
At this year’s Cisco Live Las Vegas we introduced Policy Studio, an AI assistant in Cisco AI Defense that guides users through building custom policies for adaptive guardrails. The assistant interactively walks the user through the process end-to-end in the chat.
Insights—targeted questions about what the policy should mean, supported with evidence from the user’s data—are synthesized by the assistant and sent to the control console for the user to review and accept or reject. The assistant integrates the feedback and rewrites the policy, publishing the refined policy to the Cisco AI Defense adaptive guardrails console for runtime enforcement.
We first introduced Policy Studio in a previous blog post, available here. The fundamental strength of Policy Studio lies in its full customizability and ability to align the policy to any domain. In this blog, we’ll give a closer look at what makes that flexibility possible.
Multiagent Orchestration
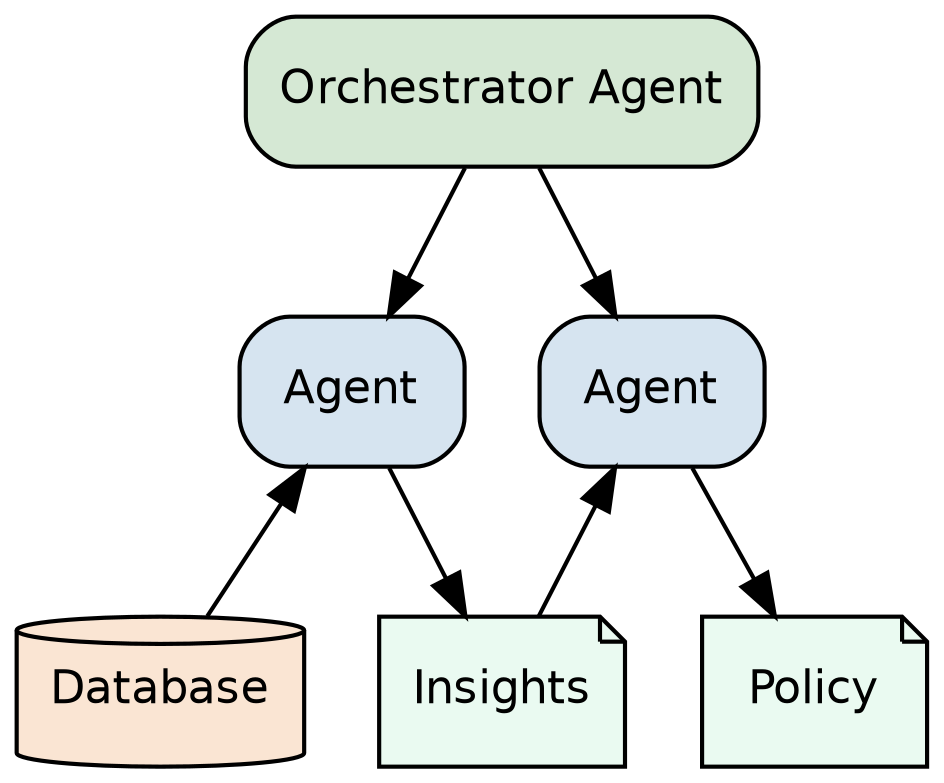
Policy Studio uses multiagent orchestration. The assistant acts as an orchestrator agent and manages specialized subagents. The orchestrator agent spawns subagents, providing them with targeted instructions like, “Investigate with a focus on X” or “Update the policy to tighten boundary case Y.” The orchestrator agent sees the bigger picture and can reflect on what’s the optimal next step. It has the full operational and historical context of the session, including the chat history, what insights have been presented to the user, how the policy has changed over time, and the outputs of subagents. Policy refinement is all about the details. Policies outline detailed definitions, edge cases, boundary conditions, and rules. The orchestrator can synthesize these details together into action items and delegate the work.
Multiagent orchestration benefits from a separation of concerns. Agents are great at using tools to accomplish a task, but as task complexity grows, results may vary, and task performance can suffer. The orchestrator delegates and splits work into manageable tasks assigned to subagents.
Insight Discovery
Subagents assist the orchestrator with insight investigation and data analysis. Insights are high-level issues with the policy. Insight investigation includes identifying gaps and ambiguities in the policy as well as clustering samples labeled by the policy into groups that share a common thematic or behavioral trace.
For example, a group of samples may be labeled with a broad interpretation of a rule in the policy, causing samples that should not be covered under the rule to be flagged as violations. An insight allows the offending rule to be identified, and its failure mode to be diagnosed. Synthesizing such insights requires a deep understanding at the sample level, becoming familiar with common examples and edge-cases alike.
If the orchestrator wants to understand what kinds of samples make up a dataset and cluster samples into insights, it uses subagents. The subagent will use successive tool calls to methodically explore the dataset and then synthesize its findings for the orchestrator. Extensive sample-level analysis would not be possible without subagents. Every sample an agent reads fills its context window.
A model’s context window contains all the tokens ingested and generated over its lifetime including the chat history, internal reasoning, tool inputs, and tool outputs. Once the context window is full, it needs to be summarized and compacted to free the agent up for more work.
Compaction preserves the main ideas, but important details can be lost in the process. Task delegation to subagents preserves the context budget of the orchestrator. All the tokens spent during task execution, including reading all those samples, are contained in the subagent’s context window.
Policy Optimization
Insights reviewed by the user in the control console are used by the orchestrator agent to update the policy. Insights identify the gaps and ambiguities in the specification as well as trace common behavioral clusters relative to the rules in the policy. In addition to identifying an issue, insights also propose labeling directives meant to address the identified issue.
Mapping insights to concrete changes in the policy comes with unique challenges. Policy documents are comprised of detailed rules and specifications to ensure labeling is precise and consistent. In our previous work on constitutional policies, we found that LLMs reading a detailed constitutional policy outperformed humans reading the same policy.
The orchestrator agent needs to determine the optimal mapping from the insight directives to changes in the detailed policy. Policy rules and specifications are interrelated. The changes must solve the issue identified by the insight, while not regressing on other samples.
Multiagent orchestration streamlines this process. The orchestrator agent can fan-out subagents in parallel to update and verify the policy, across all the insights. Parallel agent execution speeds up what would otherwise be a much more time intensive operation.
Evolving Threat Landscape
The landscape that adaptive guardrails need to secure is evolving at breakneck speeds: new industries adopting AI, new complex multiagent workflows, the evolution of agent skills and plugins. Each new application will have a different distribution that the policy will have to describe, cover, and define.
Policy Studio was designed to keep pace. By updating our agent suite, improvements can be integrated and deployed seamlessly. We will continue pushing multiagent orchestration to its limits, optimizing our agents to keep yours safe.
If you’re interested in seeing Cisco AI Defense in action and building powerful adaptive guardrails in Policy Studio, you can request a demo with an expert from our team here.




