
Fine-tuning is a process that lets us steer a general-purpose large language model toward a specific task by training it on targeted examples. In cybersecurity, this is often useful for problems like classifying phishing emails, suspicious URLs, or PowerShell scripts. A fine-tuned model can become much more useful in a security workflow because it learns the language, structure, and labels that matter for that domain.
In our latest research, we found that fine-tuning can improve baseline classification behavior while also introducing a new kind of brittleness. The fine-tuned model performs better on standard held-out examples but becomes more vulnerable to behavior-preserving variants of the same underlying script. In other words, the model looks stronger under standard evaluation yet becomes easier to fool under realistic transformations that preserve what the code does.
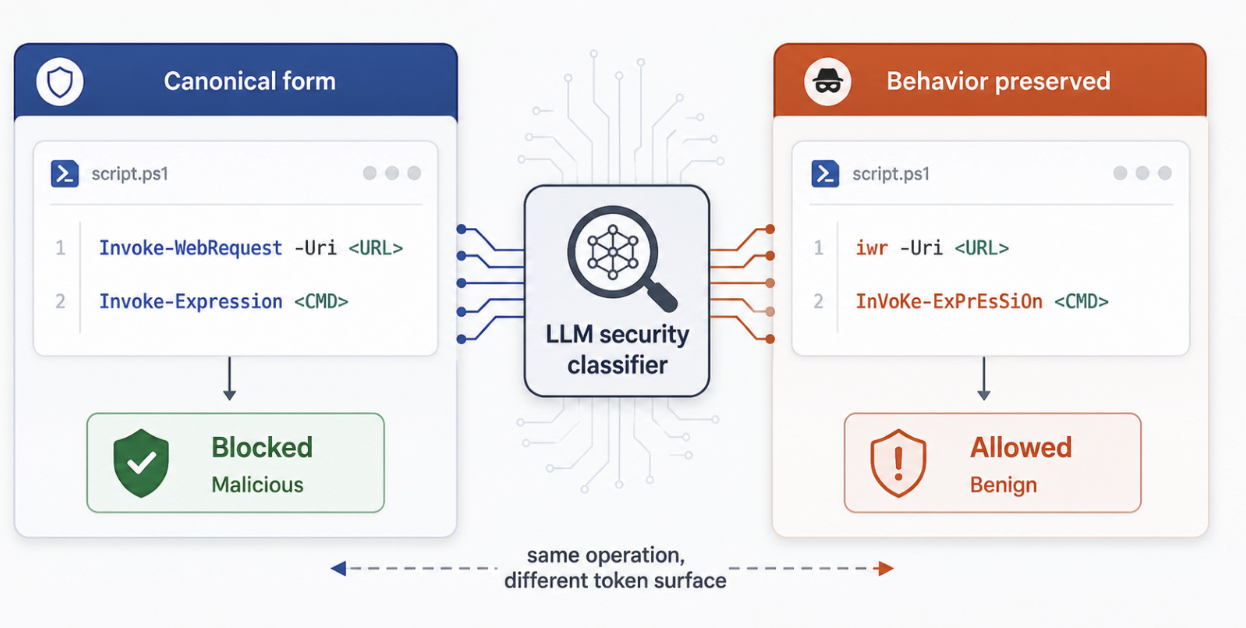
Our work traces the behavior to its mechanistic source, providing insights and concrete recommendations for security teams on how to manage and monitor changes introduced via fine-tuning.
Overview
We studied malicious/benign PowerShell script classification using a natural base + fine-tuned model pair: Llama-3.1-8B-Instruct and Foundation-Sec-8B-Instruct. Foundation-Sec performs better on the baseline classification task (+4.7% accuracy), but it also develops transformation-sensitive misses that the base Llama model does not share. Foundation-Sec was not explicitly fine-tuned for PowerShell classification, but for knowledge of the cybersecurity domain overall.
The key result is not just that some obfuscation works. The interesting finding is mechanistic: the fine-tuned model inherits the same underlying classification circuit from the base model, but fine-tuning changes how later parts of the network interpret that circuit’s signal. In successful evasion cases, the malicious evidence is often still present internally. The failure happens because fine-tuned feed-forward components can suppress, redirect, or invert that evidence before the final decision.
That gives us a practical lesson: post-fine-tuning robustness is not just a matter of test accuracy. A model can become more accurate on canonical examples while becoming more brittle to transformations that security teams should expect attackers to use.
