
The importance of understanding a model’s origins has been a frequent topic of discussion among researchers and industry experts, and our own AI research confirms that AI supply chain security remains a weak link. Tracking where models come from, known as “model provenance,” will be essential for the future of AI model and supply chain security. To help with this, we are releasing our new Model Provenance Kit as an open source tool.
Think of the Model Provenance Kit as a DNA test for AI models. The current AI supply chain, from datasets used for training to the deployment of a finished model, is opaque. Documentation on open model repositories can be faked, and important details in the metadata can be removed or changed. Much like a DNA test reveals biological origins, the Model Provenance Kit examines both metadata and the actual learned parameters of a model (like a unique genome that comprises a model), to assess whether models share a common origin and identify signs of modification. This, combined with a constitution that defines provenance linkages, are important steps toward providing evidence-based assurance that the AI you deploy is what it says it is.
Recent developments show just how complex and interconnected AI supply chains have become, with teams drawing on a mix of proprietary systems, open models, and third-party components. Cases like Cursor’s Composer 2 that were partly built on Kimi 2.5, along with broader industry adoption of globally developed models, highlight the need for clear provenance so organizations can make fully informed decisions about how to manage any risks with AI they develop and deploy.
Why this Matters
Many organizations use AI models downloaded from open source model repositories like HuggingFace, which currently hosts over 2 million models. After downloading and fine-tuning these models, organizations often fail to keep a clear record of the changes made. As a result, there is usually no way to track how the model was modified during its development. While model repositories have hosted guidance on the importance of model cards and metadata, earlier research about model maintenance and revisions indicate that model maintenance varies significantly, which may impact downstream users of those models.
Beyond shortcomings in documentation, there is also often no verification of claims for models hosted on these repositories; developers can claim a model is trained from scratch, but it could be a modified copy of another model. Complicating the issue further: models may also include biases in training data, vulnerabilities in the model’s architecture, or licensing caveats from their creators.
When organizations don’t know where their AI models actually come from, they’re flying blind on security, compliance, and liability. Without insight into model provenance, there are implications on numerous factors:
- Poisoned or vulnerable models: An enterprise could deploy a model that has been poisoned or is vulnerable to manipulation. If unaccounted for, those vulnerabilities can continue to propagate, whether they affect an internal chatbot, an agent application, or a customer-facing tool. Similarly, an enterprise could deploy a model that has biases in its training data that make it a poor choice for its use case or make it susceptible to manipulation. The vulnerabilities are inherited and would persist in generative and agentic applications. Without provenance, organizations have no easy way to trace an incident back to its root cause, and no way to determine which other models in their stack are also affected.
- Licensing and regulatory risk: Regulatory frameworks are increasingly requiring organizations to document how AI systems are built and where their components originate. The European Union (EU) AI Act, for example, mandates documentation of training data, characteristics of training methodology, and risk assessments for “high-risk systems.” Meanwhile, the National Institute for Standards and Technology (NIST)’s AI Risk Management Framework identifies third-party AI component risks as a key area for organizational governance. As these requirements evolve, organizations may face downstream compliance gaps. Moreover, some open weight models also have restrictive licensing, so if a model turns out to be a derivative of one with restrictive licensing (e.g., one trained in a jurisdiction subject to export controls; others may impose restrictions based on company size), there may be other legal or compliance considerations.
- Supply chain integrity risk: Models can be mislabeled, repackaged, or uploaded without attribution, and a model card can claim to be “trained from scratch,” but it may actually be a modified copy of another model. Without technical verification of provenance, organizations are trusting claims that no one has validated.
- Incident response risk: If a model experiences a security issue or shows evidence of manipulation, it will make it harder to remediate and resolve issues if you don’t have insight into the model’s lineage. Organizations wouldn’t be able to determine whether the problem is the model itself, a related model, its parent, or something else that’s introduced during fine-tuning. Today, this is a manual and tedious investigatory process.
When considering how to approach model provenance, the challenge for many organizations is that modern model families share identical architectures. Models from Meta, Alibaba, DeepSeek, and Mistral use the same building blocks such as grouped-query attention, rotary positional embeddings, and Root Mean Square Normalization (RMSNorm). A config file can describe the architecture but it cannot tell whether the weights were copied from another model or trained independently.
How Model Provenance Kit works
Model Provenance Kit is a Python toolkit and command-line interface (CLI) that that can determine whether two AI models share a common origin by analyzing architecture metadata, tokenizer structure, and the learned weights themselves, using a tiered strategy that starts with fast structural checks and progresses to deeper weight-level analysis when metadata alone is inconclusive.
