It’s our pleasure to announce the public availability of GOSINT – the open source intelligence gathering and processing framework. GOSINT allows a security analyst to collect and standardize structured and unstructured threat intelligence. Applying threat intelligence to security operations enriches alert data with additional confidence, context, and co-occurrence. This means that you are applying research from third parties to your event data to identify similar, or identical, indicators of malicious behavior.
There is already so much open source [threat] intelligence (OSINT) available on the web, but no easy way to collect and filter through it to find useful info. GOSINT aggregates, validates, and sanitizes indicators for consumption by other tools like CRITs, MISP, or directly into log management systems or SIEM. While the threat intelligence sharing community matures, GOSINT will adapt to support additional export formats and indicator sharing protocols.
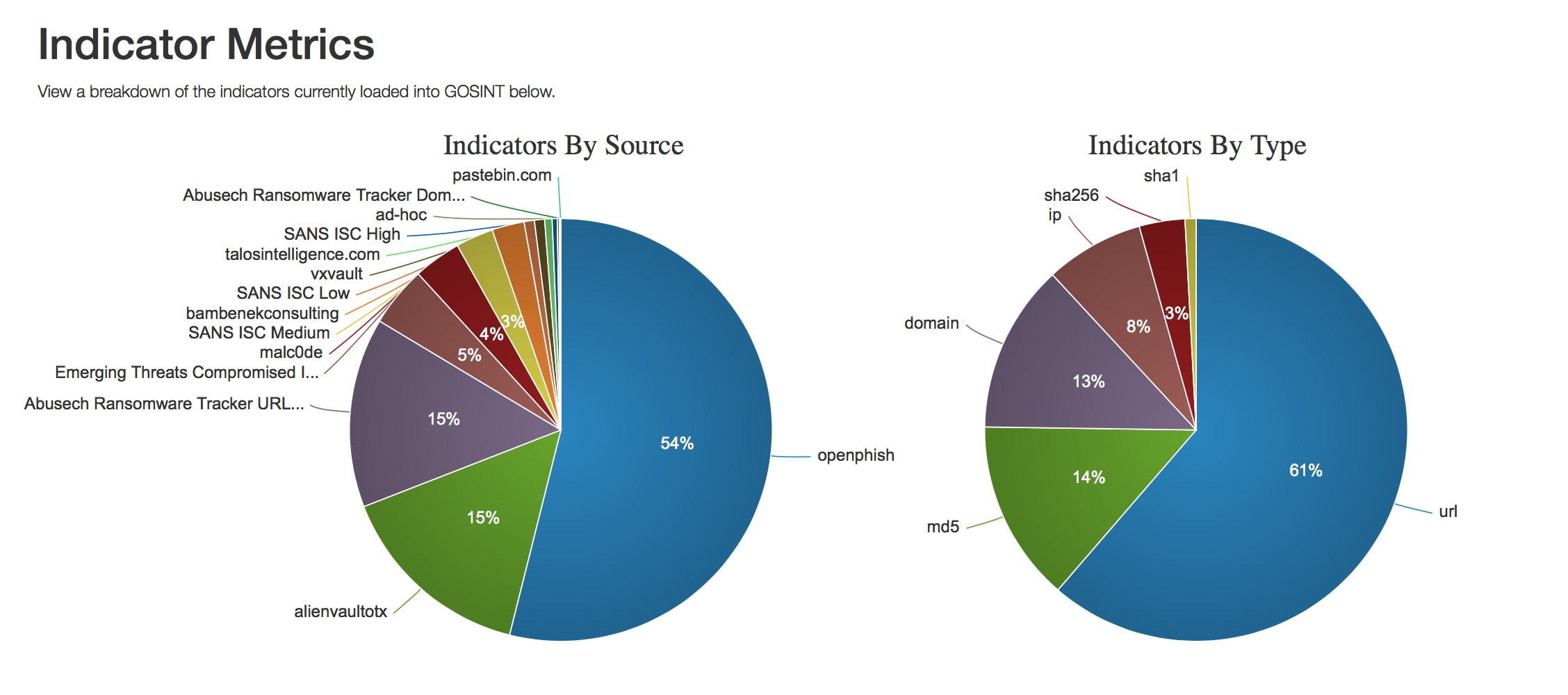
You can think of GOSINT as a transfer station for threat indicators. The software allows threat intelligence analysts to judge whether an indicator is worthy of tracking or if it should be rejected. This decision making step is crucial in managing any set of threat indicators. Vetting by both a human analyst and GOSINT itself improves the quality of indicators threat detection efficacy. There is no limit to the number of indicator sources you can add.
