
AI agents are moving from demos into production fast — and every LLM call and external tool they invoke is a new attack surface. This post introduces Agent Runtime Protection in the Cisco AI Defense Python SDK: a one-line integration that brings Cisco AI Defense inspection to every LLM and MCP interaction across chat apps, agent frameworks, and managed agent runtimes.
Security researchers have demonstrated how a simple instruction hidden in a Google Doc can hijack an AI agent, causing it to exfiltrate sensitive data to an external server. The attack required no special access—just a line of text the agent would read during normal operation. AI agents now execute code, send emails, query databases, and browse the web autonomously. When an agent processes a malicious prompt embedded in external content, the agent doesn’t just say something harmful; it does something harmful.
Enterprises are deploying these systems at scale. According to Cisco’s AI Readiness Index 2025, 83% of companies plan to develop or deploy AI agents. Yet most enterprise security stacks weren’t built for this kind of traffic — and that gap is widening as agents pull in untrusted content and call out external tools. We built Agent Runtime Protection in the Cisco AI Defense Python SDK so adding this protection is a one-liner: agentsec.protect() uses dynamic code rewrites to wrap every LLM call and MCP tool invocation in AI Defense inspection — no other changes to your application code.
The Agentic Stack: Three Levels of Complexity
Where you need protection depends on where your code lives in the stack. Three layers, each with its own integration story, and all three need the same guardrails wrapped around every LLM call and MCP tool invocation.
Level 1: Chat Applications
At the simplest level, applications call models directly — OpenAI, AWS Bedrock, Google Vertex AI, Azure OpenAI. The classic chatbot pattern: send a prompt, get a response, render it. Security here lives at the prompt/response boundary: catch injection on the way in, catch leakage on the way out.
Level 2: Agentic Frameworks
Things get harder with frameworks like LangChain, LangGraph, CrewAI, AutoGen, Strands, Google ADK, and the OpenAI Agents SDK. These frameworks handle orchestration, managing state, coordinating multi-step reasoning, and enabling tool use. The catch is that LLM and tool calls happen inside the framework. You aren’t writing client.chat.completions.create() yourself; the framework is doing it for you, often in a loop or across multiple threads. Securing those calls without forking framework code is hard — and it matters, because the agent is making real decisions and calling real tools on your behalf.
Level 3: PaaS Agent Runtimes
Cloud providers now ship managed runtimes purpose-built for agents — AWS Bedrock AgentCore, Google Vertex AI Agent Engine, Microsoft Azure AI Foundry. You’re no longer just running code; you’re deploying an agent into a managed container or serverless function someone else controls. Protection has to ship with the agent into that environment and cover every LLM call and MCP tool invocation it makes there.
Why Traditional Security Falls Short
Agents interact with external systems through the Model Context Protocol (MCP)—an open standard that enables LLMs to call tools, access resources, and retrieve prompts from external servers. MCP adoption has exploded, with thousands of servers now available in public registries. Each MCP interaction opens a new attack vector:
- Tool poisoning — Malicious instructions hidden in tool descriptions or metadata
- Indirect prompt injection — Harmful commands embedded in content the agent reads
- Data exfiltration — Sensitive information leaked through tool responses
- Rug pull attacks — Initially legitimate tools updated with malicious code
Traditional API security wasn’t built for any of these. WAFs and API gateways don’t understand LLM context, can’t parse a reasoning trace, and miss the threats that only show up once prompts, tools, and responses start feeding back into each other.
Cisco AI Defense: Protection Across the AI Lifecycle
Cisco AI Defense covers the full lifecycle:
- Discovery — Inventory AI assets across distributed cloud environments
- Detection — Identify vulnerabilities including supply chain risks and jailbreak susceptibility
- Protection — Enforce runtime guardrails updated with current threat intelligence
The Cisco AI Defense Inspection API analyzes prompts and responses for prompt injection, sensitive data exposure, toxic content, and policy violations. That works well — but instrumenting every LLM call and MCP interaction across a real agentic stack means touching a lot of code. The new Agent Runtime Protection in the Cisco AI Defense Python SDK closes that gap.