Model Provenance Kit generates a rich “fingerprint” for each model using metadata signals, tokenizer similarity, and weight-level identity signals such as embedding geometry, normalization layers, energy profiles, and direct weight comparisons. These signals are then compared to produce a single provenance score that reflects whether two models share a common origin or training lineage. The system works on any transformer model with downloadable weights and progresses in two stages:
Stage 1 is a fast architectural screening, where Model Provenance Kit compares model configurations and structural metadata before loading any weights. If two models share identical architecture specifications, they can be confidently classified as related, enabling rapid resolution for a large portion of cases with high precision.
When metadata is ambiguous, such as when two models use the same architectural template but may have been trained independently, the pipeline progresses to Stage 2: weight-level analysis. Provenance Kit extracts five complementary signals from the actual model weights:
- Embedding Anchor Similarity (EAS): Compares the geometric relationships between token embeddings. This structure is unique to a training run and survives fine-tuning.
- Embedding Norm Distribution (END): Analyzes the distribution of embedding magnitudes, which encode word frequency patterns learned during training.
- Norm Layer Fingerprint (NLF): Reads the tiny normalization layers that act as a stable fingerprint because they remain stable across fine-tuning.
- Layer Energy Profile (LEP): Compares normalized energy curve distributions across the depth of the network. Different training runs produce different energy distributions even when the architecture is identical.
- Weight-Value Cosine (WVC): Directly compares weight values between a subsample of corresponding layers. Independently trained models would likely demonstrate essentially zero correlation here.
These signals are combined into a single identity score using empirically calibrated weights. When any signal can’t be computed (e.g., when models have different layer counts), it is excluded and the remaining signals compensate automatically.
While we compute and assess tokenizer signals—vocabulary overlap analysis (VOA) and tokenizer feature vector (TFV)—for diagnostics, they do not influence provenance assessments. Many independently trained models share tokenizers (e.g., StableLM and Pythia both use the GPT-NeoX tokenizer and can score as “similar” despite having no weight lineage) and including them would create false positives.
Model Provenance Kit also features two modes
In compare mode, take any two models (from Hugging Face or local checkpoints) and get a detailed breakdown of their similarity across metadata, tokenizer structure, and most importantly, weight-level signals along with a final composite score that reflects shared lineage.
In scan mode, start with a single model and match it against a database of known fingerprints to surface the closest lineage candidates, turning provenance into a search problem.
Alongside this release, we’re also shipping an initial fingerprint database covering ~150 base models across 45+ families and 20+ publishers, ranging from 135M to 70B+ parameters—giving scan mode a strong foundation to identify real-world lineage relationships.
Results
We evaluated Model Provenance Kit against a 111-pair benchmark (55 similar, 56 dissimilar models) designed to include difficult real-world cases: aggressive distillation, quantization across formats, cross-organization fine-tuning, LoRA merging, continued pretraining with vocabulary extension, same-tokenizer traps, and independent reproductions of popular architectures. Results are shown in Table 1 below:
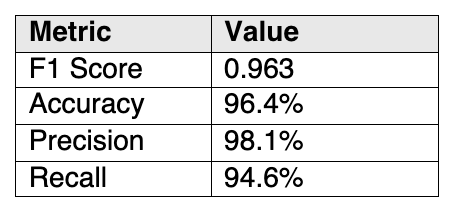 Table 1. Results of running Model Provenance Kit against a 111-pair benchmark at a similarity-dissimilarity threshold of 0.70 (on 0-1 scale)
Table 1. Results of running Model Provenance Kit against a 111-pair benchmark at a similarity-dissimilarity threshold of 0.70 (on 0-1 scale)
In evaluation, Model Provenance Kit accurately identified:
- Standard derivatives (fine-tuning, quantization, alignment) — 100% recall
- Cross-organization derivatives (models fine-tuned and released under a different name by a different organization) — 100% recall
- Same-tokenizer traps (independently trained models that happen to share a tokenizer)— 100% specificity
- Independent reproductions (same architecture, different training such as open_llama vs. Llama-2) — correctly identified as unrelated
Only 4 out of 111 pairs were misclassified, all involving extreme architectural transformations: distilling a 12-layer model with 768 hidden dimensions down to 4 layers while halving the hidden dimensions, or completely rebuilding a vocabulary for domain-specific continued pre-training. These represent fundamental limits of pairwise weight comparison and are not considered pipeline bugs.
