optimize a changing mix of infrastructure utilization and your cloud bill.
HyperFlex with CloudCenter means that hybrid cloud isn’t a thing you have to build. It delivers an application-centric automation layer that spans on and off-premises environments.
3 – Easy Hybrid IT Entry Point
Many IT organizations are moving past initial public cloud efforts. But, are facing a wide range of technically feasible choices as they expand their hybrid IT strategy. Choice is good. But having so many options can also bring complexity. Both technical complexity with a broad mix of application types and deployment environments. And, operational complexity with multiple cloud and datacenter specific tool stacks and silos of expertise.
This solution extends the simplicity offered by HyperFlex.
This bundle is easy to order – There are 4x unique product IDs that package up our most popular HyperFlex configurations. You can choose from HyperFlex HX220c and HX240c with all flash or hybrid storage options. Pick the number of nodes with a minimum of 3 and maximum of 8. Pick a pair of fabric interconnect. Pick power cable appropriate for your country. Add memory or vSphere Enterprise licenses as options. And select software subscription duration – 1, 3 or 5 year. That’s it.
This bundle is easy to get started – The bundle is offered with a promotion that pays certified Enterprise Cloud Suite partners who are ready to install CloudCenter, set up public cloud, model a couple of application profiles for deployment, and bring users up to speed. You get started fast.
This bundle is easy to use – Users get single portal to deploy and manage workloads, in HyperFlex and Cloud, so they don’t need to learn multiple environment specific tools, or develop deep cloud API expertise. Users can share standard services or build their own. IT can easily create tags and link to policies that guide who can do what, where, when and for how long.
HyperFlex with CloudCenter offers a low impact way to evolve your cloud strategy without turning your IT organization inside out. And while preserving investments in your infrastructure.
4 – Full featured
HyperFlex with CloudCenter includes all CloudCenter features. This is not a limited use version that is restricted to some sub-set of features. Or, limited to use just on premises. HyperFlex with CloudCenter supports all CloudCenter use cases that help deliver business value on HyperFlex infrastructure investment.
HyperFlex with CloudCenter has everything you need now, and has governance, security, multi-tenancy, cost controls and reporting — and everything you will need as your hybrid cloud strategy evolves over time.
5 – Limited Time Promotion
This bundle is offered at special adjusted list price for both HyperFlex and CloudCenter components. Category and partner discounts apply from there.
For those looking to explore CloudCenter added to their HyperFlex environment, the bundle price for HyperFlex with 1 year CloudCenter subscription – is roughly same price as HyperFlex alone. This is a low risk “buy and try” opportunity.
For those who already see the value of CloudCenter, this is a great opportunity to get a 3 or 5 year subscription and additional VMs at a really great price.
The bundle is enhanced with partner services used to deploy CloudCenter and accelerate time to value. Certified ECS Integrator partners are funded by ECS adoption incentive for CloudCenter installation.
If you are looking for an easy hybrid IT entry point, or wanting a more agile consumption model for your hyperconverged infrastructure – right now is the best time to ask your Cisco or Partner sales contact about HyperFlex with CloudCenter.