
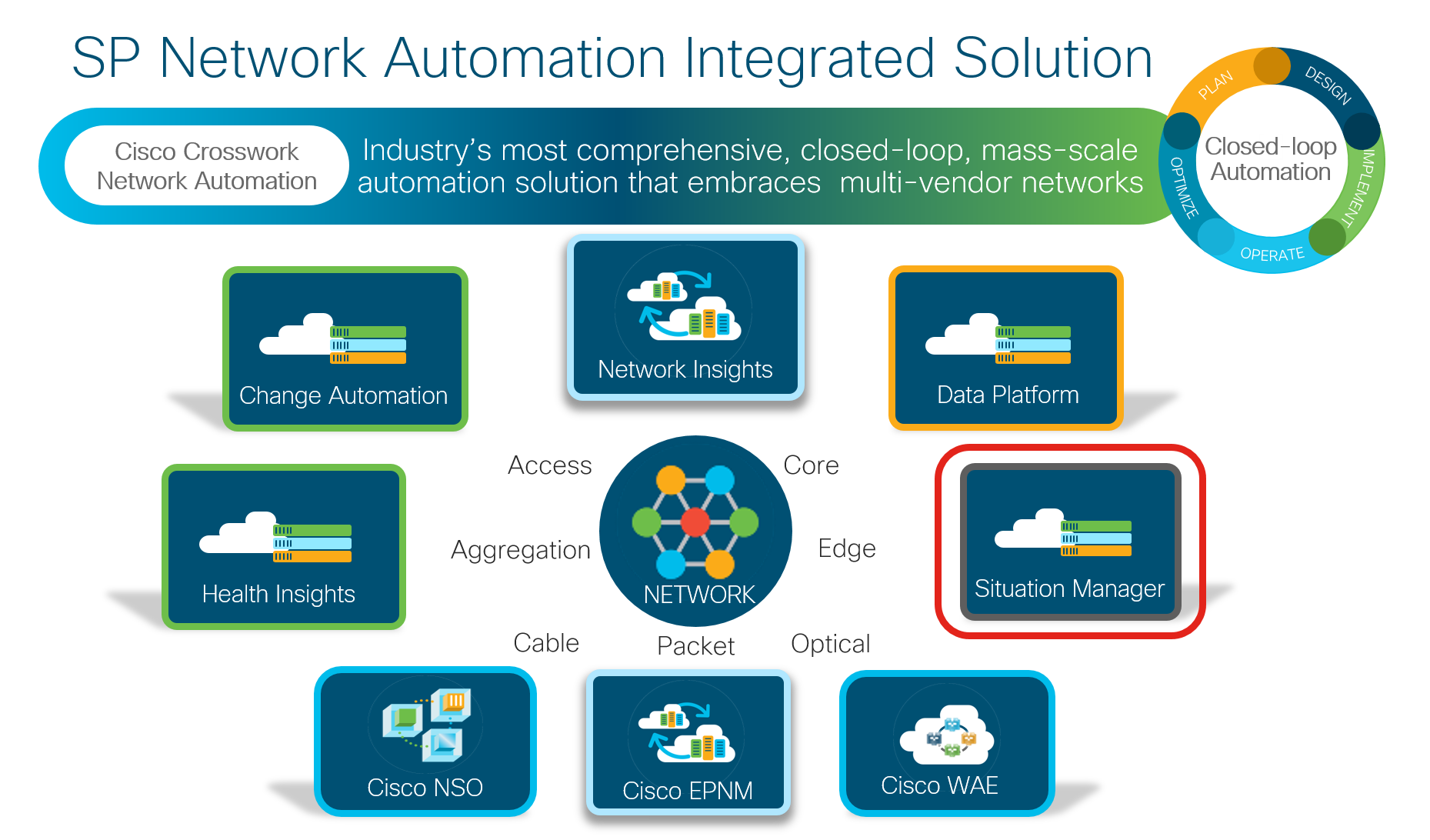
In February, Cisco announced its latest innovation – Cisco Crosswork Network Automation – a new network automation portfolio for Service Providers. Read Jonathan Davidson’s blog for an overview to understand our comprehensive approach to enabling a closed-loop, mass-scale automation solution. Follow this multi-part blog series over the coming weeks to learn more about each of the five new pillars in the Cisco Crosswork portfolio.
