
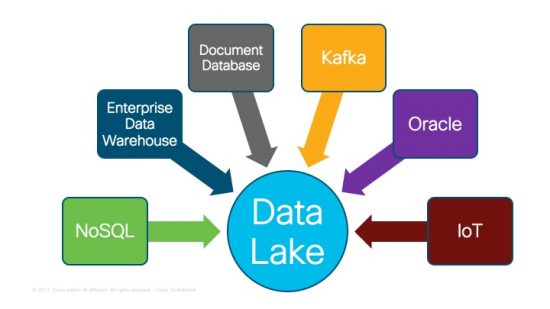
If data is the new oil, there is one major difference. Unlike oil, which over the years have suffered from unpredictable supply, for much of the customers, there is only abundance of data. Despite the glut of data, the same customers profess there is often a shortage of actionable information. In other words, customers are needing more ways to analyze the data into something more useful and valuable. In fact, the Cisco Big Data and Analytic customers are constantly looking for ways to refine that data into actionable information. These customers already have a data lake of some kind gathering information from a variety of sources such as
- Traditional databases such as Oracle or SQLServer
- Document stores, such as MongoDB
- Kafka or other message middleware
- Enterprise data warehouse
- NoSQL Database
- Internet of Things
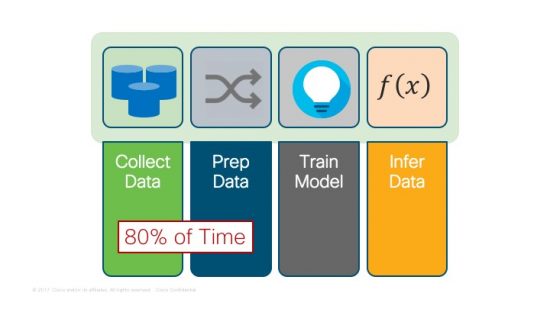
Once the data has been gathered, the real data refining begins. For many data scientists, gathering and cleaning the data takes up to 80% of the time. Preparing the data from so many different sources is both the value and the challenge for the data scientists. Once the data is prepared, advanced analytic techniques such as machine learning and deep learning begin. Finally, once a viable machine learning model has been created, it is used with new data in the inferencing stage.
Because machine learning / deep learning is often at the end of the broader big data pipeline, at the GPU Technology Conference (GTC) in San Jose next week, we are planning to demonstrate Hadoop cluster, where many of our customers have data lakes, integrated with deep learning framework.
Because the deep learning techniques can absorb almost an insatiable amount of data, having a robust HDFS cluster is good way to have a scale out storage enabling collection and preparation of the data. While all of these machine learning algorithms can run on traditional x86 CPUs, GPUs have shown to be able to accelerate deep learning algorithms by 10x to 100x. As a result, the demo highlights Cisco UCS C240 and C480 with up to 2 and 6 GPUs, respectively, accelerating the training of the deep learning modules. Of course, with the ever increasing cluster size supporting the continuous ingestion of data, UCS Manager and Cisco Intersight provides the service profiles enabling the cluster to scale without the equal scaling of additional IT human resources. While we are only demonstrating one of the deep learning frameworks at GTC in San Jose, the hardware can clearly support other machine learning frameworks, such as Caffe, Torch, and others.
Looking forward to see you at GTC in the San Jose Convention Center next week. Cisco booth is #415. Visit Cisco site with more details about all the other demos being show at GTC San Jose.






Great information, Han. You've got an amazing end to end portfolio of solutions for big data and analytics – from collecting information at the edge to absorbing and processing it in real time, to leveraging the best new storage options, including flash and object, from all the leading vendors. I'm really looking forward seeing it all at GTC!