
Co-written with Maciek Konstantynowicz, Distinguished Engineer, Chief Technology & Architecture Office
“Holy Sh*t, that’s fast and feature rich” is the most common response we’ve heard from folks that have looked at some new code made available in OpenSource. A few weeks back, the Linux Foundation launched a Collaborative Project called FD.io (“fido”). One of the foundational contributions to FD.io is code that our engineering team wrote, called Vector Packet Processing or VPP for short. It was the brainchild of a great friend and perhaps the best high performance network forwarding code designer and author, Dave Barach. He and the team have been working on it since 2002 and it’s on its third complete rewrite (that’s a good thing!).
The second most common thing we’ve heard is “why did you OpenSource this?” There are a couple main reasons. First, the goal is to move the industry forward wrt virtual network forwarding. The industry is missing a feature rich, high performance/scale virtual switch-router that runs in a user space and has all the modern goodies from hardware accelerators; built on a modular architecture. VPP can run either as a VNF or as a piece of virtual network infrastructure in OpenStack, OpNFV, OpenDayLight or any of your other fav *open*. The real target is container and micro-services networking. In that emerging technology space, the networking piece is really really early and before it goes fubar; we’d like to help and avoid getting “neutroned” again. More on container networking in a follow-on conversation.
Additionally, 5 or so years ago I had been evangelizing this diagram as a critical target for SDN and a trajectory for work to move the industry forward.
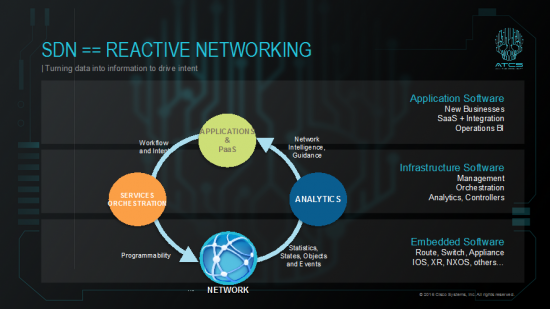
Towards that goal, Services orchestration includes SDN controllers … check. Network == VPP, check. Analytics is immediately the next push in OSS and been in the works for a while and this year, we are also setting our goal to be relevant in the PaaS layer. We have focused on working with Cloud Foundry. All that’s for another blog, this one is on VPP.
So, why is the forwarding plane so important and where cool kids are hanging out? Today’s MSDCs, Content delivery networks and Fintech are operators of some of the largest and most efficient data centers in the world. In their journey to get there they have demonstrated the value of four things: 1) using speed of execution as a competitive weapon, 2) taking an industrial approach to HW&SW infrastructure, 3) automation as a tool for speed and efficiency and 4) full incorporation of a devops deployment model. Service providers have been paying attention and looking to apply these lessons to their own service delivery strategies. VPP enables not only all the features of Ethernet L2, IP4&6, MPLS, Segment Routing, Service Chaining, all sorts of L2 and IP4&6 tunneling, etc., but it does it out of the box. Unbelievably fast on commodity compute hardware and in full compliance with IETF RFC networking specs.
Most of the efforts to towards SDN, NFV, MANO, etc. have been on control, management and orchestration. FD.io aims to focus where the rubber hits the road: the data plane. VPP is straight up bit banging forwarding of packets, in real-time, at real linerates, zero packet loss. It’s enabled w/ high performance APIs northbound but not designed for any specific SDN protocol; it loves them all. It’s not designed for any one controller; it also loves them all. To sum up, VPP fits here:
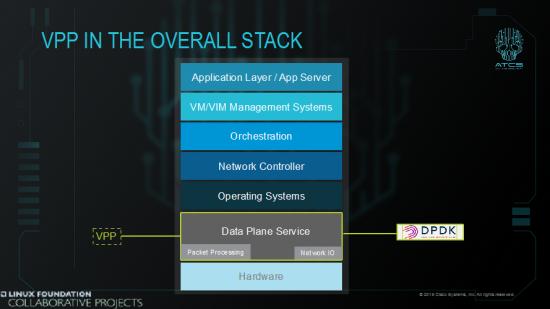
What we mean is a “network” running on virtual functions and virtual devices, a network running as Software on computers. Therefore, VPP-based virtualized devices, multi-functional virtualized routers, virtualized firewalls, virtualized switches, host-stacks and often function-specific NAT or DPI virt-devices as software bumps in a wire, running in computers, and in virtualized compute systems, building a bigger and better Internet. The question service designers & developers, engineers and operators have been asking is how functional and deterministic are they? How scalable? How performant – and is it enough to be cost effective?
Further, how much their network behavior and performance depend on the underlying compute hardware, whether it’s x86 (x86_64), ARM (AArch64) or other processor architectures?
If you’re still following my leading statements, you would know answer to that, but lot’s of us would be guessing and both will be right! Of course it does depend on hardware. Internet services are all about processing packets in real-time, and we love a ubiquitous and infinite Internet. More Internet. So this SW-based network functionality must be fast, and for that the underpinning HW must be fast too. Duh.
Now, here is where reality strikes back (Doh)! Clearly, today there is no single answer:
- Some VNFs are feature-rich but with non-native compute data planes, as they’re just a retro-fittings or reincarnations of their physical implementation counterparts: the old lift and shift from bare metal to hypervisor
- Some are better performing with native compute data planes, but lack required functionality, and are still a long way to go to implement required network functions coverage to realize the levels of network service richness used to and demanded by the network service consumers.
- VPP tries to answer what can be done, what technology or rather set of technologies and techniques can be used to progress virtual networking towards the actual fit-for-purpose functional, deterministic and performant service platform it needs to be to realize the promises of fully-automated network service creation and delivery.
Can we start talking about Deterministic Virtual Networking?
