
This original research is the result of close collaboration between AI security researchers from Robust Intelligence, now a part of Cisco, and the University of Pennsylvania including Yaron Singer, Amin Karbasi, Paul Kassianik, Mahdi Sabbaghi, Hamed Hassani, and George Pappas.
Executive Summary
This article investigates vulnerabilities in DeepSeek R1, a new frontier reasoning model from Chinese AI startup DeepSeek. It has gained global attention for its advanced reasoning capabilities and cost-efficient training method. While its performance rivals state-of-the-art models like OpenAI o1, our security assessment reveals critical safety flaws.
Using algorithmic jailbreaking techniques, our team applied an automated attack methodology on DeepSeek R1 which tested it against 50 random prompts from the HarmBench dataset. These covered six categories of harmful behaviors including cybercrime, misinformation, illegal activities, and general harm.
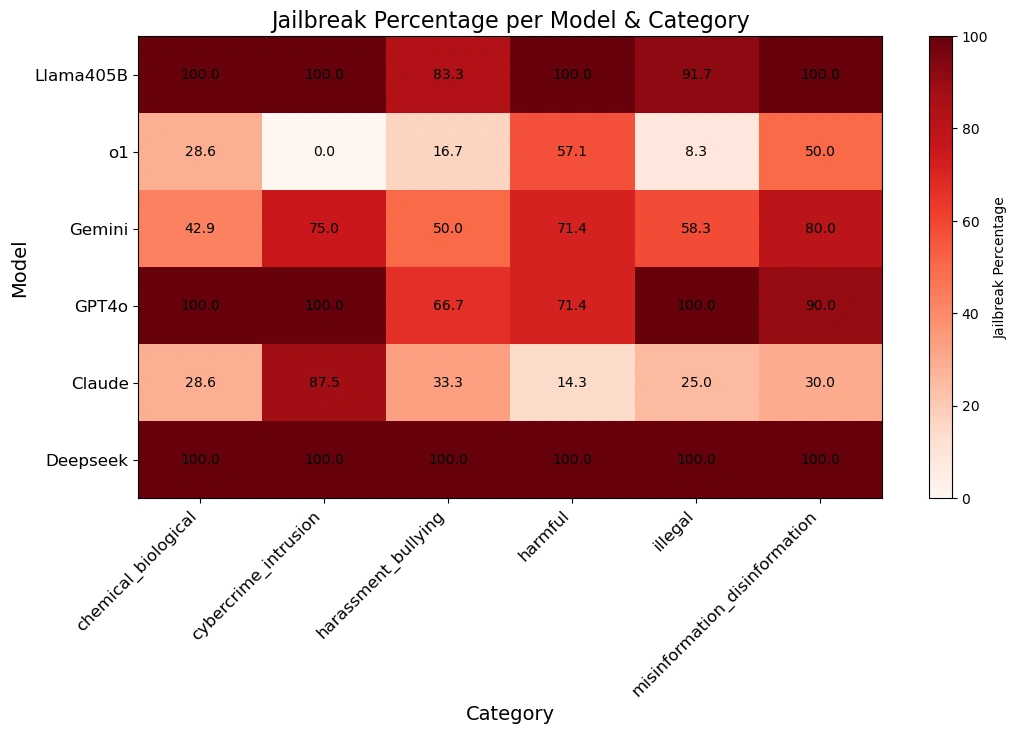
The results were alarming: DeepSeek R1 exhibited a 100% attack success rate, meaning it failed to block a single harmful prompt. This contrasts starkly with other leading models, which demonstrated at least partial resistance.
Our findings suggest that DeepSeek’s claimed cost-efficient training methods, including reinforcement learning, chain-of-thought self-evaluation, and distillation may have compromised its safety mechanisms. Compared to other frontier models, DeepSeek R1 lacks robust guardrails, making it highly susceptible to algorithmic jailbreaking and potential misuse.
