
During the past year, Cisco Security Incident Response Services has provided emergency incident response services for many customers dealing with incidents that sometimes become a ransomware event. In many cases, we were engaged by the company at the first sign of trouble and were able to help contain the initial incident and reduce the ability of the attacker to shift to a ransomware phase. In other incidents, we were asked to help long after the attackers were in the environment and the systems were already encrypted.
In this blog post, I will share some practical tips that our team use with our customers to help mitigate the risk of ransomware causing a significant business outage.
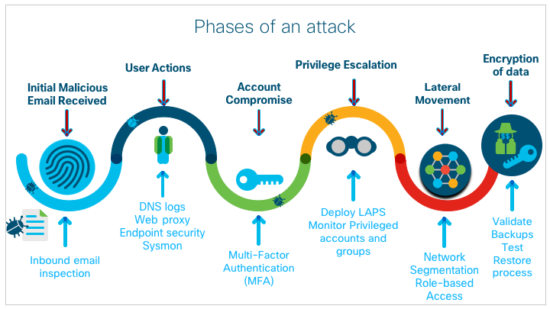
If we follow the standard attack lifecycle (Figure 1), the first step that we need to consider is how we would address the initial attack vector. For this blog post, let us assume the initial access vector is email (which we have observed is often the case).
Initial Attack
The first thing to consider is intelligence-based email monitoring and filtering. An example of this would be the Cisco Email Security Appliance (ESA) product which integrates Cisco Talos threat intelligence into an active email inspection platform.
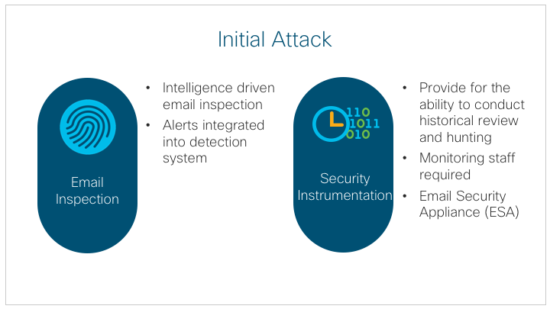
ESA should be deployed to examine email, both inbound and outbound, from the organization. This filtering should be tied to an intelligence feed that dynamically adds new known malicious domains, IP addresses, behavioral indicators, signatures, etc.
By itself, this will not fully protect an organization but without this, you expose your users and your environment to preventable email-based attacks. This control should create log events into the security monitoring system. These events should be reviewed regularly by a member of the monitoring team and if possible correlated with other events (involving the same time, internal hosts, external IP/Domain, and any malware detected). The capability of being able to also review email historically for suspicious attachments or previously unidentified malicious files is helpful for scoping and understanding the scale of the incident and can be used for hunting if the initial detection somehow fails.
User Actions
Subsequent to the initial malicious email entering an environment, the next obvious question is “did the user open it” or “did the user click the link”? To answer these questions, we require some specific log telemetry from within the environment.
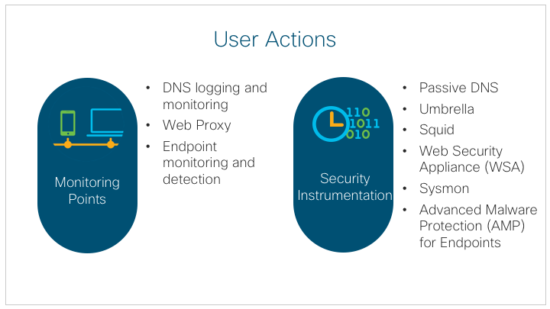
DNS logs such as those available by using Cisco Umbrella, can be invaluable to identify if a user/IP address/device made a request that is related to a known suspicious domain or IP address. If there is an active incident, these logs should be examined for any requests associated with the incident. These DNS logs should be part of the overall logging environment and the events should also be used to block and track requests to known malicious domains. Again, this should be correlated into events of interest for the monitoring team to consider. This helps us understand if the domain was requested, but does not by itself indicate what the interaction was between the user and the destination.
To gather information on the interaction between the user and the destination, we require logs from a deployed web proxy system that captures the outbound web requests and the responses. Cisco Web Security Appliance (WSA) is an example of an active web proxy/filtering system, powered by Cisco Talos threat intelligence. These systems can often block or filter known malicious sites (based again on intelligence) and also retain the http transaction between the user’s web browser and the destination. This can help us to answer the question of what was done on the site, or what the site sent as a response.