A quick tangent on what I mean by reliable and deterministic network. Our combined Internet experience taught us few simple things: fast is good and never fast enough, high scale is good and never high enough and delay and losing packets is bad. We also know that bigger buffer arguments are a tiresome floorwax-and-dessert-topping answer to everything. Translating this into the best practice measurements of network service behavior and network response metrics:
- packet throughput,
- delay, delay variation,
- packet loss,
- all at scale befitting Internet and today’s DC networks,
- all per definitions in [RFC 2544] [RFC 1242] [RFC 5481].
So here is what we need and are to expect by these simple metrics:
Repeatable linerate performance, deterministic behavior, no (aka 0, null) packet loss, realizing required scale, and no compromise.
If this can be delivered by virtual networking technologies, then we’re in business; as an industry. Now that’s easy to say and possible for implementations on physical devices (forwarding asics have an excellent reason to exist and continue into the future), built for the sole purpose of implementing those network functions, but can it be done on COTS general purpose computers? The answer is: it depends for what network speed, for 10Mbps, 100Mbps, 1Gbps today’s computers work… ho, hum. Thankfully COTS computing now has low enough cost and enough clock cycles, cores and fast enough NICs for 10GE. Still a yawn for building real networks. For virtualized networking to be economically viable, we need to make these concepts work for Nx10 | 25 | 40GE, …, Nx100, 400, 1T and faster.
Why Optimization Matters
At a very basic level, a virtualized network function is simply another workload. Like any workload, it consumes some CPU cycles, memory and IO. However, the typical compute workload mostly consumes CPU and memory with relatively little IO. Often application workloads assume that IO is ubiquitous and infinite. Network workloads are the inverse. They are by definition reading and writing a lot network data (i.e. packets going in and out of the physical or virtual NIC), but because processing is typically only done on the packet header; the demand on CPU is relatively modest. There are network functions like deep packet inspection (DPI) that are more CPU intensive, but for the purposes of this conversation, we will consider network workloads primarily IO-centric. Measuring performance is pretty easy: all that matters is packets-per-second (PPS) throughput. Because the expected behavior and resource consumption of a network workload is well defined, it makes it easier to plan optimizations to increase packet-per-second performance.
The following compute hardware resources significantly affect the performance of network workloads:
- CPU cores – executing packet processing instructions and packet I/O operations.
- CPU cache hierarchy – caching packet processing instruction and data, without need for main memory access, because there is no time for such expensive operations.
- RAM memory – reads/writes of packet processing instructions and data, and packet header data.
- PCIe bus lanes – network I/O connectivity to and from NICs.
- NICs – network packet I/O for physical interfaces, packet processing offload (e.g., checksum), and direct memory and cache access via PCIe.
- NUMA locality for CPU core communication to PCI devices and memory resources.
We can measure network workload performance as follows:
execution_time = seconds/packet
= instructions/packet * clock_cycles/instruction *
seconds/clock_cycle
The main performance contributors then are:
- How many instructions are required to process the packet.
- How well encoded are instructions on computer hardware, including efficiency of parallel execution and minimal dependencies between execution of different instructions or instances of instructions.
- How fast is the actual computer hardware (seconds/clock_cycle)
Making this specific to virtual networking, we can re-write this as
execution_time = seconds/packet
= instructions/packet * clock_cycles/instruction *
seconds/clock_cycle
= clock_cycles/packet * seconds/clock_cycle
or simply
packet_processing_time = clock_cycles/packet * seconds/clock_cycle
Let’s propose a cycles per packet (CPP) metric to be a fundamental measure of NFV system efficiency. To make this even more specific to NFV:
packet_processing_time = CPP / core_frequency.
If we start filling in real-world numbers, we begin to see why efficiency matters. If we look at processing a line rate stream of packets on a 10GE interface we are looking at needing to process ~14.88 million packets-per-second (MPPS, assume 64 Byte Ethernet Layer-2 frames + 20B of preamble + inter-frame gap).
Simple math tells us each packet must be processed within 67.2 nanoseconds (ns). On a CPU core clocked at 2GHz has a core clock cycle of 0.5nsec. That leaves a budget of 134 CPU clock cycles per packet (CPP) on a single 2.0 Gigahertz (GHz) CPU core. For 40GE interfaces, the per packet budget is 16.7 ns with 33.5 CPP and for 100GE interfaces it is 6.7 ns and 13 CPP. Even with the fastest modern CPUs, there is very little time to do any kind of meaningful packet processing. That’s your total budget per packet, to receive (Rx) the packet, process the packet, and transmit (Tx) the packet. And always remember that the actual main memory RAM is 70nsec away! You can’t use main memory access – remember the 67nsec per packet budget – when you need to access memory it’s too late. Dammit! You need to predict what would be needed. You need to predict to create the future. Wait, what?
One simple answer we all knock about is to throw more cores at the problem to spread out the workload or just run faster CPU and chase GHz, but a well engineered solution can take a better approach that uses all the resources in a CPU complex:
- Remember von Neumann bottleneck, limited throughput between the CPU and the memory compared to the CPU speed and amount of memory – it still applies!
- Offloading some packet processing functions to dedicated hardware (e.g., NIC cards)
- Optimal use of CPU caches to address memory access bottlenecks required for moving packet bits between network-workloads. Don’t wait for main memory.
- Optimized packet processing software to take advantage of multiple cores (multi-threading)
- Parallel processing that spreads the packet processing across multiple CPU cores
- Addressed with efficient use of CPU caching hierarchy and pre-fetching.
- No time to afford cache line misses.
- Pipeline vectors of packets, auto-adjust vector size for consistent processing latency.
- Pre-fetch instructions from memory ahead of time, watch the byte boundaries of cpu prefetches, use every one of them.
- Watch those cpu core cache lines, chase cache line misses, dups, evictions.
- Watch the data flow within the cpu socket chip, it’s a “network” after all.
- Addressed with efficient use of CPU caching hierarchy and pre-fetching.
Enter VPP
As you might guess, this is where VPP comes in and has incorporated all the industries hard work over the years figuring out how to fling packets really fast.. Ok, we’ve rambled for a while so let’s quickly list the elements of a virtual network:
- Physical NIC (pNIC) – connect the compute platform to the physical network.