Inherited Circuit, Specialized Semantics
Mechanistic interpretability is a set of tools for asking how a model computes a behavior internally. Instead of treating the model as a black box, we look for the specific components that causally drive the output. In transformer models, those components are often attention heads, MLP layers, and the residual stream, which is the running representation passed from layer to layer.
For this project, we used PowerShell classification as a concrete security setting. PowerShell is a useful case study because many suspicious indicators are not malicious by themselves. Tokens like IEX, DownloadString, Invoke-WebRequest, and -EncodedCommand can appear in malicious scripts, but they can also appear in benign administrative code. A good classifier cannot simply memorize that a token is suspicious. It needs to use surrounding context.
We compared Foundation-Sec against its Llama base model with the question: Did security fine-tuning create a new classification circuit, or did it reshape a circuit that was already present in the base model?
Our causal interventions support the second answer. Foundation-Sec’s classification route is inherited from Llama. The same broad circuit skeleton is already present in the base model (annotated as Layers [L] and attention heads [H] in the following figure):
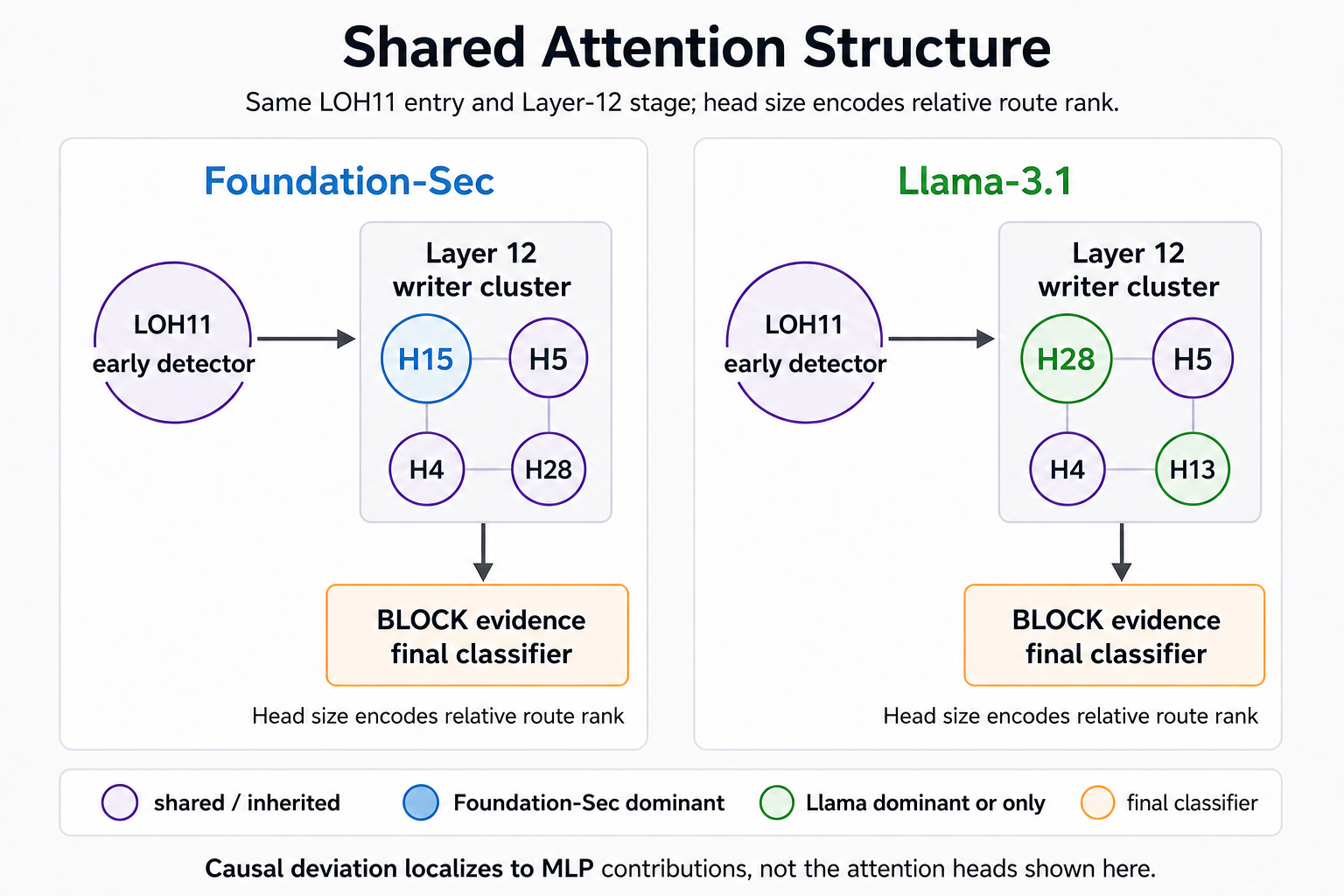
Fine-tuning does not appear to create a new PowerShell detector from scratch. Instead, it concentrates and specializes an inherited route. That specialization is useful. It helps the model classify canonical security examples. But it also creates a sharper dependence on indicator-token semantics. The fine-tuned model becomes more sensitive to the exact surface form of certain commands and indicators.