We have realized a lot of value in many open source feeds as well as looking at Twitter via its API along with Cisco Umbrella, VirusTotal, and others.
As part of the vetting process, currently GOSINT can take several actions to provide additional context to indicators in the pre-processing phase. An analyst can run indicators through Cisco Umbrella, ThreatCrowd, VirusTotal, and other sources. The information returned from these services can help an analyst reach a verdict on the value of the indicator, as well as tag the indicator with additional context that might be used later on in the analysis pipeline.
There is also a “Recipe Manager” that allows you to perform multiple operations on threat indicators from various sources. Say for example you want to always compare sha256 hash values from a favorite twitter feed with the VirusTotal API, and if there’s greater than 3 detections, add the hash indicators to production. The manager offers several configurable options to allow analysts to speed up their indicator processing and enriching.

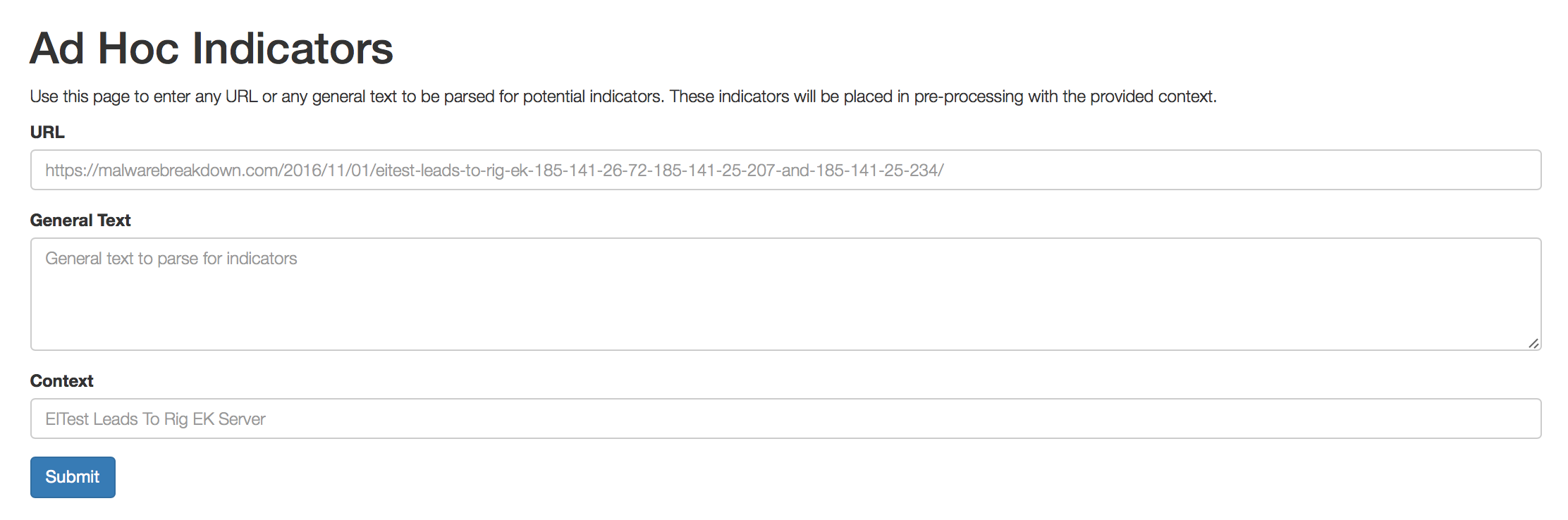
GOSINT also has another useful feature with its “Ad Hoc Input” option. This allows an analyst to point GOSINT at a URL and fetch any or all indicators available. For example, if an analyst reads a blog about a particular malware campaign or malware analysis, GOSINT can crawl the blog for indicators and import them for pre-processing. This ad-hoc method allows analysts to quickly import indicators from content that cannot be automatically subscribed to, or has intermittent data available.
If you work with threat indicators on a regular basis you should check out GOSINT today. Our CSIRT team has already seen value in importing these additional feeds into our analysis pipeline and GOSINT has been valuable in detecting the very latest threat indicators before they become stale.


 The DevNet team with Chuck Robbins at Cisco Live 2017 in Las Vegas
The DevNet team with Chuck Robbins at Cisco Live 2017 in Las Vegas