- Virtual Switch (vSwitch) – responsible for forwarding L2/IP4/IP6 packets or all sorts of other L2/IP4/IP6 tunneling encapsulations. This might be between pNICs and VNFs, between VNFs’ vNICs, and so on. vSwitches can support number of network functionalities including security features.
- Virtual Network Functions (VNFs) – logical network functions that perform any number of packet processing functions including Layer 2 switching, IPv4 and IPv6 routing, quality of service (QoS), stateless and stateful security features and multi-protocol routing, and so on. Use Virtual NIC (vNIC) to connect to the virtual or physical network.
Virtual networking typically needs to support three types of logical links connecting the elements of a virtual network:
- vSwitch-to-pNIC, VNF-to-pNIC – logical link connecting the vSwitch or VNF to a physical NIC interface using either dedicated I/O hardware mapping (PCI or PCI-passthrough drivers) or shared I/O hardware mapping (Single Route I/O Virtualization [SRIOV] drivers.
- VNF-to-vSwitch ― logical link connecting VNF virtual interfaces to vSwitch virtual interfaces. VNF virtual interfaces (vNICs) on x86 machines rely on Intel virtualization technologies (VTs), including emulated or paravirtualized network I/O. vSwitch virtual interfaces provide a backend to VNF vNICs.
- VNF-to-VNF ― logical link connecting VNF virtual interface to VNF virtual interface. In most cases the link is connected indirectly via vSwitch but direct connectivity options also exist.
For compute systems running say Linux, there is a clear trend to run vSwitches in the host user-mode versus kernel-mode, as this provides much better control over the packet processing performance. It also decouples networking from the electronic state of the computer which is controlled by the kernel. For example, as part of our broader VPP contribution to FD.io, we include a VPP vSwitch. This is a user-mode packet processing and forwarding software stack for commodity hardware. It is high performance (~14 Mpps on a single core) while providing rich multi-layer networking functionality ― including Layer 2, IPv4, and IPv6 forwarding with large tables ― multi-context VRFs, multiple types of tunneling, stateless security, QoS policers (all of RFCs incl. color-aware ones), and is extensible through the use of plugins.
But moving packet processing to user-space is about more than performance; its about flexibility, availability and speed of innovation. The flexibility to put upgrade your packet processing without rev-ing your kernel, provide distinct application specific networking features to different applications running on the same box, or complex packet processing for VNFs into containers. The packet processing graph architecture of VPP together with its powerful plugin capabilities allow anyone to write new features, or support for hardware acceleration, and deploy them simply by dropping a plugin binary into a directory. Never has innovation in networking been more open and focused on easy, rapid development of features (and potentially new interoperable standards).
I’ll touch a little more on FD.io and its goals towards the end of this conversation.
What is VPP?
Originally born from a Barach and developed by a team at Cisco, Vector Packet Processing (VPP) is a proven technology shipping in many Cisco existing networking products. Combined with a compute-efficient network I/O (e.g., DPDK), VPP enables very efficient and high performing design and offers a number of attractive attributes:
- User-space network packet processing stack for commodity hardware.
- High performance:
- Multiple Mpps (Millions packets per second) from a single x86-64 CPU core.
- 120 Gbps Ethernet full-duplex on a single physical compute host with 2-Socket-CPU and 12@10GE.
- On a single physical compute host with 4-Socket-CPU with 18@40GE, the current box-full bandwidth number (1518B L2 packet size): 462Gbps.
- Current box-full PPS number (64B L2 packet size): 297Mpps.
- The same code runs on baremetal hosts, in VMs, or in Linux containers.
- Integrated vhost-user virtio backend for high speed VM-to-VM connectivity.
- Layer 2 and Layer 3 functionality and multiple tunnel/encapsulation types.
- Uses best-of-breed open source network I/O driver technology: Intel DPDK.
- Extensible by use of plug-ins.
- Control-plane and orchestration plane via standards-based /common APIs and SDN protocols (via Honeycomb).
- It is multi-platform, running on x86_64, AArch64, PowerPC, MIPS processor types and is Endian clean and 32-bit and 64-bit clean. It uses widely available kernel modules (such as uio and igb_uio) and supports DMA-safe memory.
- It has full spec-compliant error checks for all network encapsulations, extensive counter support, export of telemetry and full input checks on by default (many other implementations skip this one).
- Full counter support and telemetry “push” export without degradation of performance.
VPP runs a Linux user space process. The same image works in hosts, guests in VMs, and containers. When running in hosts it supports driver access to NICs over PCI. When running in guests in KVM or ESXi virtual environments it can access the NICs over PCI-pass-through or SRIOV. VPP integrates DPDK PMD device drivers that support a wide range of NICs. In addition, VPP natively supports the following NIC devices:
- Intel 82599 physical function, 82599 virtual function, Intel e1000, virtio.
- HP rebranded Intel Niantic MAC / PHY.
- Cisco virtual interface cards (VICs).
- Integration with DPDK and all SOCs/NICs that support DPDK. With strong support by DPDK community and Intel is the communities get out of jail for having to support every NIC ever produced.
VPP supports improved fault tolerance compared to kernel code. A VPP crash seldom (read never) requires more than a process restart. In-Service Software Upgrade (ISSU) updates do not require a system reboot, just a process restart or a feature unload/load.
From a security perspective, VPP code has been reviewed and tested by a white-box security consulting team and I expect it to be more subjected to even more inspection now that it is part of FD.io VPP implements the following security functionality:
- Image segment base address randomization
- Shared-memory segment base address randomization
- Stack bounds checking
- Debug CLI “chroot”
Why is Vector Packet Processing Faster?
VPP relies on processing multiple packets at a time to optimize the use of commodity hardware resources. It uses a completely different software architecture compared to the traditional scalar approach of processing one packet at a time.
