
The world is being transformed by the recent and rapid proliferation in Artificial Intelligence (AI) and Machine Learning (ML) from directly improving our personal lives to enterprise applications around security, business intelligence, automation, analytics, spam filtering, conversational interfaces etc.
AI, and ML in particular, is an iterative engineering process wherein observed data (from a system) is used to “train” a mathematical model that learns a rich representation of real-world entities (e.g. malware images) based on prior observations (e.g. a set of malware and benign images). This trained model can now be used for “inference” on future data i.e. given a new observation or an input datum, the model can predict an outcome (e.g. is this image a malware image?). This is different from traditional computing paradigms where one encodes a set of deterministic/procedural steps to directly process the data without the insight from prior data. The above workloads are often both very compute intensive (e.g. millions of matrix and tensor operations) especially during the training process, and it could be I/O intensive during the inference process. Some examples are malware or threat detection and real-time media processing.
A line-of-business will often have several AI/ML engineers working on a suite of models that are trained on a variety of business data. These models are derived assets that need to be managed and the entire training lifecycle needs to be supported by the entity’s infrastructure teams. These teams have several choices when they design their infrastructure, ranging from leveraging public clouds to investing in private datacenter in order to support their AI lifecycle needs.
Within our AI team, our focus is to devise new methods for moving the needle in areas ranging from core technology to applications of AI in security, collaboration and IoT. When we bootstrapped, our natural choice was to leverage public clouds. Our natural choice was Google’s TensorFlow for our learning tasks, due to the maturity of the toolchains, its production battle hardiness, and the fact that we can run this seamlessly, either on bare metal or on virtualized infrastructure. While initial ramp up in the public cloud was very smooth, we soon realized that a public-cloud-only strategy would be expensive for our predictable and long-term AI/ML workloads. We started to investigate other options, and this lead to some new offerings from our own server business that delivers the Cisco HyperFlex– a hyperconverged multicloud platform infrastructure, based on the Cisco Unified Computing System (UCS).
The UCS product owners for AI/ML and our team had a few very short and crisp meetings to articulate our needs. The product team got back to us with a few interesting solutions – not only would we get low-touch, managed, state-of-the-art, bare metal hardware infrastructure, we could also leverage Cisco’s HyperFlex, Cisco’s hyperconverged infrastructure. Naturally, our engineering team wanted to evaluate the different combinations. Since we have been moving our engineering infrastructure towards containers, our natural choice was to ensure we were at par with the performance we got on public clouds. Thus, we had several infrastructure combinations to think through, with the layers being: bare metal, bare metal and Kubernetes (or K8s), HyperFlex, HyperFlex and K8s and a public cloud.
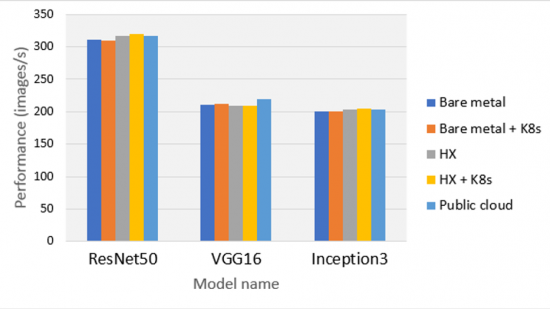
We decided to answer the above via a data driven approach, a.k.a., benchmarking. We first decided to do a barebones set of synthetic benchmarks around TensorFlow followed by running our own in-house benchmarks based on our own workloads. We picked the CNN models: resnet50, inception3 and vgg16 as a reference. We ran the benchmarks on systems with the latest NVIDIA GPUs (e.g. V100) vs. their previous generation (e.g. P100) and we validated our simple hypothesis – virtualization layers when “set up correctly” lead to high, almost bare metal performance for our compute intensive ML workloads. We also compared by running the exact same workload on a public-cloud based GPU optimized node and the performance of the UCS systems (bare metal and hyperconverged) were equivalent. We have also run our internal training workloads on the same setup on a wide variety of workloads, and we have been very satisfied by the performance. This gave us the confidence to consider UCS as a viable long-term investment for our own long-term AI/ML training workloads, in addition to our public cloud spend (for our elastic needs). We will be validating the above choices very rigorously, as we transition to a hybrid infrastructure setup.
Another factor important to us was the ease of use. The UCS management stack takes the pain out of bare metal management and is as easy to use as our public cloud assets. This mitigates one of our key concerns (to consider private infrastructure for AI/ML). The NVIDIA and TensorFlow toolchains install the same way as they would on any other hardware platform. Also, Cisco UCS fulfills the need for a compelling on-premise solution to build models on data that cannot leave our premises.
For now, our infrastructure choices are clear – in the multicloud world we live in, leveraging a combination of public clouds and managed hyperconverged infrastructure (HyperFlex) is a very balanced option. For software, we continue to use TensorFlow and we feel confident transitioning to Kubernetes will not disrupt our application workflows.






interesting Article
Great article. It would be interesting to know how the infrastructure is managed, and perhaps more importantly what you will use to determine when to run on metal vs. when to use public resources.
Thx Robert, this is also related to Stephans' question: a simple way would be to use Cisco CloudCenter to manage the software infra and Cisco Intersight to manage bare metal.
Debo, did you think about using Cisco CloudCenter as management platform for your multicloud environment?
Thx, very good point! We are working on that for our internal use. Happy to share details here at some point. CloudCenter is an easy way to deploy workloads and manage costs across the Multicloud.
Thanks for the great article. I think we should have a Cisco internal benchmark suite (that is extensible) so that this thing can be democratized.
Awesome article! Cisco and Google , two powerhouses joining up to take AI to the next level. TensorFlow indeed is now a natural choice, more so for spme people like myself with a Physics background finds it intuitively easier to visualize the Sessions; and TF's GPU based computing offering makes it absolutely the best choice with NVIDIA cards supporting the process. Exciting future to look forward to!