
A few months ago at NVIDIA GTC we discussed how you could run your AI/ML workloads on Cisco infrastructure and get the benefits of integrated management and solve your data gravity problem. At the same time, we introduced our collaboration with Google to bring Kubeflow deployments on-premises. Now we are bringing AI/ML workloads to Cisco hyperconverged infrastructure with release 3.5 of Cisco HyperFlex, with support for NVIDIA’s most advanced data center GPU, the Tesla V100.
Our AI/ML ecosystem partners are supporting us by validating their solutions on HyperFlex, hence providing customers with great options for creating and deploying AI/ML workloads.
Orchestrate AI Workloads with Cisco HyperFlex and Kubernetes on NVIDIA GPUs
Artificial intelligence research puts incredible demand on computing systems. As AI proliferates, both across industries and within organizations, and machine learning models become more and more complex, there is a need to create dynamic compute environments for AI that can scale on demand. This requires a combination of GPU-accelerated systems and software tools to automate deployments.
Cisco HyperFlex offers a great infrastructure foundation for hosting AI workloads. Along with providing ready to consume infrastructure with a cloud-like performance and management, HyperFlex also delivers the scalability required for your AI projects. The ability to scale using compute only nodes equipped with GPUs, gives you the flexibility to closely match your infrastructure to your workload requirements.