Here is a brief comparison of scalar and VPP approaches and their impact on compute resources:
Scalar Packet Processing Operation
The traditional approach that processes one packet at a time, generates per-packet-interrupt:
process.A
process.B
process.C
{stuff happens}
return
return
return
… then return the interrupt. This approach requires considerable stack depth and introduces to issues:
- Issue 1: Thrashing the I-cache
- When code path length exceeds the primary I-cache size
- Each packet incurs an identical set of I-cache misses
- The only workaround is bigger caches
- Remember very tight per packet time budget!
- Issue 2: Dependent read latency on big MAC or IP forwarding tables
- Example: 4 x 8 mtrie walk
- Assume tables do not fit in cache
- Lookup: 5.6.7.8.
- Read: root_ply[5], then ply_2[6], the ply_3[7], the ply_4[8].
- Each read will stall the CPU for ~170 cycles
- Every CPU cycle counts to get low cycle-per-packet and high packets-per-second!
- Example: 4 x 8 mtrie walk
Vector Packet Processing Operation
VPP does process more than one packet at a time:
- Grab all available packets from device RX ring buffer
- Form a frame (vector) comprising packet indices in received order
- Process frames using a directed graph of nodes
This approach results in a number of performance optimizations
- Fixes the I-cache thrashing problem so Issue 1 is solved!
- Mitigates the dependent read latency problem (e.g., for mtrie lookup). Issue 2 solved!
- Reduces stack depth and addresses D-cache misses on stack addresses
- Circuit time reaches a stable equilibrium value based on the offered load
VPP Graph and Graph Scheduler
The VPP network packet processing stack is built on a packet processing graph. A graph modular approach makes it easy to add new graph nodes to add functionality and address specific purposes. I fully expect the community of developers to be working on fido sub-projects on these feature graph nodes. They can write features to their heart’s content … standardized features, research new ones, write them as they write standards … evolve the possibilities of the internet afap without hassle of modifying a boatload of infrastructure.
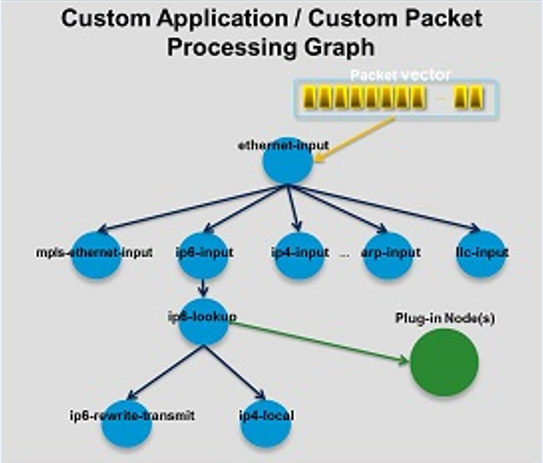
At runtime, VPP code grabs all available packets from receive (RX) rings to form a vector of packets. A packet processing graph is applied node by node (including plugins) to the entire packet vector. Graph nodes are small, modular and loosely coupled. This makes it easy to both introduce new graph nodes and relatively easy to rewire existing graph nodes.
A plugin can introduce new graph nodes or rearrange the packet processing graph. You can also build a plugin independently of the VPP source tree, which means you can treat it as an independent component. A plugin can be installed by adding it to a plugin directory. It’s the best thing for researchers, protocol developers, network designers since sliced bread. TBH, it’s really the desire from the original SDN work in Gates 104 as well.
VPP code can be used to build any kind of packet processing application. It can be used as the basis for a load balancer, a firewall, an intrusion detection system (IDS), or a host stack. You could also create a combination of applications. For example, you could add load balancing to a vSwitch. Therefore, the combinations of feature pipe-lines are completely deployment specific. Any kind of network function, any feature, any order running on any compute platform; L/M/S and 4-/2-/1-CPU-Socket. And if you want to on XS ones too, there are quite a few ARM 64-bit platforms.
The VPP graph scheduler is there to ensure that you always process as many packets as possible. The simple logic behind it is that as vector size increases, processing cost per packet decreases and I-cache misses are amortized over a larger set of packets. There are pros and cons depending on type of traffic and service being forwarded so, it’s not as trivial as “set as large as possible and forget.” Thankfully like Luke, you can “use the API.”
The VPP graph scheduler calculates in runtime a table vector size equilibrium following a simple algorithm:
- Start with vector size in equilibrium.
- Add a delay such as clock-tick interrupt or similar.
- Vector size increases but cost per packet decreases.
- Computation returns to the previous equilibrium vector size.
- The result is an optimal vector size and consistent per-packet latency.
VPP Instruction-cache Optimizations
CPU cache usage optimization and the increasing number of cache entry hits versus misses are among the most important factors reducing the average time to access instructions (code) and data from the memory. It is also fundamental for I/O intensive packet processing operations as outlined earlier. Most CPUs have different independent caches for instruction and data. VPP code optimizes the use of both.
VPP optimizes I-cache usage by making each VPP graph node process more than one packet. The first packet warms up the I-cache and all other packets hit in the I-cache. In addition, dedicated code is used to warm up the CPU branch predictor to avoid branch misses. VPP node dispatch functions typically comprise ~150 lines of code and easily fit in the Layer 1 I-cache in cases where they are not distributed across multiple VPP graph nodes.
VPP Pipelining
Many packet processing tasks require multiple dependent reads, usually including buffer metadata, packet data, a database entry derived from packet data (e.g., a forwarding table lookup), and rewrite information. Context (or packet) vectorization means that nodes can hide dependent read/write latency by breaking up the required work into pipelined stages. Applying pipelined stage processing to an 8-8-8-8 IPv4 trie lookup results in two operations executed in sequence: (1) read a previously-prefetched trie ply, (2) use the read results to prefetch the next ply.
Schematically, nodes process contexts as follows. In the following table, C0…C4 comprise 5 packet contexts.
