We call it our Virtualized Video Processor, or “V2P”. Shaw Communications gave it a much more consumer-friendly name — “Free Range TV,” which launched during this year’s Consumer Electronics Show. In this video interview, Cisco VP of Product Management, Jeff Seebeck discusses the over-arching design elements that made our V2P a core building block at one of our favorite Canadian operators. Bottom line: it’s cloud-based and rife with APIs, for service agility. Its open, for a broader development base. And, it now comes with two new elements: Cloud Object Storage, important for the surge in video-centric apps, cloud DVR, and archiving; and a Media Distribution Platform for CDN-centric operations. If your TV everywhere design goals include obviating hardware costs through virtualization, getting to market more quickly with more services, and adding the kinds of IP-based services that introduce additional revenue generating possibilities, V2P is the answer!
Earlier this week, Cisco received some welcome news. The U.S Patent and Trademark Office has rejected Arista’s second attempt to invalidate a Cisco patent that was asserted in the ‘945 International Trade Commission (ITC) investigation. This is also a patent where the ITC staff recommended a finding of infringement.
We are now looking forward to early March and the public release of detailed rulings in the first ITC case (‘944). We expect the release of two key documents:
Final Determination – a 294-page document providing the detail and reasoning behind the Judge’s decision that Arista violated three Cisco patents.
Recommended Determination of Remedy & Bonding – a 13-page document providing details of the exclusion order, and cease and desist order recommended by the Judge.
Both companies have had the opportunity to propose redactions to these detailed rulings that will protect confidential third party and company information. Our focus has been transparency, and we have requested the redaction of only five sentences of our confidential technical information from the entire 294-page ruling. We believe that the remaining information will help Arista’s customers, partners, and suppliers understand the true extent of their copying.
As I noted in my last blog, Arista’s time is running out. We expect the new documents to detail the categories of Arista products that will be prohibited from being imported into the United States. And in an important point for supply chain professionals, we also expect confirmation that the exclusion order bans the importation of both infringing products and the components required to make those products, as was indicated in the brief determination published on February 2. Arista could attempt to reconfigure their supply chain and seek a local contract manufacturer to make infringing products using imported components. But this strategy would be inducing a breach of the ITC order, and make their manufacturer a willful infringer of Cisco’s intellectual property. We will continue to take the action needed to protect our innovation.
So what happens next? The full Commission should decide whether to review some or all of the case by April 4. If they choose to review the ruling, their decision would be expected around June 2. After that comes a Presidential Review – a process that resulted in only one reversal in the last 30 years. If the original ruling is confirmed, August 2 is the likely date for implementation of the import ban.
Arista’s time and available options are fast running out. We call on them to remove their infringing products from the market, or submit their claimed workarounds for ITC approval.
Here we are, at the verge of what is the 30thMobile World Congress, in Barcelona. It’s a show I tend to characterize as “the water cooler for telecom,” because everybody is there! Over its impressive and storied history, starting in London in 1987, MWC has consistently served up the “firsts” that ultimately become everyday realities, and indeed necessities — the first mobile phone call, for instance. The first text message, the first tablet, the first app store — even the first tweet — all happened at a Mobile World Congress.
And while we’ve been participating in Barcelona for many years now, this year is a kind of first for Cisco, too — in that it’s the first time we’re bringing our full complement of equipment and services, spanning mobile, fixed mobile, cable, satellite, and over-the-top (OTT). The fact of the matter is that all of our customers go to MWC. And as a result, it’s become our biggest show of the year.