Containers are popular for AI deployments and Kubernetes is a widely used tool for orchestrating containers. Cisco HyperFlex introduced Kubernetes support in version 3.0 and built the HyperFlex FlexVolume driver to enable persistent volumes for Kubernetes managed containers. Now we have qualified HyperFlex for Kubernetes on NVIDIA GPUs . With GPU-aware Kubernetes, users have a powerful tool for AI container deployment, scaling, and management across clusters of nodes, both on-prem and in the cloud. Kubernetes on NVIDIA GPUs allows for orchestration of resources on heterogeneous GPU clusters, health monitoring to optimize utilization, and supports multiple container technologies for flexibility.
The combination of Cisco HyperFlex and Kubernetes on NVIDIA GPUs enables automated deployments and maximum utilization, allowing users to scale across nodes and even across clouds, and helps them get the most from their AI infrastructure.
ePlus HyperFlex AIM Machine Learning Starter Kit
ePlus, a long time Cisco Gold Partner is providing a Machine Learning starter kit based on Cisco HyperFlex and Skymind SKIL software.
The foundation of the HX AIM starter kit is Cisco HyperFlex All Flash, equipped with NVIDIA Tesla GPUs combined with the Skymind Intelligent Layer (SKIL).
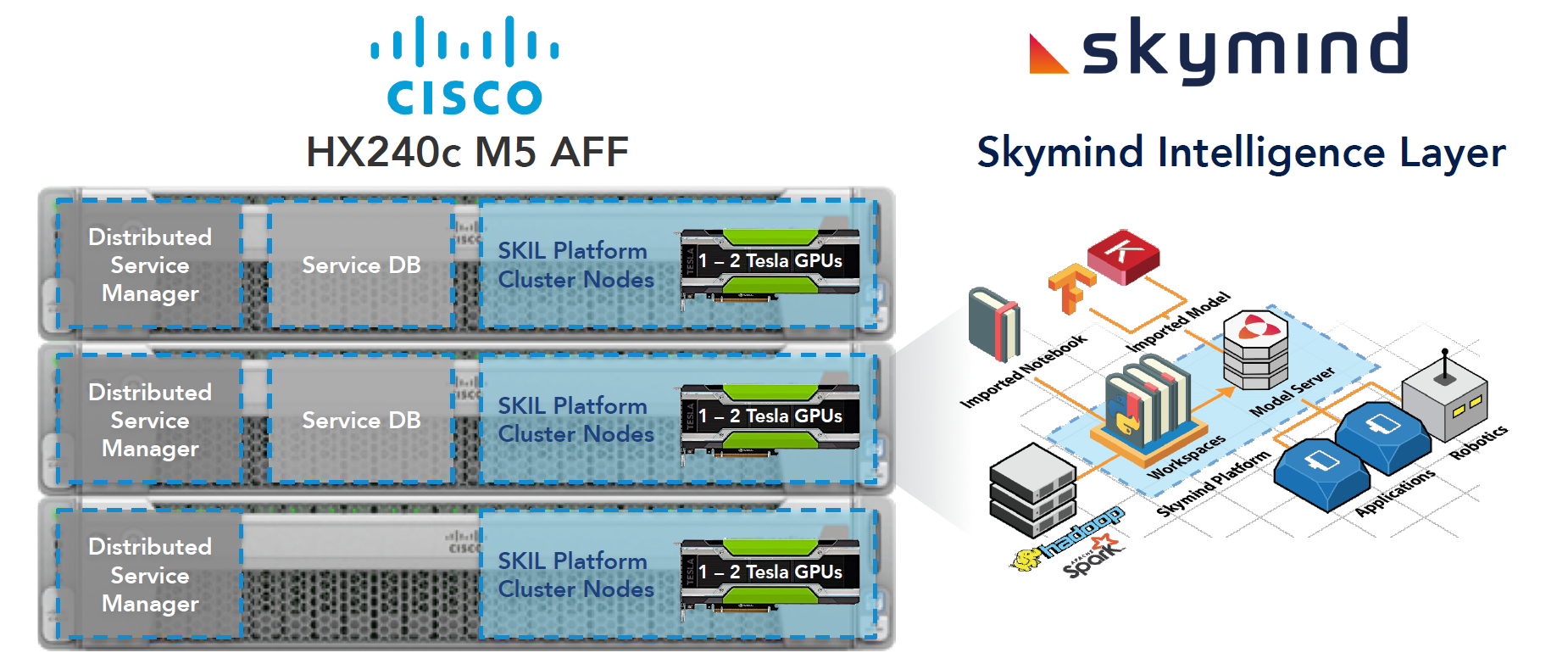
HX AIM Components
This powerful combination provides efficient hyperconverged infrastructure and optimized deep learning tools, all automated for simple operations of the entire ML lifecycle.
ePlus and Data Monsters have partnered to provide infrastructure and data science professional services that complement HX AIM.
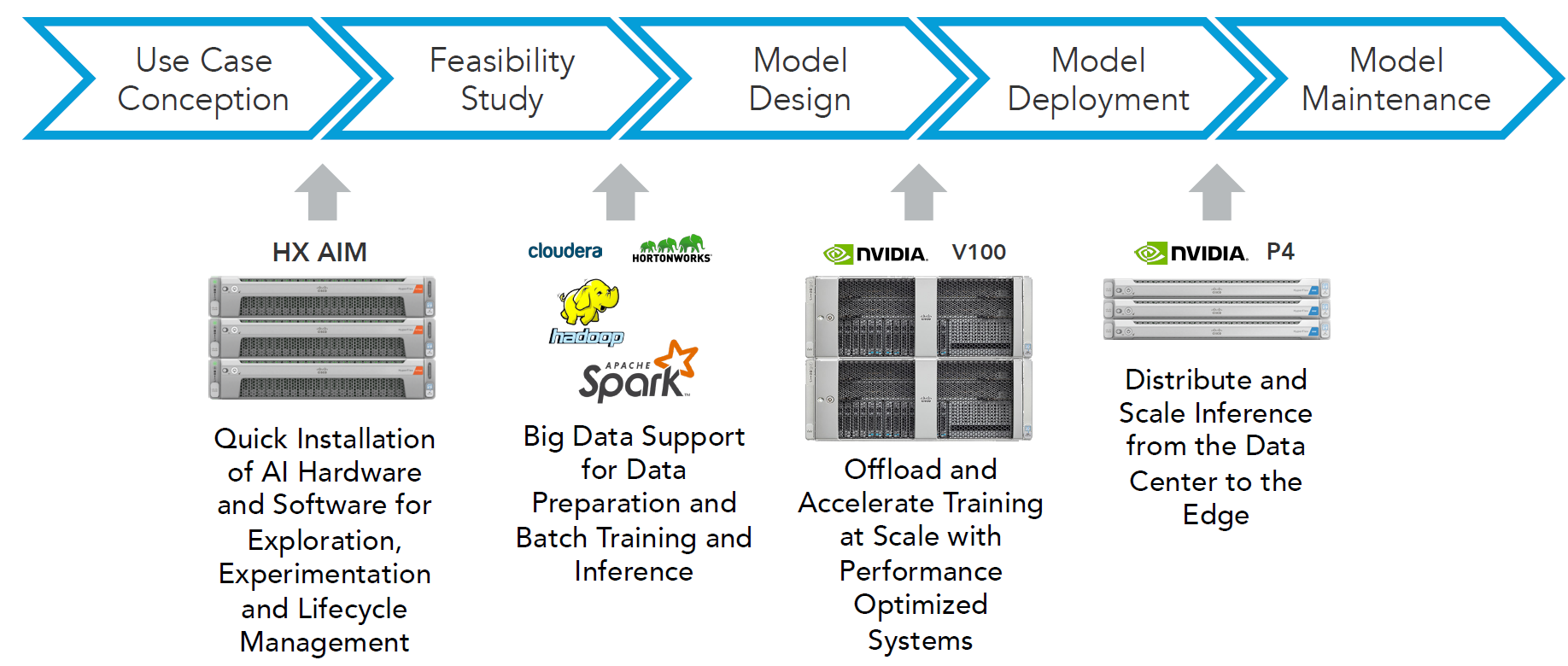
Phased HX AIM Elements
The ePlus HX AIM starter bundle comprises:
- ML starter kit that can evolve as your AI needs evolve
- Cisco HyperFlex All Flash bundled with Skymind SKIL Enterprise AI Distribution and NVIDIA Tesla GPUs
- Simple to install and operate solution for AI exploration, training and inferencing
- Enablement services and support available to accelerate time to value.