```
Stage 0 C0 C1 C2 C3 C4 C5 x x x
Stage 1 x C0 C1 C2 C3 C4 C5 x x
Stage 2 x x C0 C1 C2 C3 C4 C5 x
Stage 3 x x x C0 C1 C2 C3 C4 C5
```
Analyzing it in terms of concurrent execution order:
- Stage 0 processes C0.
- Stage 0 processes C1. Stage 1 processes C0.
- Stage 0 processes C2. Stage 1 processes C1. Stage 2 processes C0.
- Stage 0 processes C3. Stage 1 processes C2. Stage 2 processes C1. Stage 3 processes C0.
- Etc.
This way VPP can handle large MAC, IPv4, and IPv6 forwarding tables as well as large network address translation (NAT) or any other binding and forwarding tables (e.g. IP4-over-IP6-softwire, security white-/black-lists, access control filters) with minimal/almost undetectable performance impacts. This is clearly visible in high-scale vNet benchmark results reported in the benchmark sections in this paper.
The latest testing being done with the VPP code sitting in the FD.io repo, we expect to see up to 720Gbps of IMIX from 4-CPU – Socket computer. At this point NICs, PCIe and CPU uncore are the bottlenecks, and we’ve found a lot of bugs and marketing numbers in commodity NICs, but the industry is working out the issues. VPP is really the first forwarder to exercise the limits of the NICs. That’s an expectation of 180Gbps per socket, let’s see what we get. Add another 4 sockets to become an 8 socket computer; we are targeting well over 1Tbps from a COTS computer. That’s reaching OMFG-type numbers. And the VPP code is not completely utilizing the CPU cores, with lots of cycle capacity to keep developing more network or compute functionality onto the very same sockets.
So, if we put this all together, we can see two things: 1) VPP has the raw packet handling capacity to work well beyond 100GbE without breaking a sweat; and 2) the efficiency of VPP is such that it provides a LOT OF the CPP headroom to do some really interesting and useful packet processing. Given VPP is multi-thread (and safe), multi-core; it’s extremely close to linear scaling when adding more cores – it follows Amdahl’s law of course (can’t be faster than the slowest element) and multi-core speedup is almost linear. This also means, from a compute perspective; you have deterministic IO/PPS and can place VPP and other compute workloads efficiently.
VPP Vignettes
VPP performance data points (measured)
Hopefully you’ve read this far and even taken an interlude to check out the code. You might find it nicely written and it all makes perfect sense, seems indeed like the right way forward. But does the VPP code actually work and does it do all of those nice and cool things? What does it actually mean to raw bit flinging that VPP is fast and efficient when running on general purpose compute nodes.
Well, let’s look at some benchmarking data, the actual measured test data. We start with
- VPP packet throughput: some baselines of VPP packet throughput (Non Drop Rate, NDR), and CPU system utilization (Cycles Per Packet, CPP) while VPP is doing some meaningful work – IPv4 and IPv6 routed forwarding with large forwarding tables. We then add some stateless security: access-list filters and white-lists.
- VPP packet delay soak test – 7 days of work: VPP packet delay over a long-ish period, a week of non-stop work forwarding packets, no lunch breaks, no weekend.
- We finish the conversation with VPP binary API programming rate – a speedy one.
Clearly we could share here many more areas and data points, including CPP efficiency per processed packet per coded packet processing function, PCI3.0 connection utilization efficiency, x86_64 L1, L2, L3(LLC) cache utilization efficiency, memory lanes utilization efficiency and so on. Not to mention measured data points for other CPU architectures like Aarch_64 and Power8, the number of combination is bit overwhelming to a human reader, and we are running into a risk of exceeding attention span of the most patient readers. Hopefully you’re still with us. Hence we are not going to do this in this initial blog, which sole purpose is to warm you up to the idea of software based Internet infrastructure platform like VPP. We want everyone to get familiar with the basic properties and fundamentals of FD.io VPP, before unveiling the full picture. The full picture is going to take more than one blog, clearly. J
Let’s start the speed-and-feeds Fest then…
VPP performance benchmarking approach
How do you test performance of a piece of software that claims to be the fastest optimized software for packet processing on computers? Well, we thought, we are busy, we don’t have much time to invent new benchmarking approaches, so we start with applying best practice of testing huge effing routers, like the one below, and see what we get.

And that’s exactly what we did. And we were surprised. We were ACTUALLY nicely surprised. Because suddenly SUT (System Under Test) wasn’t the computer with VPP running on it, it was our hardware routing tester IXIA. Running RFC2544 and RFC2442 tests, we were actually testing IXIA. And the first rules of measuring while testing a system of many components is to make sure that it is your target you’re measuring, not other devices or systems involved. We fixed that by working closely with our hardware routing tester supplier (IXIA) and arrived to the configuration that actually worked and tested computer plus VPP. The interesting tidbit is that a single computer, was requiring many many 10GE or 40GE ports in IXIA chassis. We were filling the IXIA chassis J. Here goes the high-level detail.
We tested FD.io VPP on two different computers, 2-CPU and 4-CPU, looking like these specs and these photos:

 Both computers running the same open-source software stack:
Both computers running the same open-source software stack:

VPP isn’t as pretty as a real router, as it is software, and you can see it in FD.io VPP git repo. But, only reading skills required if you want to know WHAT it does – it’s commented – search for functional spec references – the IETF RFCs. C-code reading skills required if you want to know HOW it does it, but in a nut-shell it runs CPU architecture optimized C-code. C-code writing skills required if you want to know WHAT it actually does to your packets.
All measured data points are from benchmark tests performed in Cisco labs in San Jose.
The basics – Ethernet L2 MAC switching
Starting with the basics – benchmarking Ethernet L2 MAC switching performance – across simple virtual network topologies: NIC-to-NIC, NIC-to-VM and VM-to-VM. Benchmark tests were performed back in September 2015 by EANTC, and compared VPP and OVSDPDK throughput. Configuration was the simplest you can imagine, single core used for running all VPP or OVSDPDK threads. Results are shown in the slide below. And they speak for themselves. VPP wins with larger MAC forwarding tables. Expected. No surprises.

