
As government agencies begin deploying cloud solutions and strategizing to meet cloud IT modernization mandates, a question arises – what will the future of the agency look like when they update their systems and start implementing cloud solutions? And further, possibly most important – will cybersecurity protocols hold up?
There are many cybersecurity solutions available for organizations and companies going to a digital, cloud architecture, but most of them aren’t suitable in a government environment. Government agencies have unique needs and requirements, and because of the sensitive nature of their work, they operate under a more stringent set of rules. Therefore, the agency CIO is going to look at their IT and cybersecurity strategy through a different, and possibly more conservative, lens – making it a constant battle between being in compliance with federal mandates and staying competitive in their digital transformation.
That’s why the federal government put into place the Federal Risk and Authorization Management Program (FedRAMP). This is a government-wide program that “provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services,” according to the U.S. General Services Administration (GSA) website. The program determines which cloud solutions are viable for government agencies from a security perspective, helping agencies keep sensitive and confidential information secure while still taking advantage of the latest cloud solutions.
So, why is the government going through all this trouble to approve cloud solutions for its agencies? According to the FedRAMP website, “cloud solutions allow for faster processing and more elasticity in computing in an on-demand, more efficient platform.” In other words, cloud solutions will enable the government to function more seamlessly, and access people, resources and information like never before – all on a secure and efficient network. Programs like FedRAMP save agencies an estimated 30-40 percent of government costs, as well as time and staff needed to do typical security assessments for agencies. Plus, FedRAMP is a collective effort between major government agencies including: the General Services Administration (GSA), National Institute of Standards and Technology (NIST), Department of Homeland Security (DHS), Department of Defense (DOD), National Security Agency (NSA), Office of Management and Budget (OMB), and the Federal Chief Information Officer (CIO) Council. But while they are working in concert, can the government move fast enough to get these cloud solutions approved?
Some of the problem is the necessary approval process that can take months and costs money, which deters many vendors from doing business with the federal government. So, FedRAMP is now offering FedRAMP Tailored, which is a faster approval process for cloud service providers with low-impact software-as-a-service offerings. This program cuts down the number of security controls required in the approval process from 125 to 36 – lowering the up-front costs involved and opening up more possibilities for vendors who currently do business with individual agencies.
As FedRAMP continues to evolve and other vendors become certified, government officials will have a greater opportunity to keep up with the latest digital trends – all the while keeping cybersecurity core to its IT strategy – giving the agency a peace of mind in keeping information safe, employees the tools to do their jobs better and easier, and the public the confidence that they will experience the best service and protection possible.
October is Cyber Security Awareness Month, and Cisco is a Champion Sponsor of this annual campaign to help people recognize the importance of cybersecurity. For the latest resources and events, visit cisco.com/go/cybersecuritymonth.




 The Cisco Determination: Our CRDC site leader Nan Chang and most of our team members walked the entire way. Which takes a good deal of determination as this took us seven to eight hours! By encouraging and supporting each other, we got through this challenge together. Some of our teammates were bearing bad foot aches and pains after walking such a long distance, but they wouldn’t seek medical support until their feet touched the finish line.
The Cisco Determination: Our CRDC site leader Nan Chang and most of our team members walked the entire way. Which takes a good deal of determination as this took us seven to eight hours! By encouraging and supporting each other, we got through this challenge together. Some of our teammates were bearing bad foot aches and pains after walking such a long distance, but they wouldn’t seek medical support until their feet touched the finish line. A “pipeline” simply defines the process by which an activity is completed. The concept of a “software delivery pipeline” is well understood today in IT, but network configurations also follow a pipeline. Today’s network configuration pipeline is a complex maze of forks, bends, off shoots, dead ends, and paths that require special timing, keys, and phases of the moon. The current network configuration pipeline needs to go, and be completely replaced in NetDevOps.
A “pipeline” simply defines the process by which an activity is completed. The concept of a “software delivery pipeline” is well understood today in IT, but network configurations also follow a pipeline. Today’s network configuration pipeline is a complex maze of forks, bends, off shoots, dead ends, and paths that require special timing, keys, and phases of the moon. The current network configuration pipeline needs to go, and be completely replaced in NetDevOps.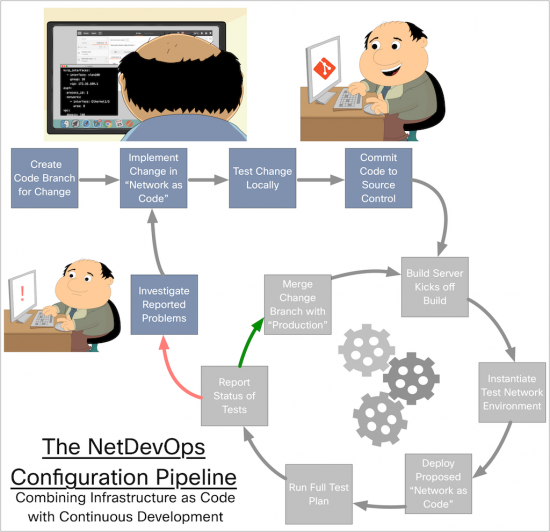 The NetDevOps pipeline
The NetDevOps pipeline Networking engineers must adopt new skills for NetDevOps, but this isn’t new to us as network engineers. We’ve had to learn new skills for IPv6, MPLS, 802.1x, and so much more. Not to mention the list of new technologies that have flooded us in the “Software Defined Networking” era. First and foremost, network mastery is still a critical skill. I scoff a little bit at all the doomsday talk I see around these days about “the death of the network engineer”. Network engineering is as strong as ever, but it is changing. Just look at what has happened to our cousins in software development as DevOps has flourished.
Networking engineers must adopt new skills for NetDevOps, but this isn’t new to us as network engineers. We’ve had to learn new skills for IPv6, MPLS, 802.1x, and so much more. Not to mention the list of new technologies that have flooded us in the “Software Defined Networking” era. First and foremost, network mastery is still a critical skill. I scoff a little bit at all the doomsday talk I see around these days about “the death of the network engineer”. Network engineering is as strong as ever, but it is changing. Just look at what has happened to our cousins in software development as DevOps has flourished.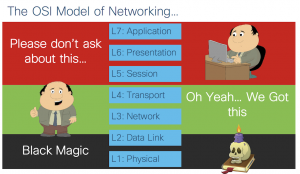 And lastly I turn back to an old friend of us all, the
And lastly I turn back to an old friend of us all, the 