Stress-Testing the Circuit
Standard evaluation usually asks whether the model classifies held-out examples correctly. That is necessary, but it is not enough for security. Attackers do not need to preserve the exact surface form of a script. They only need to preserve the behavior.
To test this gap, we built a three-tier evasion benchmark. Each benchmark row starts with a malicious seed script that the model classifies correctly. We then apply a behavior-preserving rewrite and ask whether the model still classifies the variant as malicious. This keeps the attribution clean: the model properly handles the original script, so a miss on the transformed script can be tied to the transformation.
Each accepted variant must preserve important attributes such as URLs, command targets, arguments, encoded-command equivalence where relevant, and process-launch behavior.
The three tiers are:
- direct_v1: direct syntax-preserving rewrites
- reconstructive_v2: runtime command or string reconstruction
- case_mutation_v3: casing changes that preserve PowerShell semantics
Tier 1: Direct Rewrites
Direct rewrites change a visible command form without changing behavior. The simplest example is alias substitution. In PowerShell, common commands often have shorter aliases. An attacker does not need to change the payload. They can change the command surface, e.g.:
# seed pattern
Invoke-WebRequest -Uri <URL> -OutFile <PATH>
# behavior-preserving variant
iwr -Uri <URL> -OutFile <PATH>
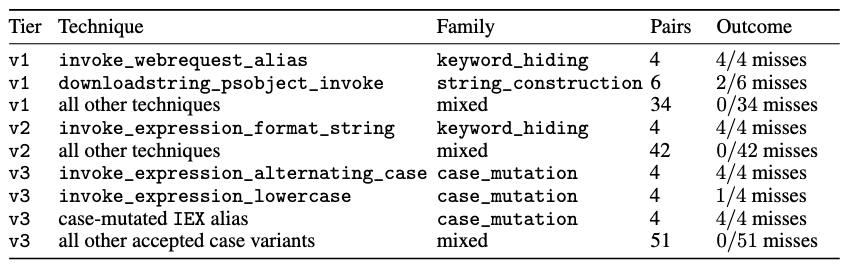
The theory for this category is that a model trained heavily on canonical command forms may treat the full command token differently from the alias, even when PowerShell treats them as equivalent. In our benchmark, this category produced consistent Foundation-Sec misses in the Invoke-WebRequest alias family. Llama did not share those misses on the same evaluated variants.
Tier 2: Command and String Reconstruction
The second-tier tests whether the model depends on a command or method appearing literally in the text. Many scripts reconstruct strings or command names at runtime. A classifier that overweight’s literal indicators can miss the behavior when the same command is assembled indirectly, e.g.:
# seed pattern
Invoke-Expression <COMMAND_STRING>
# behavior-preserving variant
& ((‘{0}{1}’ -f ‘Invoke-‘,‘Expression’)) <COMMAND_STRING>
This kind of rewrite preserves the command’s role while changing the textual evidence available to the model. It tests whether the classifier understands the operation or merely recognizes the literal command string. In our results, Foundation-Sec produced misses on a focused Invoke-Expression reconstruction pattern, while the base Llama model did not share the same misses.