For more information on the HX AIM starter bundle or to request a meeting with Cisco and ePlus at Cisco Live, contact the HX AIM team at CloudServices-Ops@eplus.com
Cisco Live
If you are at Cisco Live in Orlando this week and want to learn more about Cisco infrastructure solutions for AI/ML workloads, you should plan to attend the following sessions:
Demystify Artificial Intelligence and Machine Learning with Cisco UCS [BRKINI-2348]
In this session, you will get an AI/ML/DL primer and an overview of the Cisco infrastructure and software stack needed to successfully implement AI in your organization, as well as some examples from actual use cases.
Accelerating Big Data and AI/ML with Cisco UCS and HyperFlex [PSODCN-1190]
Come to this session on Wednesday, June 13 at 2:00 PM to find out why AI/ML presents new challenges to the IT team and how Cisco UCS and HyperFlex address them. Our presentation will discuss integrated solutions for both big data and AI/ML.
You can also visit our demo in the Cisco Campus: Accelerate Analytics and AI [DEMO-1013]
By 2021, there will be 847 Zettabytes of data created. A good portion of that data will come from internet of things. Our “Accelerate Analytics and AI” demo incorporates
- Predictive analytics being done at the edge in an electric utility substation
- Global analytics in the electric utility data center on Hadoop with data from multiple substations
- Deep learning with TensorFlow (or your favorite deep learning framework) integrated with Hadoop
We will also demonstrate Bitfusion FlexDirect, a self-validated solution that enables network attached GPU on HyperFlex. In addition, we will show Kubeflow running on UCS and HyperFlex.
Keep the conversation going. Reach out to me, @FrancoiseBRees, to discuss running AI/ML workloads on Cisco UCS and HyperFlex.