In this blog series, we have been providing more detail on the five new pillars of the Cisco Crosswork automation solution. So far, you have learned about Cisco Crosswork Change Automation and Cisco Crosswork Network Insights. Today, let’s take a closer look at Cisco Crosswork Situation Manager – a new tool, which helps network operators take control over their data firehose, pinpoint root causes automatically and transform how operators collaborate on anomalies in the network.
Networks generate noise, lots of it. Operators have learned this simple truth over years of scaling and growing their infrastructures. Every device, tool, and system generate a near constant stream of events, log messages, alerts, and notifications. It isn’t uncommon for some environments to generate hundreds of thousands of events in a single day. The constant growth of network scale and features is only causing this number to increase. Upcoming technologies such as 5G are driving scale to previously unimagined levels, which also means a corresponding explosion in the amount of data coming from these new network deployments.
Are all of these events and alarms important? Absolutely not. In times of a network incident, it isn’t uncommon to see a list of thousands of bright red events in an operations display. What is worse is that all of these compete for an engineer’s attention. This constant bombardment of non-actionable events leads to a condition we like to call Event Fatigue. Event fatigue is a real problem in network operations because it devalues operational data over time.
What is a perfectly natural response to dealing with an annoyingly loud noise? Putting in a pair of earplugs. For a network operator, this means ignoring the data creating the overload, simply because there is too much noise and not enough signal to be actionable. No doubt there is valuable information buried in the tool, but during a rapid response to a situation, it just doesn’t make sense to wade through thousands of events to find the few that explain what really happened, and where to direct your response.
More Signal, Less Noise
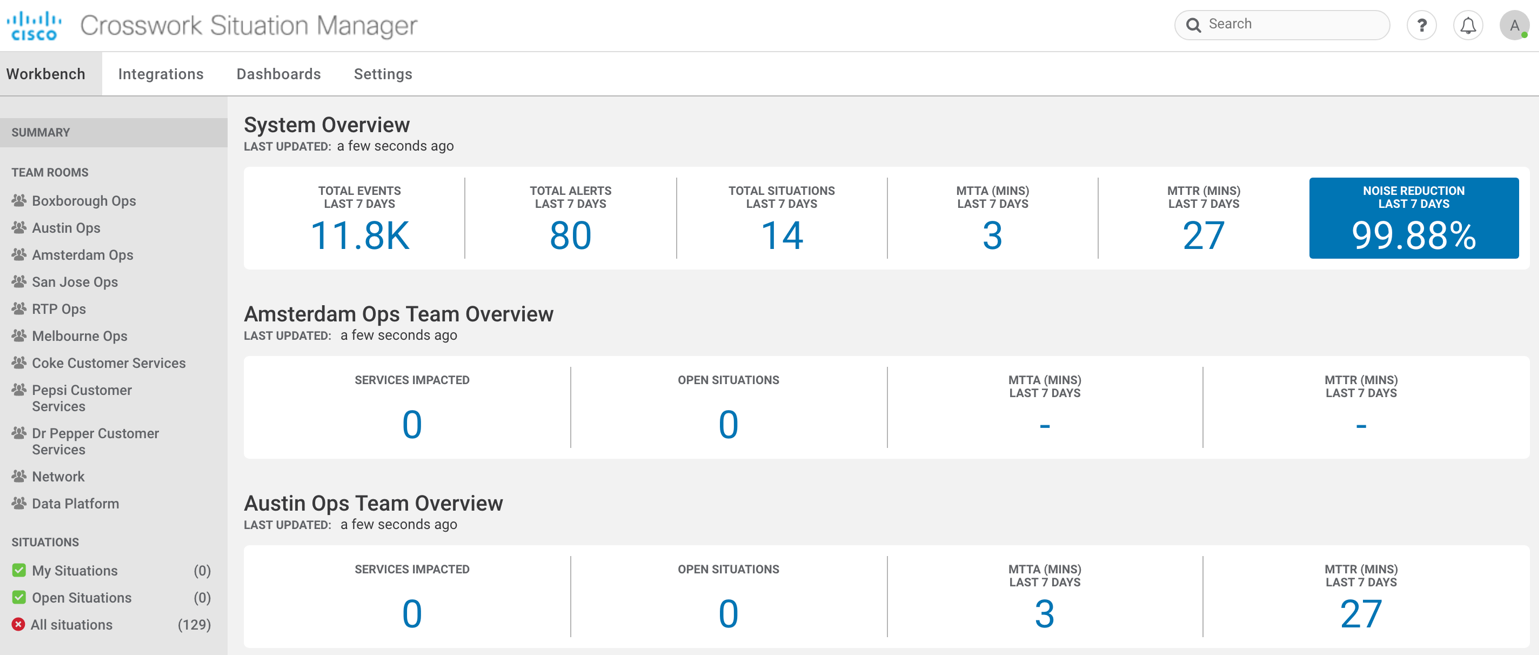
Figure 1 – Reducing noise with Situation Manager
The first step along a path to addressing event fatigue is to simply reduce the volume of noise in the event streams – but in a smarter way than just ignoring things entirely. Just because an event is reported doesn’t necessarily mean that it should be presented to an operator. Before the event can be useful, several types of analysis can algorithmically determine how useful the event really is. For example, many events may be duplicates of one another or simply lack enough information to be useful. Situation Manager uses advanced algorithms to determine when events contain enough information to be useful, and more importantly when events don’t. Events that don’t add value to finding a root cause can be safely archived for forensics, but not demand attention from operations staff.