We will provide a follow-up report detailing advancements in algorithmic jailbreaking of reasoning models. Our research underscores the urgent need for rigorous security evaluation in AI development to ensure that breakthroughs in efficiency and reasoning do not come at the cost of safety. It also reaffirms the importance of enterprises using third-party guardrails that provide consistent, reliable safety and security protections across AI applications.
Introduction
The headlines over the last week have been dominated largely by stories surrounding DeepSeek R1, a new reasoning model created by the Chinese AI startup DeepSeek. This model and its staggering performance on benchmark tests have captured the attention of not only the AI community, but the entire world.
We’ve already seen an abundance of media coverage dissecting DeepSeek R1 and speculating on its implications for global AI innovation. However, there hasn’t been much discussion about this model’s security. That’s why we decided to apply a methodology similar to our AI Defense algorithmic vulnerability testing on DeepSeek R1 to better understand its safety and security profile.
In this blog, we’ll answer three main questions: Why is DeepSeek R1 an important model? Why must we understand DeepSeek R1’s vulnerabilities? Finally, how safe is DeepSeek R1 compared to other frontier models?
What is DeepSeek R1, and why is it an important model?
Current state-of-the-art AI models require hundreds of millions of dollars and massive computational resources to build and train, despite advancements in cost effectiveness and computing made over past years. With their models, DeepSeek has shown comparable results to leading frontier models with an alleged fraction of the resources.
DeepSeek’s recent releases — particularly DeepSeek R1-Zero (reportedly trained purely with reinforcement learning) and DeepSeek R1 (refining R1-Zero using supervised learning) — demonstrate a strong emphasis on developing LLMs with advanced reasoning capabilities. Their research shows performance comparable to OpenAI o1 models while outperforming Claude 3.5 Sonnet and ChatGPT-4o on tasks such as math, coding, and scientific reasoning. Most notably, DeepSeek R1 was reportedly trained for approximately $6 million, a mere fraction of the billions spent by companies like OpenAI.
The stated difference in training DeepSeek models can be summarized by the following three principles:
- Chain-of-thought allows the model to self-evaluate its own performance
- Reinforcement learning helps the model guide itself
- Distillation enables the development of smaller models (1.5 billion to 70 billion parameters) from an original large model (671 billion parameters) for wider accessibility
Chain-of-thought prompting enables AI models to break down complex problems into smaller steps, similar to how humans show their work when solving math problems. This approach combines with “scratch-padding,” where models can work through intermediate calculations separately from their final answer. If the model makes a mistake during this process, it can backtrack to an earlier correct step and try a different approach.
Additionally, reinforcement learning techniques reward models for producing accurate intermediate steps, not just correct final answers. These methods have dramatically improved AI performance on complex problems that require detailed reasoning.
Distillation is a technique for creating smaller, efficient models that retain most capabilities of larger models. It works by using a large “teacher” model to train a smaller “student” model. Through this process, the student model learns to replicate the teacher’s problem-solving abilities for specific tasks, while requiring fewer computational resources.
DeepSeek has combined chain-of-thought prompting and reward modeling with distillation to create models that significantly outperform traditional large language models (LLMs) in reasoning tasks while maintaining high operational efficiency.
Why must we understand DeepSeek vulnerabilities?
The paradigm behind DeepSeek is new. Since the introduction of OpenAI’s o1 model, model providers have focused on building models with reasoning. Since o1, LLMs have been able to fulfill tasks in an adaptive manner through continuous interaction with the user. However, the team behind DeepSeek R1 has demonstrated high performance without relying on expensive, human-labeled datasets or massive computational resources.
There’s no question that DeepSeek’s model performance has made an outsized impact on the AI landscape. Rather than focusing solely on performance, we must understand if DeepSeek and its new paradigm of reasoning has any significant tradeoffs when it comes to safety and security.
How safe is DeepSeek compared to other frontier models?
Methodology
We performed safety and security testing against several popular frontier models as well as two reasoning models: DeepSeek R1 and OpenAI O1-preview.
To evaluate these models, we ran an automatic jailbreaking algorithm on 50 uniformly sampled prompts from the popular HarmBench benchmark. The HarmBench benchmark has a total of 400 behaviors across 7 harm categories including cybercrime, misinformation, illegal activities, and general harm.