Cisco AI Defense SDK: Automatic Protection Through Dynamic Code Rewrites
Agent Runtime Protection ships inside the Cisco AI Defense Python SDK. A single agentsec.protect() call rewrites the LLM and MCP client libraries at runtime so every call routes through inspection — without you changing a line of your own code.
How It Works
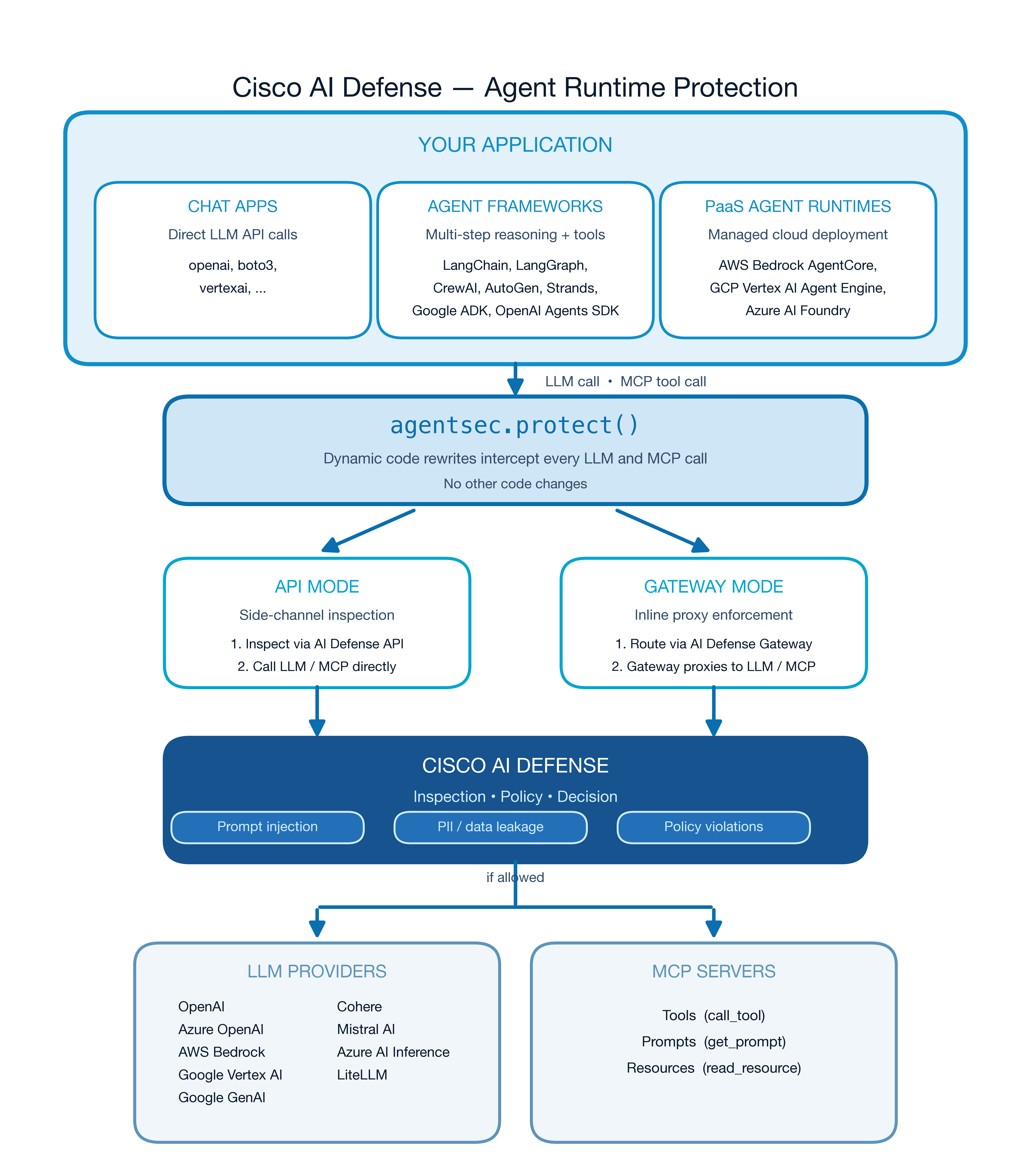
Request Inspection — Before any LLM or MCP call, Agentsec sends the content to AI Defense for analysis. Prompt injection, sensitive data exposure, and policy violations can be detected before the call proceeds.