Tier 3: Case Mutation
PowerShell command names are case-insensitive. That makes case mutation a particularly sharp test. Unlike reconstruction, it does not hide the command from a human reader. Unlike alias substitution, it does not replace the command with a different word. It preserves the same command identity and argument structure while changing the token surface that the model sees, e.g.:
# seed pattern
Invoke-Expression <COMMAND_STRING>
# behavior-preserving variant
InVoKe-ExPrEsSiOn <COMMAND_STRING>
We also tested alias-form case mutation:
# canonical alias form
IEX <COMMAND_STRING>
# behavior-preserving variant
iEx <COMMAND_STRING>
This tier is important because it points to token-surface sensitivity. If the model misses a script after a case-only change, the issue is unlikely to be semantic ambiguity in PowerShell. The behavior, command identity, and argument structure are preserved. What changed is the representation the model builds from the text.
Foundation-Sec produced misses while Llama produced none on the same evaluated set. The strongest misses concentrated around full-command Invoke-Expression case mutation (4/4 missed) and case-mutated IEX alias variants (4/4 missed):
Prompt Fixes Can Be Uneven
One tempting response is to fix the issue with a better prompt. For example, we can tell the model to classify based on overall purpose rather than individual constructs.
That helps in some places. In our tests, a prompt-level change fixed the Invoke-WebRequest alias misses. But it also opened or amplified misses in other families, including Invoke-Expression, IEX, and DownloadString transformations.
This reveals that prompt remediation can redistribute the failure surface, rather than eliminate it. Security teams should not assume that a prompt that fixes one evasion family makes the model globally more robust.
Why This Is Not Just “Obfuscation Fooling a Classifier”
At a high level, it is easy to say: “A classifier overfit to indicators can be fooled by changing the indicators”, but the real explanation is more subtle. The interesting part is what changed through fine-tuning.
Foundation-Sec and Llama share the same underlying architecture and inherit a similar classification circuit. Foundation-Sec is better on the baseline task, but it is also more brittle under specific transformations. This means the vulnerability is not simply a generic weakness of the base architecture. It is tied to how fine-tuning reshaped the inherited circuit.
In successful evasion cases, the internal malicious signal does not simply vanish. The late attention route can still carry evidence that the script is malicious. The failure appears in feed-forward computation near the classification boundary: fine-tuned components change how that evidence is used. In some cases, the evidence is effectively reversed, turning what should support a malicious classification into support for a benign one.
This is why we describe the failure as learned semantics on top of inherited circuits. The inherited route still exists. Fine-tuning changes the meaning and weighting of the indicators that feed into the final decision.
A Pre-Deployment Monitoring Method
