Tim Harmon is a Cisco Champion, an elite group of technical experts who are passionate about IT and enjoy sharing their knowledge, expertise, and thoughts across the social web and with Cisco. The program has been running for over four years and has earned two industry awards as an industry best practice. Learn more about the program at http://cs.co/ciscochampion.
==========================================
Welcome to Part 2 of the Cyber Security Capture the Flag (CTF) series. Part 1 discussed the importance of planning and how to effectively design the CTF event. Once the planning and designing phase has occurred, it is time to start developing the CTF. In this phase, we will discuss what needs to be done in order to implement the event. This will include securing a venue, getting the equipment (software and hardware) and setting everything up.
The first thing in this phase that is extremely important is for the venue to be secured. The venue can be located in an office, classroom or even a gymnasium as long as there is Internet and electrical access. For example, some companies have hackathons (2 to 5 day competitions with programming) in gymnasiums such as LAHack and NYHack. The area needs to be big enough for the CTF event you are planning to implement. This means, if you want to have a Jeopardy-style CTF that has 10 teams of 4 to 5 people, then you need to have a big room with a minimum of 12 tables (10 for the teams, 1 for the servers and 1 for the sign-in and misc.). The team should get a contract signed with the company that is providing the team with the venue for the CTF event after the plan and design has been laid out.

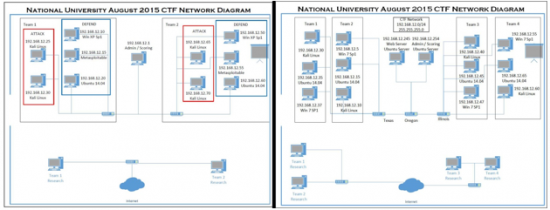
Securing a venue was the hardest part of the event as the event date was getting closer and we were unsure of where we were going to have it. Luckily, one of our professors at National University talked with us about our situation and since he was the Dean of Technology at Coleman University, he was able to secure his lab room for us to use. With him allowing us to use the lab, we were able to concentrate on getting the software and challenges ready to put onto the equipment. After securing the venue, we needed to check out the lab and make sure that it had everything we needed for the event. One thing that was not expected, we ran into problems as we tried to attack the defending machines from the attacking machines. Since the workstations were part of the school, the IT department had placed anti-virus software on them for other lab usage and we could not do what we wanted to do. It caused us to run a Jeopardy-style CTF instead of a hybrid (Jeopardy-style and Attack/Defend). The figure below shows the different network diagrams we developed for the CTF (Hybrid, then Jeopardy).
The team needs to then ensure that all equipment is at the venue and working properly. You may need to change out some hardware, or even reimage a workstation or server, as things may have happened before the venue and equipment were secured for the event. When everything is working properly and there is no need to replace or repair anything, the software for the CTF event can be put onto the workstations. The software used for the CTF can include Windows, Linux (Ubuntu, Red Hat, Fedora, CentOS) and Kali Linux.
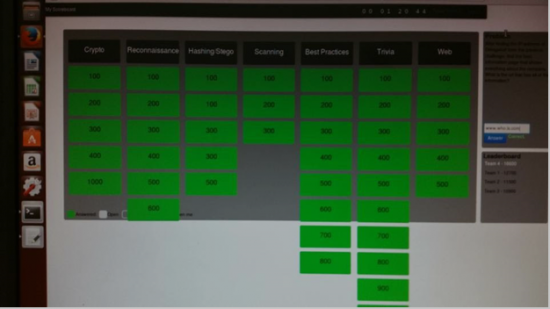
The scoreboard for the CTF can be as simple as using Microsoft Excel with a timer and the team manually inputs the scores (if doing attack/defend), or it can be complex with a scoreboard framework that has already been developed. My team used the PTCoreSec scoreboard (https://github.com/PTCoreSec/CTF-Scoreboard) as it was pretty simple to implement but more complex than doing the Microsoft Excel spreadsheet scoreboard. Some CTF events use the iCTF framework from the UC Santa Barbara International Capture The Flag (iCTF) Competition (https://ictf.cs.ucsb.edu) and a few will use Facebook’s CTF platform (https://github.com/facebook/fbctf). Your team can choose whichever CTF scoreboard that will work with the requirements you have for the CTF event. The figure below shows what my team’s PTCoreSec scoreboard looked like. If you have ever participated in the National Cyber League (NCL, https://www.nationalcyberleague.org), you can notice that their CTF is based on the PTCoreSec scoreboard but much more high tech.
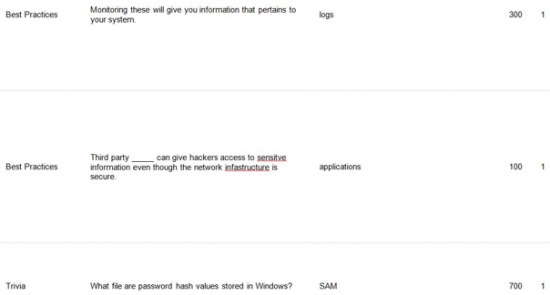
The next component of developing the CTF event is coming up with the different challenges. There should be different levels of challenges ranging from easy to hard and it would be wise to let the participants know what tools they can use and what tools that are not allowed to use. For example, they can use NMAP to scan the IP address range you give them for a challenge but cannot use Shodan for it. Shodan actually scans the entire Internet and it can get government officials to come visit you. There are a lot of free tools that can be used to complete the challenges and they should be on the machines the participants will be using (if the team hosting the event is providing the equipment) or have the participants download the tools on their own laptops that they brought to the event. Below are a few examples of challenges that were used in my team’s CTF.
After the challenges are created, they need to be placed into the scoreboard and the team needs to ensure all of the tools are on the appropriate devices for the event. Once that is done, the team needs to test all of the challenges and make sure that the answers are able to be inputted into the scoreboard. If any of the testing fails, the challenge needs to be tweaked or replaced by a different challenge. There should be a final test run the day before the CTF event as something could change and then the system should be tested an hour before the event starts to ensure it is responding properly. There needs to be a process that will be done if any issues arise during the event. The next phase will be the implementation phase of the CTF where the team will implement the CTF event. Be on the lookout for Part 3: Implementing in the Cyber Security CTF Blog Series.