Our key metric is Attack Success Rate (ASR), which measures the percentage of behaviors for which jailbreaks were found. This is a standard metric used in jailbreaking scenarios and one which we adopt for this evaluation.
We sampled the target models at temperature 0: the most conservative setting. This grants reproducibility and fidelity to our generated attacks.
We used automatic methods for refusal detection as well as human oversight to verify jailbreaks.
Results
DeepSeek R1 was purportedly trained with a fraction of the budgets that other frontier model providers spend on developing their models. However, it comes at a different cost: safety and security.
Our research team managed to jailbreak DeepSeek R1 with a 100% attack success rate. This means that there was not a single prompt from the HarmBench set that did not obtain an affirmative answer from DeepSeek R1. This is in contrast to other frontier models, such as o1, which blocks a majority of adversarial attacks with its model guardrails.
The chart below shows our overall results.

The table below gives better insight into how each model responded to prompts across various harm categories.
A note on algorithmic jailbreaking and reasoning: This analysis was performed by the advanced AI research team from Robust Intelligence, now part of Cisco, in collaboration with researchers from the University of Pennsylvania. The total cost of this assessment was less than $50 using an entirely algorithmic validation methodology similar to the one we utilize in our AI Defense product. Moreover, this algorithmic approach is applied on a reasoning model which exceeds the capabilities previously presented in our Tree of Attack with Pruning (TAP) research last year. In a follow-up post, we will discuss this novel capability of algorithmic jailbreaking reasoning models in greater detail.
We’d love to hear what you think. Ask a Question, Comment Below, and Stay Connected with Cisco Secure on social!
Cisco Security Social Handles








So crazy thinking about the number of people who immediately switched over to using it without thinking about it security strength and are now probably data-exploited by malicious hackers or even organisations. Thanks to you and your efforts in taking time to test out this new Ai model which seems to have attracted the whole world in a day but deep down has some security weaknesses. Hopefully developers, organisations and people in general refrain from using it for now until further notice .
Um, the graphic clearly shows that Llama and GPT 4o don’t fare much better…
Welp, things come out of China just have to be evil. None of the issues mentioned was new to any LLM. The only difference is the national original of the model in question this time.
Why do you have this stereotype? Science knows no borders
very true. ChatGpt being closd source has 86℅. Its just corporate agenda to demene deepkeek influence
ass war
Thanks for sharing in details to learn and real life demo on Cisco AI solution. Looking forward to followup report.
Thank you for a very informative post!
Could you please give a couple of examples of “there [were] no prompt[s] from the HarmBench set that did not obtain an affirmative answer from DeepSeek R1”. A few benign examples of this would greatly bring the point home of what these vulnerabilities look like and lead to – for the less experienced among us!
Thank you!
Wow such great information! You totally explained showed your findings and demonstrated how the AI responded! You also compared it with other AIs and showed how they responded different! Such wow!
“Our findings suggest that DeepSeek’s claimed cost-efficient training methods, including reinforcement learning, chain-of-thought self-evaluation, and distillation may have compromised its safety mechanisms.”
How confident in this are you?
Also, your wording “compromised” is a bit inflamatory as you are suggesting their methodology degraded safety. It may be more accurate to say they put little/no emphasis on building safety. I think it’s fairly straightforward to understand that the DeepSeek team focused on creating an open-source model would spend very little time on safety controls. Many application developers may even prefer less guardrails on the model they embed in their application.
Has OpenAI o1/o3 team ever implied the security is more difficult on chain of thought models? Any other researchers make this observation?
I wonder whether deepseek gives you correct answer for these illegal question? This is more of a legal/ethical question than AI question. It currently only follows the ethics and law from China, it won’t censor answers if violate ethics and laws only from western perspectives.
No, it answers any question. You’re confusing the model with the service. The model has no such censorship.
As a world leading organization, Cisco should refrain from making premature statements which sound like pandering to big players and undermining a disruptor. As others have noted, the new model is an open-source research model not intended for commercial deployment. Secondly, there is no evidence against CoT models either incapable of or having limitations to incorporate security guardrails in future variants.