Response Inspection — After the provider returns, Agentsec routes the response through AI Defense. Data leakage, harmful content, and compliance violations can be caught before reaching your application.
MCP Protection — All three MCP interaction types are covered:
- Tools (call_tool) — Inspect arguments and results
- Prompts (get_prompt) — Inspect templates from external servers
- Resources (read_resource) — Inspect data from external sources
Code Examples
Simple Chat Completion (OpenAI)
from aidefense.runtime import agentsec agentsec.protect(config="agentsec.yaml") from openai import OpenAI client = OpenAI() # Automatically inspected by Cisco AI Defense response = client.chat.completions.create( model="gpt-5.5", messages=[{"role": "user", "content": "Hello!"}] )
Agentic Framework (LangChain)
from aidefense.runtime import agentsec agentsec.protect(config="agentsec.yaml") from langchain_openai import ChatOpenAI from langchain_core.tools import tool from langchain_core.messages import HumanMessage, ToolMessage @tool def fetch_url(url: str) -> str: """Fetch a URL via an MCP server (inspected by agentsec).""" ... # calls mcp.ClientSession.call_tool(), which agentsec patches llm = ChatOpenAI(model="gpt-5.5") llm_with_tools = llm.bind_tools([fetch_url]) tools_dict = {"fetch_url": fetch_url} # All LLM calls and MCP tool invocations are inspected messages = [HumanMessage(content="Fetch example.com and summarize it")] response = llm_with_tools.invoke(messages) messages.append(response) while response.tool_calls: for tc in response.tool_calls: result = tools_dict[tc["name"]].invoke(tc["args"]) messages.append(ToolMessage(content=str(result), tool_call_id=tc["id"])) response = llm_with_tools.invoke(messages) messages.append(response)
PaaS Runtime (AWS Bedrock AgentCore)
from aidefense.runtime import agentsec agentsec.protect(config="agentsec.yaml") from bedrock_agentcore import BedrockAgentCoreApp from _shared import get_agent # Strands agent with agentsec protection app = BedrockAgentCoreApp() @app.entrypoint def invoke(payload: dict): user_message = payload.get("prompt", "Hello!") # Both request AND response are inspected result = get_agent(user_message) return {"result": str(result)}
Key Capabilities
Multi-Provider Support: Agentsec rewrites calls for OpenAI, Azure OpenAI, AWS Bedrock, Google Vertex AI, Google GenAI, Cohere, Mistral AI, Azure AI Inference, and LiteLLM. Switch providers without changing your security integration.
Two Integration Modes:
- API Mode — Inspects via AI Defense API, then calls the provider directly
- Gateway Mode — Routes all traffic through Cisco AI Defense Gateway for centralized enforcement
MCP Protection: All MCP interaction types—tools, prompts, and resources—pass through AI Defense inspection on both request and response. Indirect prompt injection and data exfiltration are caught at the tool boundary.
Inspection Modes: In API mode, the SDK exposes three settings — monitor (log only), enforce (block), and off (disable). In Gateway mode the gateway itself does the enforcing, so the SDK setting is simply on or off.
Handle Blocked Requests
When Agentsec blocks a request in enforce mode, it raises a SecurityPolicyError:
from aidefense.runtime.agentsec import SecurityPolicyError try: response = client.chat.completions.create(...) except SecurityPolicyError as e: print(f"Blocked: {e.decision.action}") print(f"Reasons: {e.decision.reasons}")
Get Started
Agentsec is available now in the Cisco AI Defense Python SDK.
pip install cisco-aidefense-sdk
Or with Poetry:
poetry add cisco-aidefense-sdk
The SDK is open source. Explore the code, examples for seven agent frameworks, and deployment guides for AWS Bedrock AgentCore, GCP Vertex AI Agent Engine, and Azure AI Foundry: github.com/cisco-ai-defense/ai-defense-python-sdk
If you’re securing AI applications at scale, reach out to the Cisco AI Defense team for a walkthrough.