In this kickoff video for our new “Digi-Know” video series, Cisco’s Senior Director of Cloud Solutions, Rajeev Raman, discusses the shift of streaming video from a “interesting, let’s dabble” mindset to a “it’s ON, this is real” intention amongst service providers and content owners. Rajeev, whom we were (very!) fortunate to onboard from our recent acquisition of his company, 1Mainstream, is a recognized expert in the field of multiscreen video delivery. In his view, the reach of broadband into 80+% of U.S. households, and of streaming devices in 40+ million U.S. households signifies a “game on” environment — which simultaneously ups the ante for necessary service/feature inclusions, like Title 6 video and associated regulatory requirements, as well as parental controls, and cloud-based DVR, to name a few. Also in this video clip: Rajeev’s views on 4K video. (Hint: It’s not just for televisions anymore…)
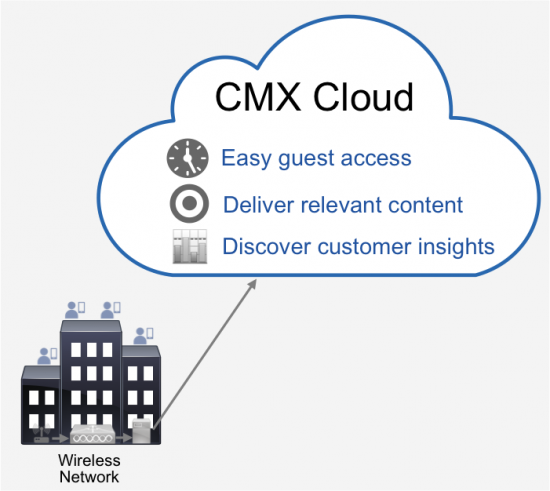
If you are a Business to Consumer (B2C) enterprise, you want to know more about the visitors in your venue, how long they stay and what they do in the venue. These insights can help you create more relevant customer engagements, maximize promotional activities, as well as optimize venue operations.
Cisco Connected Mobile Experiences (CMX) Cloud is a new cloud-delivered Software-as-a-Service (SaaS) offer. It delivers these customer insights and experiences in a matter of minutes, with the simplicity, flexibility, and affordability provided in a cloud solution. Simply point your Wireless LAN controller based on-premises network to the cloud to get started.
CMX Cloud is built upon the same CMX platform that has been available as an on-premises solution and has been very effective for improving guest experiences and building insights. This business need is equally critical across nearly all industry verticals, regardless of the size of your organization. Many Cisco customers have looked to CMX to address this need across retail, hospitality, healthcare, education, and more. Check out additional CMX Case studies here.
The Cisco Digital Ceiling unleashes the power of the IoT by linking building services over a single, converged IP network. It transforms the unobtrusive infrastructure in ceilings across your facilities into a secure, distributed, and standards-based architecture that delivers building intelligence at the edge of the network. The result is a building that is not only smart, but also is seamlessly and securely connected. With the Cisco Digital Ceiling, you can improve the efficiency and sustainability of your buildings and manage them more effectively. You can use the same platform to deliver highly personalized user experiences that improve the productivity, safety, and comfort of building occupants.
In my previous February 2015 blog post, I reviewed a new plugin for the OpenStack Neutron service plugin environment enabling customers to leverage the hardware platform ASR 1000. At that point the plugin was based on the Icehouse OpenStack version with limited feature support. Over the last several months we have been continuing the work on later OpenStack versions and introduced several new features.
Before we go into further details on these new features let’s go over the basics of the plugin and the limitations it tries to solve. When we introduced the ASR plugin for Icehouse, we were addressing the following limitations with the reference OpenStack software L3 implementation.. In such deployments, Layer 3 functionality is realized with a linux namespace router on the network node (may that be Neutron or the older nova network services). The default reference implementation is based on IPTables, which has certain limitations when it comes to Layer 3 entries (both routing and IP translations). For a typical deployment this limitation is around 10000 entries.
With the dynamic, scalable and on-demand requirements of larger cloud environments these limitations are easily hit when running an OpenStack based cloud. With these limitations in mind we developed an OpenStack plugin to support the Aggregation Services Router (or short ASR1000). The ASR1000 offers scale numbers well beyond those of software based IPTables (for further details on the scale numbers refer to the ASR1000 data sheet. By solving this one limitation we introduced several other advantages to a cloud environment a software router couldn’t offer. The ASR1000 is configured in a redundant pair offering First Hop Redundancy Protocol (FHRP) support, here we leverage the Hot-Standby Redundancy Protocol (HSRP) In addition to the resiliency advantage, the ASR1000 also provides a modular approach to offering hardware scale. Not only do we now have redundancy for the VMs gateway but also for the hardware that is used (multiple route processors, multiple forwarding engines and multiple 10G interfaces for port-channels).