VPP packet throughput
The testbed topology with the UCS C240M4 2-CPU 120GE compute node looks like this.
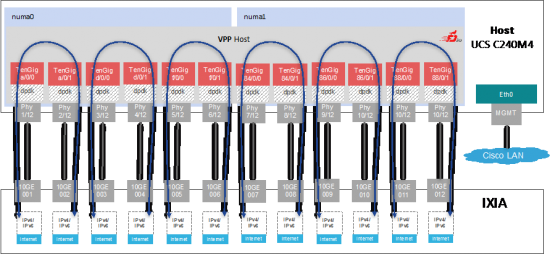
Nothing special you say, bunch of 10GE ports hooked up together. The extraordinary thing is the quantity of ports and the aggregate bandwidth – 12 of IXIA 10GE ports pumping packets at linerate into 2-CPU compute node, that is running VPP code and processing packets at rate. In this case, it is actually 120GE linerate, as we are not exceeding any of server hardware I/O limits, that is there is enough PCIe3.0 bandwidth and per NIC capacity (each NIC has packets-per-second and bandwidth limits) to support IMIX line-rate. (IPv4 IMIX = sequence of 7x 64B, 4x 570B, 1x 1518B; IPv6 customIMIX = sequence of 7x 70B, 4x 570B, 1x 1518B; all packet sizes are Ethernet L2 untagged).
Here are some sample benchmark results:
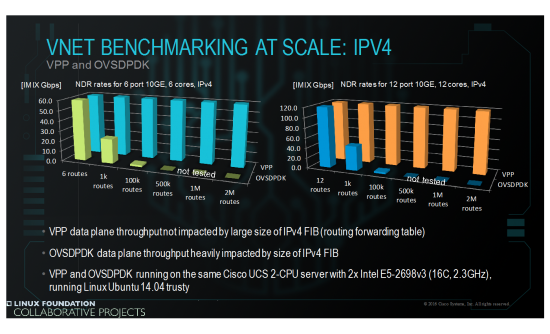
VPP and OVSDPDK running with large IPv4 routed forwarding tables
VPP does 120GE IMIX linerate at 2 Million IPv4 routes
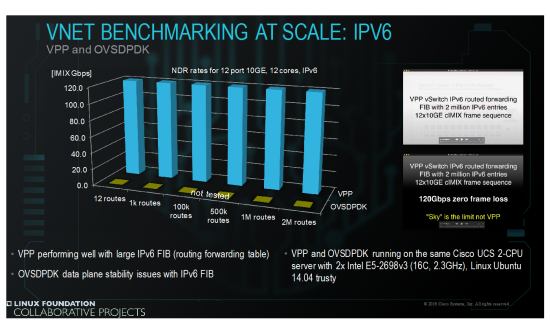
VPP running with large IPv6 routed forwarding table
VPP does 120GE cIMIX linerate at 2 Million IPv6 routes
OVSDPDK not tested for stability reasons
 Let’s look at the four socket x86_64 server – the testbed topology with the UCS C460M4 4-CPU 720GE (18x 40GE) compute node looks like this.
Let’s look at the four socket x86_64 server – the testbed topology with the UCS C460M4 4-CPU 720GE (18x 40GE) compute node looks like this.
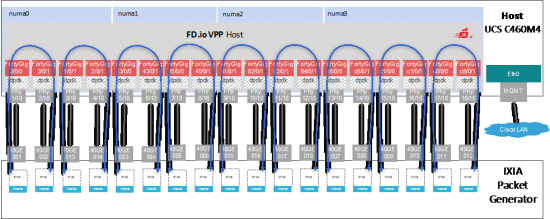
Again, nothing extraordinary, bunch of 40GE ports hooked up together. The extraordinary thing is the quantity of ports and the aggregate bandwidth – 18 of IXIA 40GE ports pumping packets at high rate into 4-CPU compute node, that is running VPP code and processing packets at rate.
Here are some sample benchmark results:
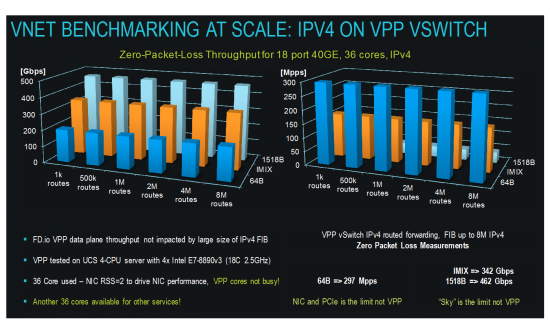
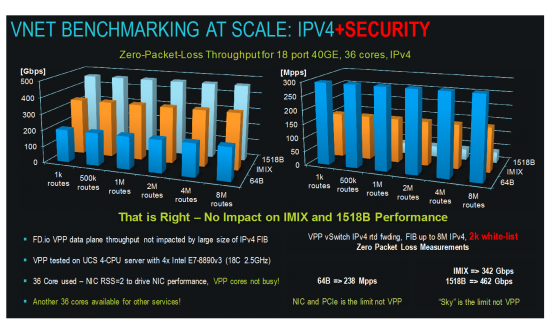
VPP running with large IPv4 routed forwarding tables, up to 8M IPv4 routes
VPP does 297Mpps 64B and 462GE 1518B linerate
Ok, put that into perspective for a second. Back in 2004 a router I was co-architect of, the CRS-1 (aka HFR) was a 16 @40Gbps LC, 7’ chassis router (see pic of router porn above). We just flung 12 LCs worth of traffic in a 2 RU computer … roughly 10 years later. I love technology advancements. Also note that this test went all the way to 8M routes in the FIB. The table size just doesn’t matter for IP, L2, etc.
Adding stateless security (VPP iACL nodes or VPP white-list/black-list nodes in the packet processing graph of nodes) does not make any difference to system throughput for IMIX packet size.
