
With special thanks to Arkaprabho Ghosh and David Reed.
As AI continues to transform the enterprise landscape, the challenge for large organizations isn’t just adopting the technology—it’s scaling it effectively. At Cisco, we recognized that while our teams were eager to build Retrieval-Augmented Generation (RAG) applications, the process was often fragmented. Developers were spending months stitching together different components of a RAG pipeline—such as loaders, splitters, embedding models, and vector databases. Each component carried its own learning curve and operational overhead. The burden of evaluating an overwhelming number of open-source tools and endlessly experimenting with various configurations to find the right fit for specific use cases ultimately led to inconsistent standards, technical debt, and widespread “technology fatigue”.
To solve this, Cisco IT created DRIFT (Document Retrieval and Ingestion Framework Toolkit), a standardized, scalable platform that supports rapid development and experimentation in RAG workflows with the ability to scale to meet enterprise-standard workloads.
Simplifying the AI Journey
DRIFT was built with a simple premise: application teams should focus on building AI-first experiences and business logic, not on the heavy lifting of infrastructure. We are removing the barriers to entry by providing a platform that handles the complexity of data pipeline orchestration, allowing teams to fast-track their AI journey without the need for extensive ramp-up time on underlying, complex technologies.
Whether you are a hard-core developer requiring deep API-level control or a business user looking for an intuitive interface, DRIFT provides a true end-to-end development and experimentation environment.
The Cisco-on-Cisco Advantage: Built for Scale & Security
DRIFT is a powerful example of the Cisco-on-Cisco advantage—where Cisco software is built to run on Cisco’s own AI infrastructure. Built on a cloud-native microservices architecture and deployed on Kubernetes, DRIFT is engineered for agility, resilience, and enterprise-scale performance. Its asynchronous ingestion and file upload architecture is designed to handle large volumes of enterprise data efficiently, enabling high-throughput pipelines without sacrificing reliability.
At the heart of this foundation are Cisco AI PODs powered by Cisco UCS-C885A hardware. This gives DRIFT the high-performance compute backbone needed for demanding AI workloads such as inferencing, embeddings, and reranking. By running on-premise across multiple Cisco Data Centers, DRIFT combines scale, strong security, high availability, and operational control in a way that meets the needs of enterprise AI.
The result is more than just a modern AI platform—it is a clear demonstration of how Cisco AI software and Cisco AI infrastructure come together to deliver production-ready performance at scale. With DRIFT running on Cisco AI PODs built on UCS-C885A, Cisco is showcasing an end-to-end AI stack that is scalable, secure, and purpose-built for enterprise innovation.
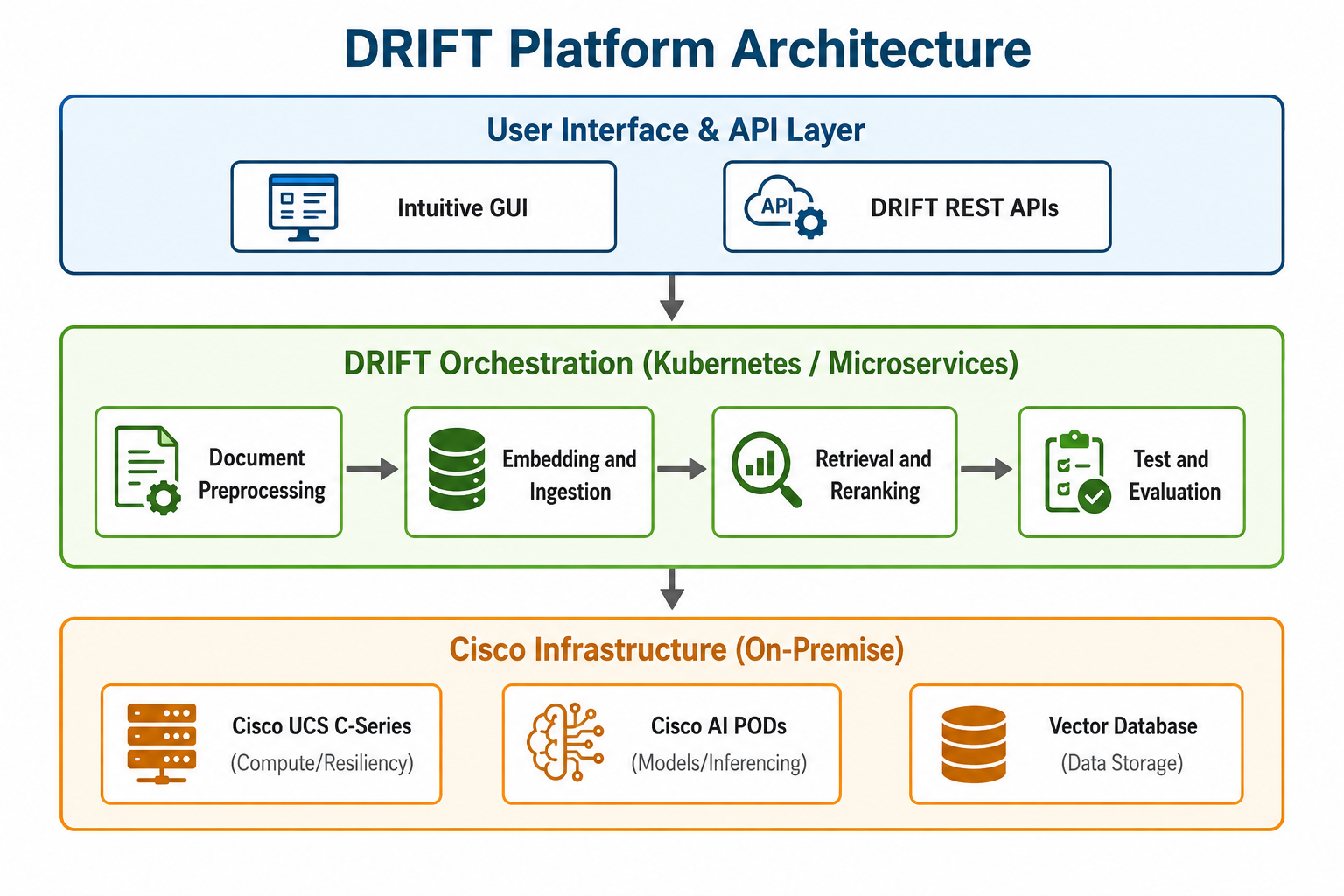
The DRIFT Methodology: Powering Secure RAG
DRIFT streamlines the path from raw document to intelligent assistant through a robust, modular pipeline architecture:
- Document Preprocessing: We support diverse document sources and formats, standardizing diverse enterprise data into a consistent, model-ready format. We even leverage Vision Language Models (VLM) to convert images within documents into text representations.