For the Liberty release version of this plugin, we introduced some critical new features that enrich the ASR1000 plugin and offer more flexibility and deployment options for scalable and reliable OpenStack clouds.
These features include Heartbeat, Multi-region and cfg-agent HA support. Below a brief overview of the different features.
Hearbeat introduces a way to handle both ASR1000 hardware and cfg-agent failures. A sync mechanism is used to continuously verify the ASR1000 is still available and responding. In case of a failure, the config agent maintains a state that is continuously updated between Unknown, Active or Dead. This feature is used to assure that the ASRs are always configured correctly even after a failure.
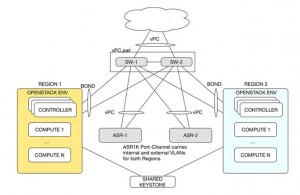
A Multi-Region OpenStack environment consists of multiple, often geographically apart, OpenStack entities managed by the same Keystone service. The ASR1K plugin provides a way to share L3 capabilities across regions while leveraging independent neutron services.
Many OpenStack environments are designed with high-availability in mind. The ASR1K platform and the plugin offer many different HA capabilities, amongst the newly added support for cfg_agent HA in a controller HA environment. Here, each controller is running its own agent in a Active/Hot-Standby manner. One Agent is responsible for the configuration of one ASR1K endpoint. In case of a failure of one of the agents, the endpoint gets rescheduled onto a different agent in the controller HA cluster.
We will highlight these in a solution like environment in an upcoming blog post. For more information feel free to reach out to openstack-asr1k-plugin@cisco.com.
Last summer, the BB&T Center and Florida Panthers hosted the 2015 NHL Draft. It was a great success and I am proud to work with such a great operations team. On the surface it looks like any other event, but there were a number of unique challenges that our IT group had to meet.
To make the challenge even more exciting, the weekend before the event, the arena was rented for a private event, so load in could not begin until the Monday of that week. All tables, switches, Wi-Fi access points, and cabling all had to be ready, but staged out of sight. Everything had to be ready for Thursday of that week for an internationally televised live event.
To accomplish this, we prepared 30,000 feet of Ethernet cable, 13 additional Cisco 2960-X stackable switches, and added 94 access points in a mix of temporary and permanent installations. 60 temporary Cisco phones were added on the floor ( two per team ) plus another 30 phones scattered around for NHL and media/broadcaster use. Our Internet edge router was upgraded from a 7206-G1 to a pair of new ISR 4431.
Throughout this week the discussion has been focused on the necessity of a programmable infrastructure and the Mantl project. Mantl was formulated to deliver application level flexibility by providing a set of pluggable components. One of the main use cases for enterprises is data management and analytics. This post discusses a subset of these components that are, arguably, the most important. This post will be talking about data platform and state.
What is the ELK stack?
Microservices are often idealized to be stateless. Stateless applications can happily fail and be restarted. Stateless applications can be scaled. But stateless applications don’t do anything interesting. Imagine a world full of stateless applications; no email, no google. Only static websites full of cat memes. Instead, the vast majority of applications require some state, usually in the form of a database.
The ELK stack is an offering from Elastic which includes the database Elasticsearch (ES), the Extract-Transform-Load tool Logstash (LS) a
nd the dashboarding application Kibana. ES is a general purpose NoSQL document datastore, which is easy to use and is highly scalable. The ELK stack is provided as a part of Mantl. This means the user is able to plug in the ELK stack and start using a distributed, scalable, resilient database, out of the box
What is Apache Mesos?
Mantl is operationally based upon Apache Mesos. Mesos has been discussed a number of times elsewhere, but here is a summary. Mesos is a resource abstraction layer. Applications request resources and these are placed upon a Mesos cluster. The key benefit is that it provides both scalability and resiliency. If more resource is required, add another node to the cluster. If one of the machines fail, the applications will be reallocated to different hosts.
