
The challenge
In cyber security, we all know what alert fatigue is, and we know there is no silver bullet to get out of it. In our previous incarnation, our product was guilty as well. Who wants to go through 20,000 alerts one by one? And this was just from one product.

Building a detection engine
This article is part of a series in which we will explore several features, principles, and the background behind what we consider to be the building blocks of a security detection engine within an extended detection and response (XDR) product.
In this first article, we’ll start with alert fatigue and how we avoid it through the creation of intelligent alerts.
To manage alert fatigue, we are aware of several traditional approaches. “We only pay attention to High and Critical alerts,” some have said. That certainly helps, but at the expense of bringing more problems aboard. Apart from missing a large chunk of the sometimes-notable message that the security product is trying to convey, the “inbox” of the product becomes a dump of unclosed alerts.
“In your next release, could you add elaborate filters and checkboxes so that I can mass close those alerts?” some have asked. We tried this way, but we found ourselves amidst views containing tables within tables, a very baroque system with the delicacy and simplicity on par with the space shuttle.
“We gave up and got a SIEM and a SOAR!” we heard from others. That is all fine, when one wishes to move their SOC staff from security specialist roles to engineering integrators.
To sum up, we observed that in any case, we were really trading one issue for another. Rather than trying to manage the alert fatigue problem, we switched our approach to avoiding it in the first place. We introduced Alert Fusion.
Alert Fusion
In the Alert Fusion system, the basic unit of work is the alert. Rather than having one alert per each security event, we build the alerts intelligently, to mimic the unit of work of the security analyst.
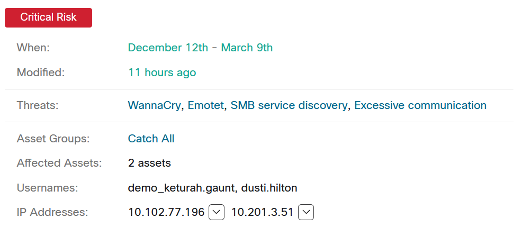
Here is an example of such a unit of work. It covers two assets, having detected an identical set of threats on both. It’s easy to see that WannaCry, SMB service discovery, and Excessive communication likely go together. While remediating these infections, one might want to have a look at the Emotet infection as well. Altogether, neglecting this this unit of work is considered a critical risk, so it easily makes it to the top of the alert list.
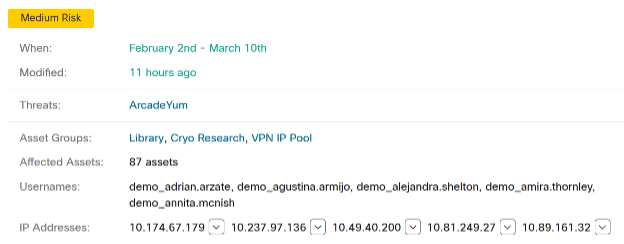
The second example has a single ArcadeYum Threat spanning a larger base of 78 assets. It is one of those pesky browser-altering, additional software promoting things that one might want to eradicate en masse, rather than one by one. Admittedly, it isn’t as problematic as WannaCry though, so it is considered a medium risk.
Altogether, these two alerts cover nearly a hundred significant security events and many more contextual ones. Apart from removing the need for manual correlation, we can immediately discern the nature, the breadth, and the depth of the risks presented.
To sum up, an alert serves to collate findings that the analyst might want to solve in ensemble, either by working on it as an incident or getting rid of it due to reasons of his choosing. To prioritize their work, an alert has a risk, and the alerts are ordered using this value.
The risk, as well as the grouping, are determined automatically by the system using what it knows about the detections. Now, let’s dive deeper into the basic ingredients in the cookbook: the threats and the assets.
Threats
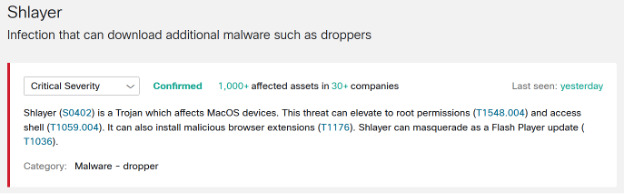
A threat is anything we can name as a security risk. In this example, we feature Shlayer. It is important to note that we express threats in the language of threat intelligence and risk management – “what” has been detected as opposed to the technical language of detection means – “why” was it detected. We’ll cover the exact means of detection in a later article. For now, let’s assume that we somehow detected it.
A threat has a severity, in this example it is critical, which serves as a basis for the risk calculation. Threats come with factory default severities which be changed freely to suit the threat model of each customer. For example, some customers may not care as much about crypto mining on their assets when compared to other customers.
We realize that detection methods are not infallible, especially in the world of machine learning. So, we assign a confidence value when a threat is detected. Currently, it can be either high or medium. The latter means the detector is not quite sure of the detection, so the risk is dialed down.
Assets

Similarly, we organize assets into Asset Groups that bear a business value. The organization is up to the customer and their threat model. Some customers have more diverse needs, while others have more of a flat structure. Where possible, we offer an educated guess of the default value for an Asset Group. For example, servers get a high value, while guests get a low value. In any case, the values can be changed freely. The medium business value has no impact on the risk, while others will either increase or decrease it accordingly.
Reactive system
In summary, we see that Alert Fusion presents alerts which act as units of work and are prioritized by their risk, calculated from customer-applied settings such as threat severity and asset value.
It wouldn’t be realistic to expect that all configuration, if any, was done to the system upfront. For example, a detection on a guest network might make one realize that the business value of this asset group might need to be lowered. So, we provide the option to tweak alerts on the fly. We support a reactive workflow model.
The existing alerts may be reorganized at any time by turning a few knobs, namely the threat severity and asset value. This gives the option to explore safely. When not satisfied with the change, simply turn them back, rinse, and repeat.
Wrap-up
So, have we tackled alert fatigue successfully? As the saying goes, time will tell. It is already beginning to do so.
Since this system was introduced in 2020, we have seen a significant reduction in alerts per customer, usually in a few orders of magnitude. Our UI does not have to work as hard, in terms of checkboxes, pagination, and filtering. Consequently, more customers reach the nice-to-be-in place of a zero-alert inbox, where 100% of the alerts have been viewed and interacted with.
We’d love to hear what you think. Ask a Question, Comment Below, and Stay Connected with Cisco Secure on social!
Cisco Secure Social Channels