The chart below (Figure 1) shows the distribution of Model Provenance Kit scores across all 111 benchmark pairs. Related model pairs (green) cluster near 1.0, while unrelated pairs (red) cluster well below the 0.70 threshold. The gap between the two distributions is what makes the system reliable, as there is very little overlap in the decision region.
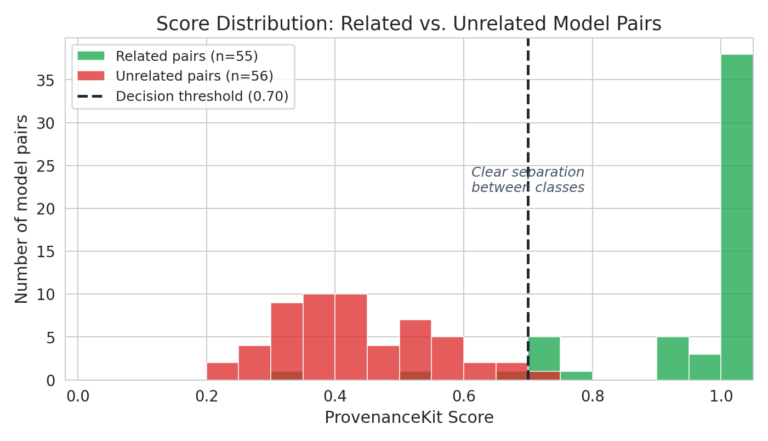 Figure 1. Model Provenance Kit performance against benchmarked sets
Figure 1. Model Provenance Kit performance against benchmarked sets
Below, see an example (Figure 2) that compares two DeepSeek family fine-tuned models using Model Provenance Kit, which demonstrates similar lineage across all metadata- and weight-based features:
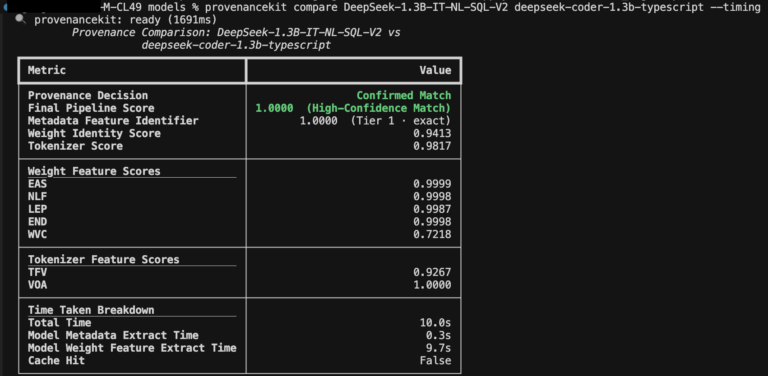 Figure 2. Comparing two DeepSeek fine-tuned models having shared lineage
Figure 2. Comparing two DeepSeek fine-tuned models having shared lineage
Conclusion
As models are continuously fine-tuned, distilled, merged, and repackaged, model files have evolved past static assets. Lineage becomes harder to track and easier to obscure, and answering the question of “what are the origins of this model?” requires more nuanced approaches. Our release of Model Provenance Kit is a step towards providing an evidence-based approach to model provenance.
Getting Started
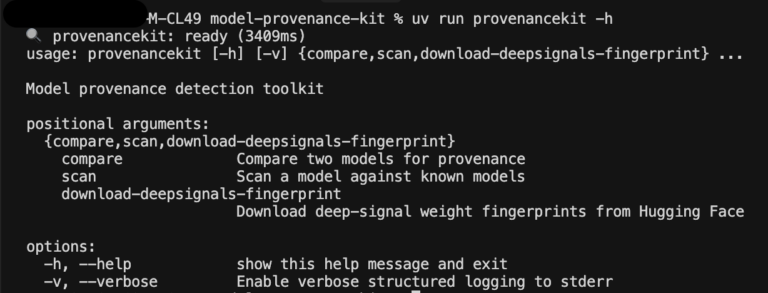 Figure 3. Screenshot of Model Provenance Kit’s command line interface
Figure 3. Screenshot of Model Provenance Kit’s command line interface
Getting started with Model Provenance Kit is easy: the entire pipeline runs on CPU and can scale to model size. Architectural matches resolve in milliseconds and extracted features are cached for reuse.
Model Provenance Kit is available today.
Check out the repository on Github here: https://github.com/cisco-ai-defense/model-provenance-kit
Our dataset of base model fingerprints is available on Hugging Face here: https://huggingface.co/datasets/cisco-ai/model-provenance-kit




