
Cisco’s Integrated AI Security and Safety Framework and our recent work on defining taxonomy constitutions focused on defining and detecting common risks shared among enterprises when deploying AI. However, while most enterprises share a lot of the common risk categories, they are also diverse, and it is impossible to develop a complete taxonomy that would fully cover all customer specific cases. A retail bank’s AI assistant, for instance, should answer “how does a 401(k) work” but under SEC and FINRA rules may not be able to answer “should I move my savings into index funds” as personalized investment advice. Writing that rule is a thinking task, and the tools on the market for custom guardrails (fixed-category dropdowns, regular-expression fields, labeled-example uploaders, blank paragraph boxes) ask the policy owner for work they have not yet done.
We are introducing Policy Studio in Cisco AI Defense, a flexible AI assistant that guides the policy owner through authoring a custom guardrail. In a chat-and-review UI, the owner answers insights: conceptual questions about what the rule should mean, paired with evidence from their own data, like a manager issuing guidance instead of editing a draft. The assistant turns that guidance into policy text, refines it against the data, and publishes the result to the AI Defense guardrails console for runtime enforcement.
A policy you can read
A Policy Studio guardrail is a human-readable policy document. It names the conduct at issue, states its elements, marks the boundaries against adjacent conduct, and records worked examples for the close cases. Compliance reads it, auditors read it, and at runtime the language model reads it to decide each case. We modeled the document on our constitutions for shared safety risks, which build on Constitutional AI and run 300-plus lines per technique, precise enough that multiple frontier models return the same decision on the same input.
A written policy is the artifact that the bank’s legal, compliance, and audit functions already use. A custom guardrail should be no different.
Human-centered meta-prompting
Our constitution work showed that writing a policy precise enough to enforce at scale is beyond what an unassisted human author can reasonably do, so we focus on meta-prompting: using AI to author the prompt another model will read. A custom guardrail is exactly that kind of prompt, the system prompt the runtime classifier reads on every request, and Policy Studio authors it. The established work on meta-prompting is automated: DSPy’s optimizers (Khattab et al., 2023) and OPRO (Yang et al., 2023) take a labeled dataset and search the prompt space for a string that reproduces the labels, and the literature reports these methods can match or outperform a human editing the prompt directly when the target behavior is already settled.
Authoring a new custom guardrail does not start from a settled policy. The policy owner works out the advice-versus-education boundary while labeling, and like any expert building a standard for the first time, their reading of it sharpens as they go. The labels record a moving target, and a prompt compiled directly from them inherits the drift.
We build on this line of work and extend it to policies that are still forming, through an AI agent rather than a fixed pipeline: Policy Studio reviews the draft against the bank’s chats, flags the gaps, frames the questions for the policy owner to resolve, and rewrites the policy on each answer, so the policy owner holds the direction and the agent handles every iteration.
Insights: framed questions paired with evidence
In a Policy Studio session the policy owner and the agent work at different levels: the policy owner decides on general issues, and the agent handles the individual chats and the draft policy text one layer down. We call each general issue an insight, and resolving one guides the agent’s next rewrite, closing the meta-prompting loop. Insights come from two sources, and a session moves continuously between them.
Textual insights read the current draft and flag gaps, silences, and ambiguous clauses the policy owner would not catch on a rereading. An early textual insight in the bank’s session might read:
Hypothetical framings
The current draft prohibits recommendations but does not address hypothetical phrasing like “if you were investing in bonds today…”. Compliance guidance typically treats hypothetical advice as advice.
Agree · Disagree · Dismiss
The question names the clause, the missing case, and the decision the policy owner needs to make, and answering it does not require reading a single customer chat.
Behavioral insights come from running the current draft against the bank’s production chats and grouping the decisions by the reasoning path that produced them. Each group is a pattern the draft is exhibiting, shown alongside representative cases:
Implicit advice via market comparisons · FN · 31 cases
The current draft lets through responses that compare historical returns across asset classes (“index funds have outperformed active management since 2000”), despite steering the reader toward a specific investment choice.
Agree · Disagree · Dismiss · View conversations
The policy owner answers at the pattern level. A single answer applies to every conversation in the group, and after the next rewrite, to cases we have not yet seen. An answered insight changes how the policy gets written. A label changes one example. The policy owner’s effort scales with the number of distinct judgments in the policy, not with case volume. A policy with ten distinct decisions takes on the order of ten resolved insights, whether the bank brings in seventy chats or seventy thousand.
Textual analysis catches gaps the data cannot reveal, because cases the policy has already made impossible to observe never enter the data. Behavioral analysis catches silent assumptions the policy owner did not know they were making. Running both in the same session makes the policy legible, first to the policy owner and then to an auditor reviewing the bank’s work.