The practical question is: can we identify the risky command families before generating a large evasion benchmark? Our answer is yes, at the family level.
1. Linear Probe for Representation Drift
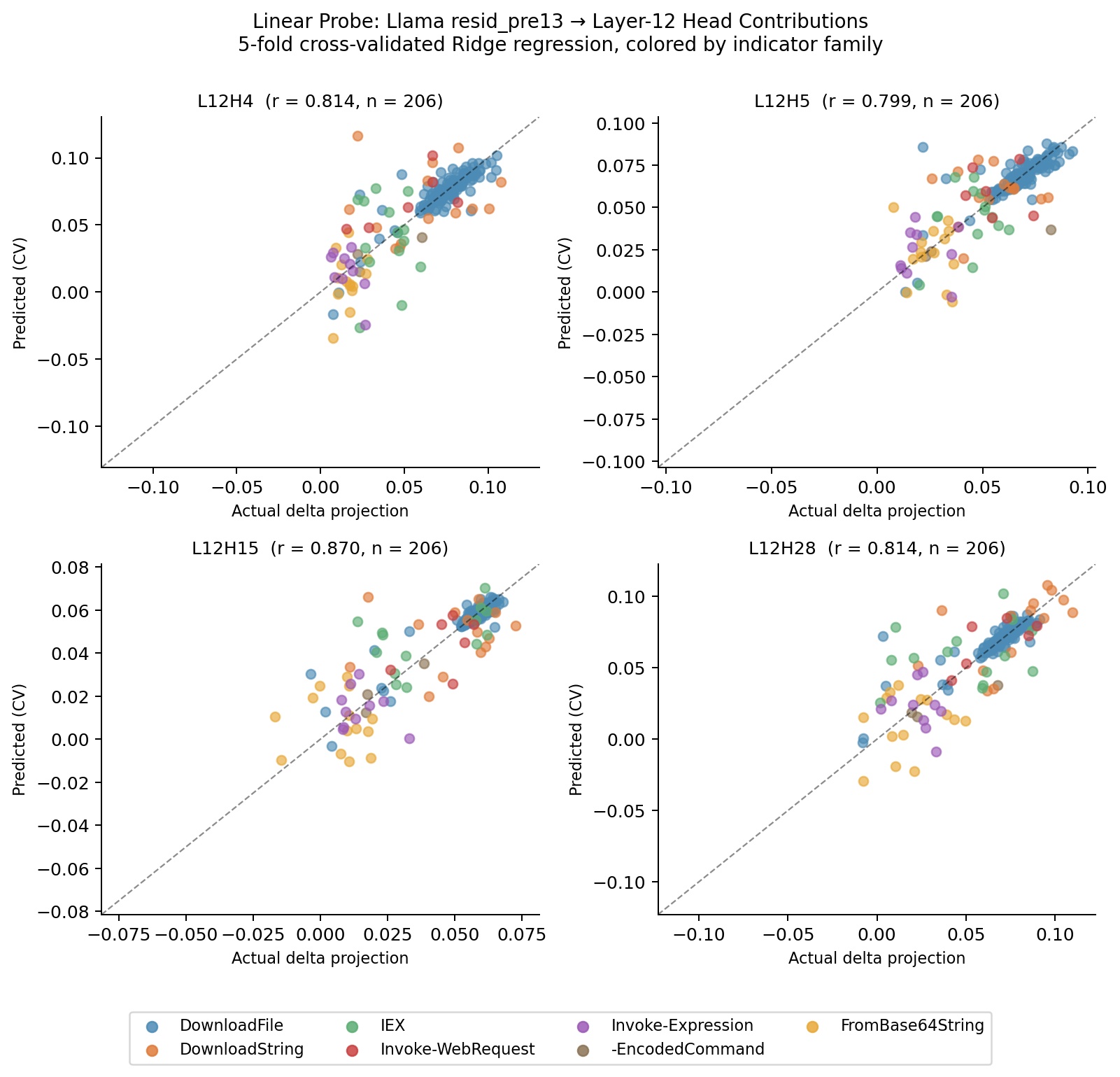
First, we train a simple linear probe on a hidden activation near the model’s classification boundary. In our study, circuit analysis told us where to look: the residual stream just before Layer 13. But the broader method is not tied to that exact layer. The important idea is to choose a stable internal site where classification evidence is readable, train a lightweight linear readout on the base model, and reuse that readout after fine-tuning.
The probe works well in our setting, with correlations around r = 0.80-0.87. This means the model’s internal classification evidence can be monitored with a cheap linear projection.
A team can then run the base and fine-tuned models on canonical inputs, apply the same projection, and compare the result by command family. Families whose projected signal shifts the most become the first red-team targets.
2. Indicator-Token Sign Test
The second signal is more targeted. For each command family, we remove or neutralize the canonical indicator tokens and measure whether malicious confidence goes up or down.
If removing a token reduces malicious confidence, the token was acting as a driver of the malicious decision. If removing it increases malicious confidence, the token is acting like a suppressor.
The risky pattern is a sign flip between the base and fine-tuned models. If the base model treats an indicator as a malicious driver, but the fine-tuned model treats it as a suppressor, then that family has undergone a role reversal. That is a strong signal that behavior-preserving transformations of that indicator deserve red-team attention. The output is not a prediction for individual scripts. It is a ranked list of command families to red team.
What This Means for Security Teams
Fine-tuning can be valuable. The lesson is not to avoid fine-tuning security models. The lesson is to evaluate what fine-tuning changes.
Security fine-tuning changes more than task performance. It changes how the model internally represents and uses evidence. In our study, Foundation-Sec inherited a useful detection circuit from Llama, then specialized in a way that improved baseline behavior but introduced transformation-sensitive failures.
Standard held-out accuracy tells us whether the model performs well on familiar examples. It does not tell us whether the model has become brittle to behavior-preserving variants. For security classification, that gap matters because attackers can change surface form while preserving behavior.
The practical recommendation is straightforward: treat fine-tuning as a potential source of representation drift. Before deployment, compare the base and fine-tuned models on canonical inputs, identify which command families changed most, and red-team those families with behavior-preserving variants. The goal is not to predict every evasion. The goal is to find the parts of the task where fine-tuning may have made the model semantically brittle.
Llama is a trademark of Meta Platforms. PowerShell is a trademark of Microsoft. All other trademarks are the property of their respective owners.