So how is the Mantl ELK stack different from the normal ELK stack?
Fundamentally, the goal of the ELK stack on Mesos is to provide the same functionality as the official stack. The difference is that the Mantl version has been developed as a Mesos framework.
Mesos frameworks implement the core functionality of Mesos. They are responsible for scheduling work on the Mesos nodes, managing state and ensuring resiliency. Take the ES framework for example. The Mesos Elasticsearch framework provides users with a complete, scalable, resilient ES cluster. The framework can be started with a multitude of configuration options; from ES resources to the number of nodes in the cluster. The framework then takes care of the orchestration and creates an operational ES cluster. Once up and running, the cluster can be used in the same way as if it were installed from the official binaries.
Within the ES cluster, the data is replicated. The replication is configurable, but by default all data is replicated to all other machines. This provides the maximum amount of resilience to failure. For example if you have nine nodes in your cluster, nine separate machines would have to fail, all at the same time. If one node fails, it is instantly detected by the framework and reinstantiated. If the machine is no longer available, it will reinstantiate on a different host.
The diamond in the ES framework’s crown, however, is scalability. Because the data is replicated to all other machines, it is simple to scale the number of ES nodes down to one, back up to 49 and back down to 3, with zero data loss and downtime. All of this is achieved by a single API call.
This enables the advanced scheduling of databases. Imagine that a database specification has been over-prescribed. With Mantl, it is a simple API call to reduce the number of nodes. Imagine that there is a sudden surge in demand for a service, and ES starts to struggle to keep up with the number of reads. Simply make an API call to increase the number of nodes to spread the load.
I’ve been use ES as an example, but this is also true for LS and Kibana.
The LS framework is delivered setup to forward any messages written by any Mesos task to elasticsearch. But it can easily be configured to deliver application specific logs through the help of a configuration file. The LS framework is able to monitor a huge collection of log sources (e.g. syslog, Mesos, log file, etc.) so users don’t have to write any custom code to connect to logstash. Simply pass in a configuration file and log away.
Demo
Time for a demonstration of these capabilities. Below is a video showing a live Mantl cluster setup for the Cisco Live 2016 event.
Demo of Mantl ELK Implementation details
Mesos exposes a significant amount of functionality in the framework interface. In fact, the framework interface is actually a combination of a scheduler and executor interfaces. The scheduler is responsible for orchestrating the cluster of executors and maintaining some sort of state. It may also provide a top-level API to interact with the rest of the cluster. The executors are responsible for completing a task. In this situation the respective executors are responsible for running the ES, LS and Kibana tasks. The interfaces are exposed in C++, Java and Python. However, for new projects, I would recommend looking at the HTTP interface, which decouples the code from the Mesos binaries
The image above shows an overview of the architecture of all the frameworks. The LS framework ensures that every agent has an instance of logstash (pink), so it can forward all the local file logs to ES. The ES framework forms a cluster (green) between the nodes. The framework is responsible for maintaining the validity of the cluster. If any of the agents or ES tasks fail, another task will be spawned on another node and re-clustering will commence. Finally, Kibana is running on any number of nodes (turquoise) and automatically connecting to the ES cluster. Thanks to Mantl, all elements have a consul DNS address, so Kibana and LS communicate with ES via a single HTTP endpoint.
For all frameworks there are two run-mode options. The frameworks default to using Docker containers (i.e. a docker container for the scheduler and multiple docker containers for the executors). Using containers benefits users by making the project easier to distribute, easier to test and simpler to lock down. The only dependency is Docker and Mesos. The frameworks also have a “JAR mode”, where the Java binaries are distributed and can be run directly on the infrastructure. For this mode all hosts required the Java 8 JRE and the correct Mesos libraries (which should be installed anyway). The benefit of JAR mode is that Docker is no longer required.