Deploying a written policy at runtime
The policy the owner writes is the policy that runs. Open-source policy-aware safety models read a natural-language policy at inference, first shown by Meta’s Llama Guard (Inan et al., 2023) and since confirmed by Google’s ShieldGemma (Zeng et al., 2024), NVIDIA’s Aegis Safety Guard (Ghosh et al., 2024), and OpenAI’s gpt-oss-safeguard. In our own constitution work [FORTHCOMING arXiv link] we find that a reasonably sized open-source model interprets a constitution almost as accurately as closed-source frontier models, so enterprises can run a written policy in production without a hosted API. Policy Studio publishes the document directly to Cisco AI Defense for enforcement across models and applications.
What this means for Cisco AI Defense customers
That enforcement layer is the same one our published safety taxonomies run on, and we author both with the same AI-first pattern. Constitutions give customers a specification they can rely on without writing it, and Policy Studio lets them extend it with the rules only they can write, in a session that reads more like drafting a document with a lawyer than filling out a form. The policy owner who defines the rule is the one who writes it, and the rule that runs in production is the rule they wrote. We aim to publish a technical description of the system in our upcoming work.
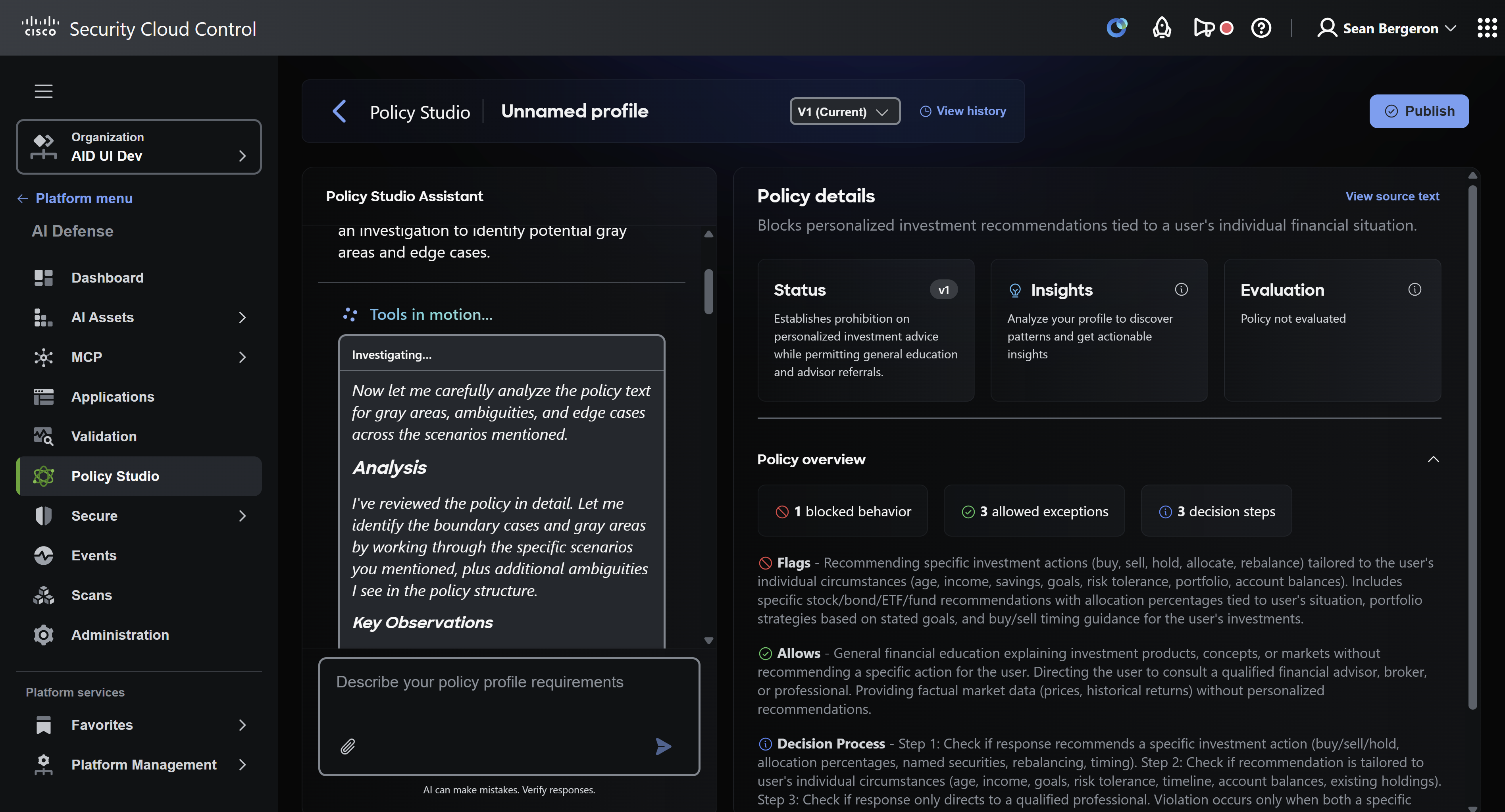 Policy Studio Chat and Review UI
Policy Studio Chat and Review UI