Connecting the Dots
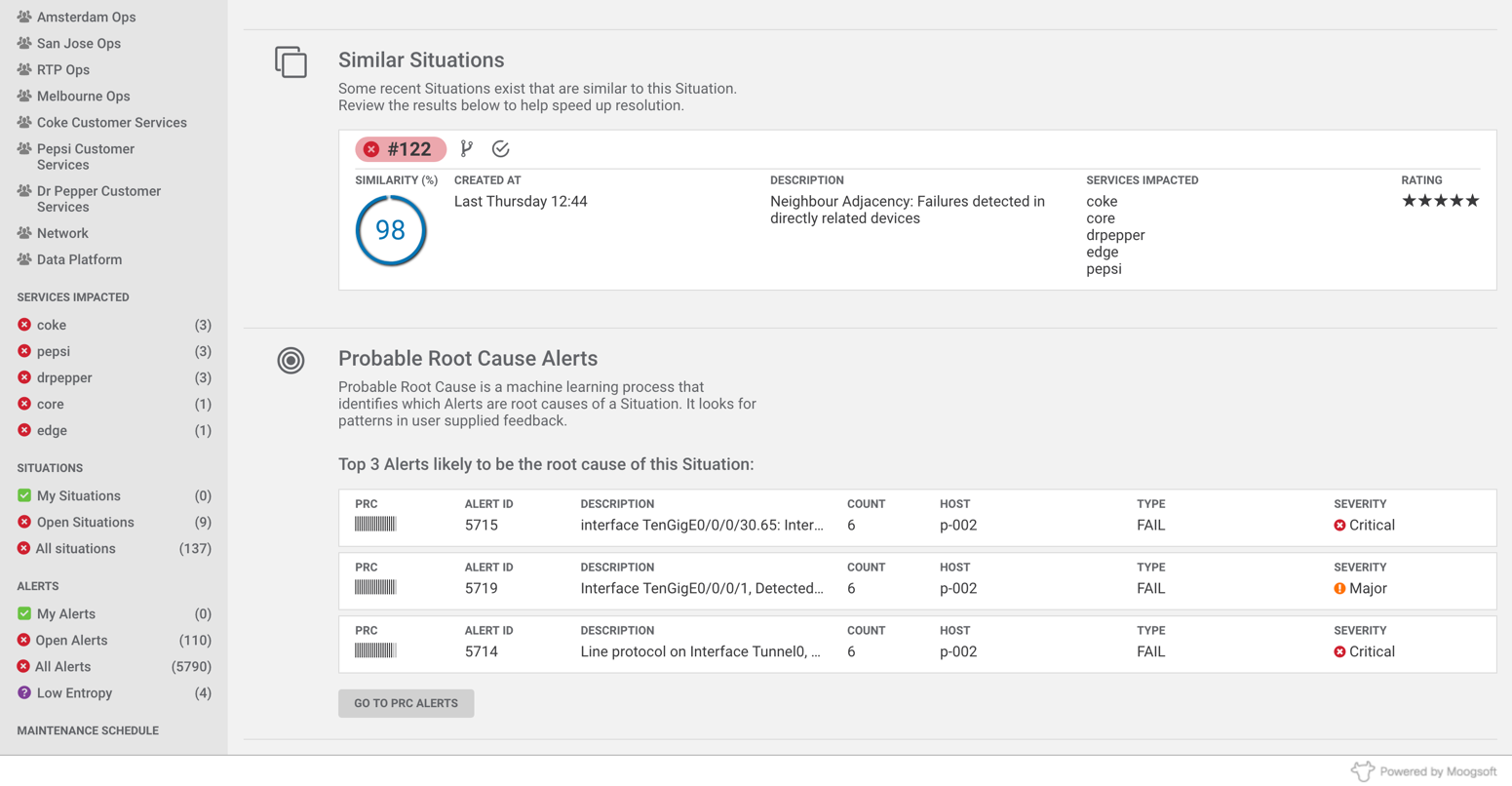 Figure 2 – Automatically identifying root causes with Situation Manager
Figure 2 – Automatically identifying root causes with Situation Manager
Once the volume of data is under control, the next step is to identify the real root cause of the problem. In a highly scaled operations environment, finding the true root cause of an issue is difficult because of the sheer number of devices and systems each reporting data upstream. These individual data sources are uncoordinated, seeing and reporting facts about only their small part of the infrastructure. An engineer dealing with an outage often has to look across many different data sources to manually find and group related events, wasting critical time during the process.
Situation Manager dramatically reduces the time-to-know by using natural language processing algorithms to find relations between events in the system. These techniques automatically group related events together, regardless of where or how they were reported. Operators using Situation Manager no longer see uncoordinated streams of events, but now are presented with clusters of related events. Once clusters of related events have been identified, Situation Manager then uses machine learning techniques to identify what the most likely root cause of the issue is. Over time and with operator feedback, the system begins to train itself to weed out false root causes.