Out of the three components, the ES framework is the most mature but also the most complicated. ES has to form a cluster. In order to do this the cluster must be able to discover itself. Discovery in a multi-tenant, distributed system is a difficult challenge. And because ES discovery is core to ES’s operation, the discovery code must be a part of Elasticsearch. In order to maintain forward compatibility, the framework uses the in-built Zen discovery mechanism, in Unicast mode. The default Multicast mode is often blocked in cloud infrastructure systems. The scheduler provides ES with the addresses of the other nodes. Once a new node has connected to the cluster, it uses the Gossip protocol to discover the other nodes.
To be resilient and to scale down to one node, the nodes use a special ES setting that replicates all data to all nodes:
“`
index.auto_expand_replicas: 0-all
“`
This setting can be overridden by the user if they know that they don’t want to scale below a certain number of nodes.
The executors start an in-line version of ES using the Java client. The advantage of this is that the executor has direct control over the ES process, including the lifecycle. The downside is that this couples the project to a specific ES version. In future versions of the framework we will be looking to run the official ES docker image/binary in order to decouple the framework from ES version updates.
All of the framework state is written to Zookeeper. This means that if the scheduler fails, the restarted scheduler is able to query Zookeeper and quickly obtain the last known state of the cluster. The new scheduler will then send a health-check request to ensure that all the executors are still alive and none have been lost whilst the scheduler was away.
The authors of the ES framework code have made a significant effort to test all the major features of the framework using a project called Minimesos (www.minimesos.org). This enables the continuous delivery of new features with the confidence that there are no regressions.
For the LS framework, the architecture is slightly different. The goal of a LS executor is to monitor any number of logs for changes. In order to do that, the executor needs to be running on the machine it is trying to monitor. This means that the LS scheduler is responsible for running a logstash instance on every single Mesos agent (the name for a worker node). There are times when there aren’t enough resources to run an instance of the executor. For example, when one node’s resources have been allocated to one huge application. But this can be mitigated by using Mesos reservations, which is an API to tell Mesos to always save some resources for LS.
The Kibana framework is much simpler. Kibana is a true stateless application, so it doesn’t matter when or where it is created or destroyed. In fact, the Kibana framework is simply a wrapper for the official Kibana image, adding features such as orchestration and state.
Conclusions
The ELK stack on Mantl is a major step forward towards the ultimate goal of performance optimisation, resiliency and scalability.
Performance optimisation is possible due to the flexibility of the underlying Mantl architecture. When a resource is no longer required (CPU, RAM, disk), for example overnight when demand is low, machines can be turned off or terminated to save costs without affecting usability.
The system is resilient against failure. If any of the software or hardware fail, they will be reinstantiated immediately. This increases service availability to near 100%. If your application has become successful and the services are under load, it is very easy to scale up. Even with ES. The data is safe, due to ES’s shard replication strategies and snapshot/restore functionality. The data can be persisted to disk, or even a software defined storage solution to provide triple redundancy.
It would be fair to ask “why ELK?”. The ELK stack is unique in that it provides end-to-end, ETL-to-visualisation in a scalable form factor. The Elasticsearch database has broad enough functionality to suit a majority of use cases. And most important of all, each component can handle failure gracefully. Mantl, on the other hand, has been developed to make the process of creating a dynamic cluster as simple as possible. Mantl is a set of programmable infrastructure tools that users can easily script to create a cluster of their choosing. This makes it a perfect platform on which to automatically deploy the ELK stack.
More information
For more information on any of the projects discussed, please get in touch. You can find all the information introduced in this blog post and more from: Mantl elasticsearch logstash kibana




 To make the challenge even more exciting, the weekend before the event, the arena was rented for a private event, so load in could not begin until the Monday of that week. All tables, switches, Wi-Fi access points, and cabling all had to be ready, but staged out of sight. Everything had to be ready for Thursday of that week for an internationally televised live event.
To make the challenge even more exciting, the weekend before the event, the arena was rented for a private event, so load in could not begin until the Monday of that week. All tables, switches, Wi-Fi access points, and cabling all had to be ready, but staged out of sight. Everything had to be ready for Thursday of that week for an internationally televised live event.