 But clearly, there is no free lunch – the white-list has a CPP cost. CPU cores are doing work filtering packets, and the amount of work, the CPPs, is measured by VPP code and can be read using binary API and also with VPP CLI per outputs here.
But clearly, there is no free lunch – the white-list has a CPP cost. CPU cores are doing work filtering packets, and the amount of work, the CPPs, is measured by VPP code and can be read using binary API and also with VPP CLI per outputs here.
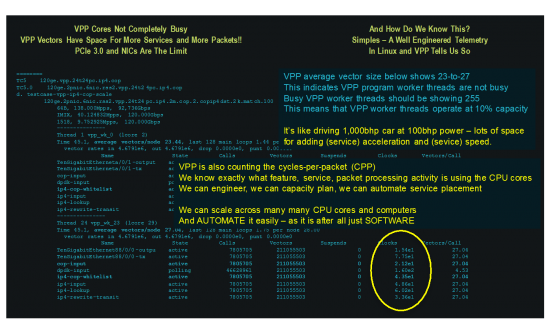 The CPP cost is measured for every VPP node, every feature and function implemented and running in VPP graph of nodes. We always note what is the actual real-time cost of processing packets; the actual cost of network service expressed in CPPs. What this means is that if flinging 462 Gbps of packets takes 10% of the capacity of the VPP worker thread and 90% of the time for work is left over for feature work … there’s a ton of headroom for features before we see any degradation. Also note in the benchmarking that all cores aren’t used. In the V4|6 tests only 36 cores are being used for 462Gbps and 36 are free for other work. Add ACLs and still only 36 core in use w/ 36 spare. Biz economists should be smiling at this point.
The CPP cost is measured for every VPP node, every feature and function implemented and running in VPP graph of nodes. We always note what is the actual real-time cost of processing packets; the actual cost of network service expressed in CPPs. What this means is that if flinging 462 Gbps of packets takes 10% of the capacity of the VPP worker thread and 90% of the time for work is left over for feature work … there’s a ton of headroom for features before we see any degradation. Also note in the benchmarking that all cores aren’t used. In the V4|6 tests only 36 cores are being used for 462Gbps and 36 are free for other work. Add ACLs and still only 36 core in use w/ 36 spare. Biz economists should be smiling at this point.
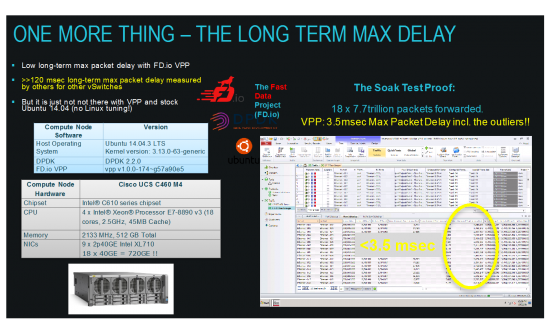
VPP packet delay soak test – 7 days of work
Talking about soak-testing – we did that with 8M IPv4 routes – pounded at 18x 17Mpps for one week. Here are the results:
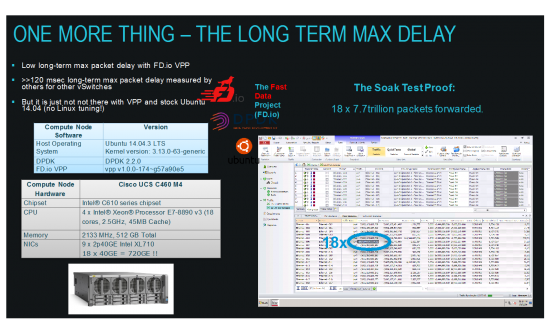 That’s right – 18 x 7.7trillion packets forwarded – and maximum packet delay registered by IXIA tester is less than 3.5msec. And this includes all outliers. Not bad for a modern x86_64 computer with Linux. Running specs as before – the 4-CPU server (UCS C460M4).
That’s right – 18 x 7.7trillion packets forwarded – and maximum packet delay registered by IXIA tester is less than 3.5msec. And this includes all outliers. Not bad for a modern x86_64 computer with Linux. Running specs as before – the 4-CPU server (UCS C460M4).
VPP binary API programming rate
What if we tell you VPP is faster than HW routers for programming the forwarding table, the FIB? Well, as it happens, it actually is. (though removing the requirement for an asic driver helps or some might say is cheating with the comparison). Here is a raw output from a running VPP code instance benchmarked with 8 Million IPv4 entries, while programming those entries into the FIB on the 4-CPU UCS460M4 server with 18x40GE interfaces:
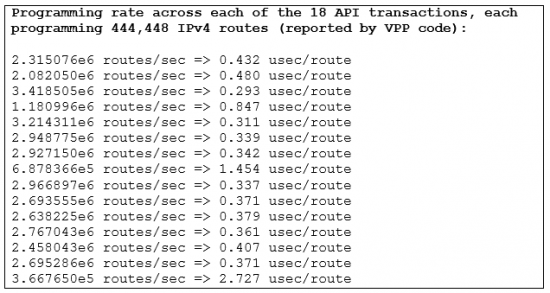
Assuming 0.408 usec/route, converging all of the Internet table (Internet BGP table size as of 21 Mar 2016 was 600612 per http://www.cidr-report.org/as2.0/) would take 245 msec. LESS THAN A QUARTER OF SECOND. Mic drop.
Next steps in benchmarking: VPP and CPU systems
Here is a teaser of a few things we are testing and exploring with VPP running the servers and computers, running them hard, sweating on processing packets:
- PCIe3.0 sub-system benchmarking of 8x and 16x lanes, switching and DMA, DCA.
- CPU microarchitectures efficiency, core and uncore subsystems.
- CPU cache and memory coherence.
- Multi-core x86_64, AArch64, other – for L/M/S/XS deployments.