Outages are Better with Friends
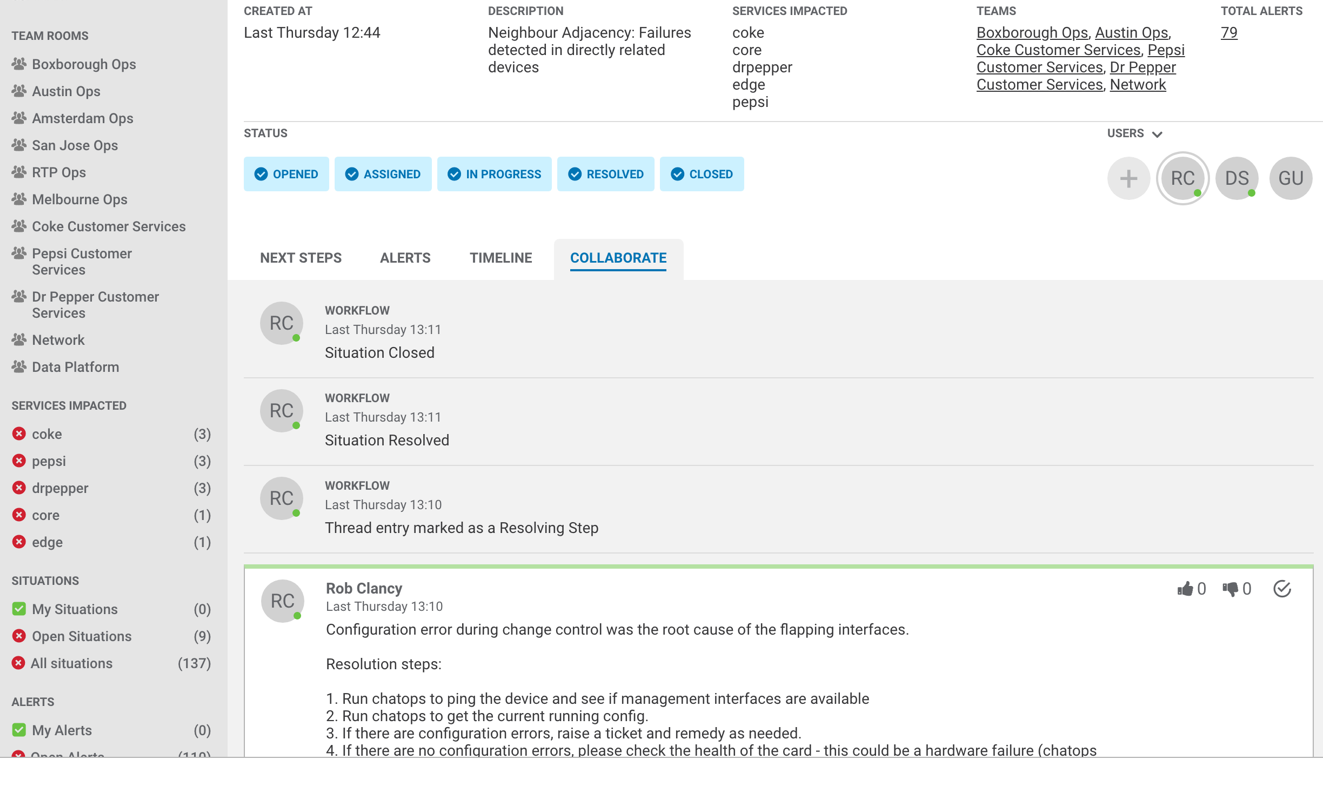 Figure 3 – Collaborating on incidents as a team in Situation Manager
Figure 3 – Collaborating on incidents as a team in Situation Manager
We’ve seen how Situation Manager reduces noise in the event stream, groups related events together, and uses machine learning to identify root causes. An area we haven’t yet examined is looking at how engineers work together to solve incidents and outages. Today’s operations organizations are composed of many different teams all with different areas of expertise. Quite often these groups are spread out across multiple geographic locations as well. This means that for operational tools to be successful, communication and collaboration features are often just as important as the underlying algorithms. Many of us have painful memories of overloaded conference calls with different teams trying to describe their view of what is going on during an incident, convincing teammates to look at various pieces of data, and trying to copy and paste links to graphs or other information we think could make or break the case. This chaotic collaboration dramatically extends the time needed to resolve an incident.
Over the past several years, we’ve seen social and collaboration technology break down barriers and make communication gaps an afterthought. Teams can now be distributed, but share information just as well as in person. By automatically creating dynamic workspaces where engineers can work problems together as a collective team, Situation Manager makes incident resolution a process in which anyone can participate. Information is available in a central location where discussions can be focused on just the cluster of events at hand. Operators can look through a list of open situations to easily understand what is going on globally, and then decide what they need to work on. Once inside a situation workspace, operators have a single location to share information and discuss next steps. Since this data is stored over time, onboarding new engineers is as easy as reading the history in the workspace.
The five new pillars of the Cisco Crosswork automation solution enable Service Providers to accelerate their journey to a fully self-healing infrastructure. Look for more blogs in this series coming soon.