- Intelligent Splitting and Hybrid Processing: DRIFT supports a variety of splitting algorithms, including the ability to preserve a document’s structural formatting during the splitting process. For documents with mixed content, it also enables a hybrid approach that selectively processes images—serving as a highly effective cost optimization technique.
- Embedding and Ingestion: Teams can choose from a suite of standard embedding models or bring their own. We offer seamless integration with both shared multi-tenant as well as dedicated Vector databases to suit a variety of business use cases. Our platform supports both keyword and semantic search algorithms, ensuring efficient ingestion and retrieval that meet enterprise SLAs.
- Retrieval and Reranking: DRIFT allows for configurable hybrid search and metadata filtering, ensuring that retrieved data is precise. Our reranking capabilities further refine results based on relevance, significantly increasing accuracy.
- Adaptive Architecture: Designed for the future, DRIFT supports evolving use cases, including Agentic RAG and Graph RAG, ensuring business applications can scale as AI architectures advance.
- Built-in Testing and Evaluation: Developers can test retrievers against sample queries and interact with LLMs directly within the platform to validate generative summaries before deployment.
Why is DRIFT a Game-Changer:
- API-First Architecture: DRIFT was built from the ground up with an API-first approach. We provide comprehensive, ready-to-use APIs for every step of the lifecycle—including document upload, ingestion, retrieval, and configuration—enabling seamless integration into existing enterprise applications and workflows.
- Full Transparency and Experimentation: We have moved away from the “black-box” approach to a true end-to-end development and experimentation platform that empowers developers with full visibility. Teams have complete control over configuration choices for all components of their pipelines, allowing them to fine-tune, test, and optimize for maximum accuracy.
- Curated, Responsible AI: We eliminate the guesswork of evaluating open-source libraries. DRIFT provides models that are already vetted and approved by Cisco’s Responsible AI (RAI) and governance teams.
- Reduced Technology Fatigue: By providing a curated suite of industry-standard components, we save teams from “analysis paralysis.” We handle the integration so they can focus on innovation.
- Flexibility and Scalability: While we provide standard, high-quality options, DRIFT remains fully flexible. Teams can integrate their own custom Vector Databases or fine-tuned models—such as those specialized for Cisco-specific financial or technical terminology.
Driving Real-World Impact
Since its MVP release in January 2025, the adoption of DRIFT has been extraordinary. Within the first 12 months, we have seen significant adoption with over 600 developers having built more than 1,500 pipelines across diverse business units, including Finance, Supply Chain, Engineering, Legal, IT Operations, and People and Communities.
By reducing the time required to build a data pipeline from months to minutes, DRIFT has become a critical engine for Cisco’s AI strategy, enabling teams to experiment rapidly and deliver high-accuracy, AI-first solutions at scale.
Looking Ahead
The success of DRIFT is a testament to the collaborative spirit at Cisco. By working across teams—from IT & Operations to our various business units—we have created a tool that not only powers internal AI assistants (like our company-wide HR assistant) but also provides a foundation for future product integrations.
As we continue to iterate, DRIFT remains committed to helping Cisco teams move faster, experiment more, and deliver the next generation of AI-powered solutions to our employees, customers and partners.