In other words squeezing the packet processing efficiency from commodity CPU platforms and their sub-systems that themselves are networks of connected things. Making networking where the cool kids hang out. Getting a huge helping of Internet, to everyone.
The Consoritum
FD.io Overview
While VPP is remarkable technology, it is only part of the solution for the industry, so this is where FD.io comes in. The FD.io Project is a Linux Foundation project to provide an IO services framework for the next wave of network and storage software. In another blog we’ll talk about using VPP for storage subsystems. The design of FD.io is hardware, kernel, and deployment (bare metal, VM, container) agnostic.
The FD.io project parses IO services into three layers:
- I/O – the movement of packets to/from hardware/vHardware to cores and threads
- Processing – classify, transform, prioritize, forward and terminate actions
- Management agents – controlling and managing I/O processing

Within the FD.io framework, VPP fits into the Packet Processing layer. This layering and the modular architecture of the project allow you to quickly build upon existing modules or easy add new ones. VPP heavily uses DPDK today. The reason being, VPP doesn’t want to be in the NIC support business.
Why Another Consortium?
We are all suffering from OpenSource Foundation Fatigue. This being said, there was a problem in the area of opensource data plane efforts, including the Linux kernel. There was a lack of:
- support for diverse/custom hardware
- portability across compute platforms
- optimal use of compute microarchitectures
- network level instrumentation
- Few debugability features
- Few if any Statistics/Counters exposed
- basic Governance of the community
- leads to unpredictable system behavior
- consideration of the data plane for mid-point forwarders vs solely hosts
- performance and scaling
- features and feature velocity
- automated end-to-end system testing frameworks
- leads to unpredictable system behavior
Therefore, to solve these issues: Fd.io was created. There really are no other efforts around dataplane technology that really covers all these bases.
Continuous Performance Lab (CPL)
An aspect of the FIDO community is that at the outset given the focus on performance and scaling the group included support for a continuous performance lab. It includes another contribution we made that is a fully automated testing infrastructure. It tests both the data plane and the northbound APIs. The goal is to support continuous verification of code and features for both functionality and performance. This will catch code breakage and performance degradations before code/patch review by the community. This full framework was used for generating and testing by multiple industry partners and we’ll be standardizing it at the IETF and open sourcing the whole thing.
Is there room for more projects?
It’s expected that the vast majority of the community will focus on writing feature (graph nodes). There’s plenty of room the community to develop new and extend functionality. As well as have commercial feature nodes as well. Examples include: Load balancers, Firewalls, Intrusion Detection, Additional hardware accelerators, more RFC support (e.g. OAM, BFD), spanning tree, Deep packet inspection, more test tools, support your favorite SDN or P4, etc. There’s a lot done already but there’s always more to do. A great example is one of telemetry. You’ll find in the code support for IPFIX v10, binary export and other manners of streaming data out of VPP. Features can be written to export different combinations of data to enable the reactive part of SDN.
What’s currently supported
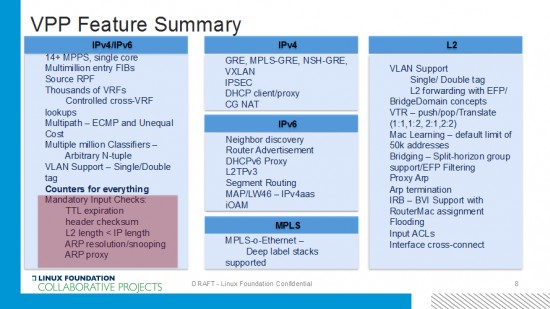
Out of the box, VPP has more than all the basic functionality to be a deployed virtual switch and router. The highlighted box in the lower left around the mandatory input checks seems like basic functionality, but VPP is the only available forwarder that includes them in race-track testing and everyday functionality. As well as counters, counters, counters…. Key to note is all the IP/MPLS features and encapsulations. Indirect nexthops was just added which is key to be a big-boy router.
What also become critical is being able to debug and develop high performance code so we also contributed a developer environment and toolset to help the community write highly performing features. It’ll give all sorts of information down to impact of CPP.
FD.io & VPP Resources
The best part of open source projects is the opportunity to work with the code. In the open. You can get instructions on setting up a dev environment here and look at the code here. Finally check out the develop wiki here. There are a ton of getting started, tutorials, videos, docs on not only how to get started but how everything works. Even videos of Dave Barach. Please don’t mind the choice of language; we don’t let him out of his cave very much.
The code is solid and completely public and under the Apache license. We’re already using an “upstream first” model at Cisco and continuing to add more features and functionality to the project. I encourage you to check it out as well as consider participating in the community as well. There’s room for newbies and greybeards. We have a great set of partners and individuals contributing to and utilizing FD.io already in the open source community and a good sized ecosystem already emerging. Clearly from this conversation you can tell I think VPP is a great step forward for the industry. It has a great potential for fixing a number of architectural flaws in current SDN, orchestration, virtual networking and NFV stacks and systems. Most importantly it enables a developer community around the data plane to emerge and move the industry forward by having a modular, scalable, high performance data plane with all the goodies; readily available.





It is exhilarating and invigorating to see the industry-leader mastering the evolution of its networking footprint, by giving the internet a modern, cloud-ready, data-plane stack.
I am glad we have the cloud-infra locked-tight.
Coming from user:space/perspective, I’m looking forward to using/running FD.IO with Honeycomb or other SDN agents, to automatically deploy VXLAN-based Multi-tenant solutions.
Interesting stuff..so how would you compare this to DPDK ?
It’s built on DPDK and we’ve worked deeply w/ the DPDK team(s) to improve that technology. It’s a critical piece of the puzzle to avoid the whack-a-driver problem and get the most out of SOCs.
What Dave Barach, Dave Ward an Maciek have released is a truly gift to the world and its impact to the industry cannot be overstated. I am also delighted to see that Cisco finally “has got it” and is finally sensing the tectonic shift that is underway in networking.
Excellent summary. Thank you for your great effort.