To address the question of “did the user open the file” we recommend the implementation of the Windows SysInternals System Monitor (Sysmon) which can help to answer the question of user behavior and activity. Alternatively, many endpoint security tools may also be able to answer this question. Be sure to test your tools before an incident, so you know what normal activity looks like before you get into an incident and have to try to parse the alerts.
Account Compromise
Following the attack life-cycle, the next phase is account compromise: did the user either provide their credentials (e.g., if they were prompted to enter their password to access what appeared to be a legitimate company web page) or did the malware gather local cached account data from the system? This is where we recommend multi-factor authentication (MFA) as the standard for all environments.
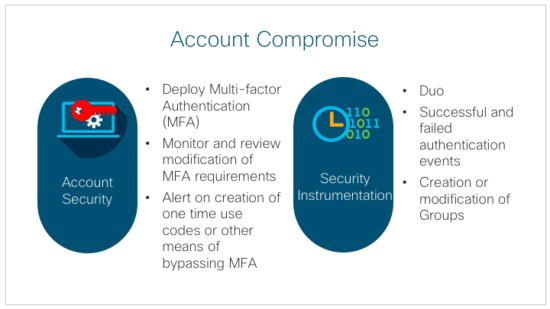
We frequently recommended multi-factor for “high risk” accounts, or for “all externally facing services”, but with the current attack patterns we recommend multi-factor for all Active Directory environments. There can be technical limitations on implementing MFA for some legacy systems, legacy access types, etc. Those exceptions should be identified and very closely monitored for unexpected activity, or isolated into separate Organizational Units or Groups. This may allow early detection of misuse and may limit the impact of these systems or credentials, should they become compromised.
Another key consideration is to monitor the system used to manage the multi-factor authentication. We have seen attackers attempt to bring these systems offline, to attempt to access these systems, or to successfully access these systems and either create one-time use passcodes or create a new account that was allowed to bypass the multi-factor requirement. These systems must be closely monitored for all access and modifications to the users, groups, or creation of one-time use codes.
Privilege Escalation
The next phase is privilege escalation. In this phase, we recommend a multi-pronged approach as there are multiple risks to address. The first risk is if the environment has a shared local administrator password across multiple devices. This is still a very common practice in many environments due to a number of factors.

A solution that can assist with this is implementing the Microsoft Local Administrator Password Solution (LAPS). This provides a better method to manage local accounts. The second risk is an attacker compromising one of the privileged accounts in the environment. If multi-factor authentication is required on these accounts, this should be unlikely, but these accounts must still be monitored for mis-use. Additionally these privileged groups should be monitored for modification (adding/deleting or users, or change to the group roles). These are also events that should trigger alerts that are evaluated by the monitoring team.
Lateral Movement
Lateral movement occurs next. To detect and thwart this, we need to reduce the ability for a user account to move freely within the environment without being validated or having authorization.
This can be started by reducing the internal network access from the standard user segments and VPN devices. Network segmentation can be complex to implement across the entire environment, but it is often achievable to make some small restrictions using virtual LANs (VLANs) to reduce which networks can access critical segments. Privileged activity or Administrator activity should always originate from an approved “jump box” that is hardened and monitored, and has specific access restrictions for only users that require this access. Role-based access should also be enforced, not everyone should have access to production, not everyone should have access to the code base, or sensitive data. Access (successful and failed) should be logged and correlated. Reducing the number and type of ports and protocols within the environment may also help to reduce the spread of malware or lateral movement that is expecting specific capabilities, such as the Server Message Block (SMB) protocol, for example.
Encryption of Data
The ultimate risk of a ransomware attack is in the final phase. This is when the attacker is able to encrypt critical business systems or services, causing a business outage. The impact of this outage varies based on the function of your business, your tolerance (or your customers’ tolerance) for downtime, and many other factors.
For environments that have critical services that impact life and safety of people, we strongly recommend partnering with the disaster recovery and business continuity teams to test existing plans and update them accordingly with steps that cover full data center loss via ransomware. Other questions that should be considered: Are your backups offline and secure from the possible ransomware? Does your online backup system use the same credentials as your Active Directory environment? Has your organization practiced what a data restore would look like and how long it would take? Is the necessary hardware (or virtual space) available to be able to restore your environment? Is there an understanding of dependencies and other tactical considerations?
Take Action Today
These recommendations will help you improve your ability to detect attacks in the earlier (pre-ransomware) stages and will reduce the overall impact of a ransomware incident. You must take key preventative steps, while also readying your team to act when it strikes. Educate yourself with more information on Cisco Ransomware Defense solutions. If you feel you need hands-on, expert assistance, consider contacting our team – our incident responders can help you prepare your own team with proactive services and we can work alongside your team during active incidents.





