June 20th 2017.
Months of preparation had lead to this day. Trucks rolled in at 8 am and began unloading all of our gear, an entire 18 wheelers worth. Things were looking good. By 9 am we had our racks offloaded and ready to be installed. What could go wrong right?
Unfortunately for us, one of the many challenges of setting up a temporary network is dealing with the unpredictable nature of everything outside of that scope. In this particular case it was dealing with delays in the truss installation. Because of the delay and the fact that truss needed to be installed right above where the racks were supposed to be installed, we could not uncrate our gear to be positioned and powered on until the truss install was completed. As the morning carried on, minutes turned to hours before finally at about 1 pm we rolled out our racks from the crates, cabled everything up and powered them on.


Now 4 hours may not seem like a lot of delay but when you only have 3 days to get the entire network ready for 28,000 people, every minute counts.
Shortly after we got all the racks powered on we were then faced with the issue that – even though the truss install was complete – they still had to install a large lighting fixture onto the truss which meant that there were tons of AV workers clustered around the area where we were also trying to work.

At this point we could not wait any longer so the team then split up to check on their respective technologies; checking all of the gear to make sure everything was online and functioning correctly. While the rest of the team worked diligently to ensure functionality, a few of my other teammates and I started working on patching in the distributions.
Getting the distributions online sounds easier than it was. We had three distributions, one each at the Mandalay Bay, MGM and Bellagio. Mandalay Bay had four links while MGM and Bellagio had two links each. The Mandalay Bay links were easy since it was all local, but we sure did have trouble with the some of the other ones. Tracking down where the issue lay was not easy given the number of patches and cassettes/MPO connections between the switches. We used a 5mW 650nm red laser fiber optic visual fault tester to ensure fiber connectivity was good. Even after testing each connection it still wouldn’t work for a couple of links. We ended up cleaning as many fiber ends as we could to finally get them working. We honestly had to use a super scientific method of blowing on the connector and plugging it back in to get it working for one link!!
After looking at how much trouble we went through we had our NOC Automation expert, Jason Davis, create a custom dashboard to monitor Optical Light levels.
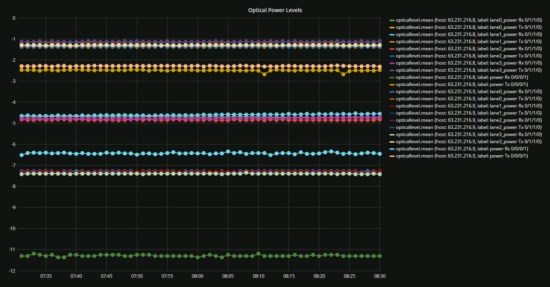
I was feeling better now, distributions were online, internet was up (except when the firewall guy took it down for 30 minutes!), we were in a good place. Except when we came in the next day only to find that the guys laying the carpet unplugged the power to an entire DC rack!! That’s right they took down the DC distribution by unplugging not one but two PDU’s. The good news is that we no longer needed to test failover of the DC, someone did that for us and it was a success.
The rest of the days were spent in testing and fine tuning configuration while at the same time getting the access layer online. As to be expected when deploying 500 switches, there were a lot of vlan changes and a lot of port reconfigurations. This year we had a member of the team looking at logs almost full time. Aside from a whole lot of bpduguard errdisables we caught CPU spikes, power supply failures and some interface flaps. We automated part of this process by having a message sent to a spark room each time we saw an errdisable message or when a port change was made. This really helped automate and speed up the process of recovery.

Considering all the testing and troubleshooting we had to do, you would be right in guessing we spent a lot of time sitting at our desks staring at our computers. Normally this wouldn’t be an issue except that it was freezing cold. You heard me right! cold in Las Vegas. A whole lot of us ended up buying sweatshirts at the Cisco store. That’s definitely a lesson learned for next time, we need space heaters!

Lastly but most importantly, the most essential item for surviving the NOC at CLUS is…