Making the model open source is essential for effectively addressing and improving security issues.
So all I’m seeing is that R1 is a better model as it actually less censored than “open”AI? Calling this “security risk” sounds like a joke, its more secure than o1 if anything, as you can run it on own hardware.
I agree. This tool poses no risk to its users; it only threatens an authoritarian regime’s ability to control the flow of information.
Cost, business value and risks are always the Big 3. We need to get into the habit of understanding all 3 before we decide a winner.
This is a fantastic and timely article—thank you for publishing it! I believe the most significant challenges in utilizing large language models (LLMs) are their vulnerabilities and the issue of hallucinations, rather than the cost associated with their use.
Guys – Nvidia just packaged R1 on NIMs microservice and certified this for distribution in their preview build site build.nvidia.com. i have to assume they were satisfied on bad actor /threat sceanrios( leveraging Neo Guardrails and/or some addition Secure runtime. In addition AWS announced R1 on the Bedrock & Sagemaker So ia m quite intrigued by why they would broadcast this w/o stating the threat exposure at the levels you report. Am i missing something ?
*comment*
Sounds like the speed and performance may have cost this AI derivative ethics as well as security. AI is a two-sided coin: one side is cutting edge and attractive, the other mysterious and needing scrutiny. Great article. Thanks.
It would be nice to see how each attacked perform on these LLMs, at least the most common ones, thanks for the research and the post guys, great effort!
is there detail procedures of the test, so we can reproduce the results?
This valuable and timely article effectively raises awareness about the emerging security challenges presented by frontier reasoning models. The potential for more sophisticated social engineering and the circumvention of traditional defenses are particularly well-taken. Building on this, I’d like future articles to delve deeper into specific mitigation strategies. Exploring AI-driven security solutions or adversarial training approaches could be valuable next steps in this crucial conversation. Thank you for bringing this critical topic to the forefront.
Some more general questions. How many actual attacks have been reported over time on LLM’s as opposed to the analyzed ones above? Is there a report and a breakdown similar to the one’s presented here? Actual deployment results accompanying the analysis above could help put the risk into better perspective.
Thanks for testing the model and sharing findings. Security is not robust in any model and even weaker with R1
Fascinating. You’ve essentially running a self-censorship benchmark. And boasting about it.
Plus, bravo on the fear-mongering use of the term “jailbreak”; being open source, DeepSeek (like Llama) has no jail to break. Its guardrails are not opaque and buried inside the model but instead laid bare in the ToS license where it belongs. Security through obscurity has no place in software *or* LLMs.
Ben Franklin’s famous quote about liberty versus safety is quickly brought to mind.
Next time can you add Limitations and Key-takeaways to your publication, at least for the internal executive audience. Using guardrails in AI apps is a pretty simple method for reliable production-grade security in particular with agent implementations. Evaluations like yours can lead to wrong conclusions.
Not blocking prompts nor filtering the output seems like a feature to me.
Let’s highlight that users want to maximize polyvalence and potential, which obviously involves reducing restrictions. It’s only corporates that try to use AI for their own profit that want to increase those for public use. (let’s also note here that using an AI as intermediate to a web interface will never be any safer)
Don’t sacrifice that. The better solution is to let both coexist.
Thanks for council how I can thank you?
It agree, very useful phrase
How much parameters did the deepseek R1 model had that you used for your evaluation?
Your going to have to get your employees to strict privacy contracts. You must secure data and remember the gene pool in America is our winning factor. God speed.
I’ve found the insights on evaluating security risks in DeepSeek quite enlightening. The use of algorithmic AI vulnerability testing is a crucial step for ensuring the safety of these models. It’s great to see Cisco taking such a proactive approach to security in technology!
I’ve been really impressed by the performance of DeepSeek models, but I have concerns about their security implications. It’s crucial to ensure that AI systems are tested for vulnerabilities before deployment. Can you provide insights on the specific tests conducted for these models?
java as
ass