
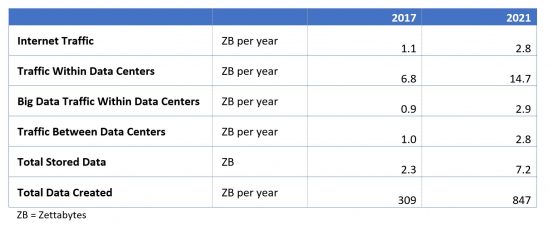
The scale of the Internet is awe-inspiring. By 2021, there will be 4.6 billion people and 27 billion devices connected to the Internet, and Internet traffic will reach 2.8 trillion Gigabytes (or 2.8 Zettabytes) per year. (These numbers are published in our annual Visual Networking Index.)
Even with multiple Zettabytes crossing the network each year, there are some things that dwarf even the Internet. We started the Global Cloud Index (GCI) seven years ago in order to capture the scale of data more generally, as it relates to the advent of the cloud. In our most recent report, there are five categories of data that meet or exceed Internet traffic volume by 2021.
- Traffic Within Data Centers
- Big Data Traffic Within Data Centers
- Traffic Between Data Centers (Almost)
- Volume of Data Stored in Data Centers and on Devices
- Volume of Data Created Per Month
- Traffic Within Data Centers
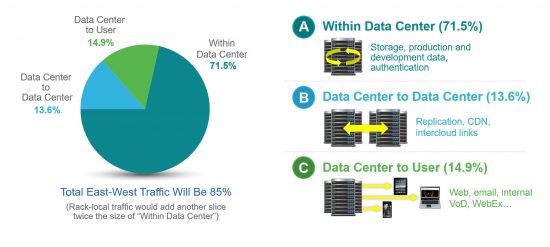
We estimate that total data center traffic (all traffic within or exiting a data center) will reach almost 20 zettabytes per year by 2021. The largest segment is the traffic that transits the interior of the data center (from rack to rack) without leaving the datacenter, and this “Within Data Center” traffic will reach nearly 15 zettabytes per year by 2021.
Why is there so much more traffic remaining within the data center than leaving it? It turns out a number of Internet applications are extremely “chatty”. A search query, for instance, may be multiplied hundred-fold within the data center as it is sent to multiple servers for processing. A social networking transaction has a similar multiplier effect, as it draws in an entire social graph to respond to a single query. And the architecture of data centers can contribute to the amount of traffic, with separate storage arrays, separate development and production server pods, and separate application server clusters that all need to talk to one another.
The transition to SDN within the data center can help reduce the amount of traffic within the data center, and we estimate that by 2021, 50% of traffic within data centers will be handled by SDN.
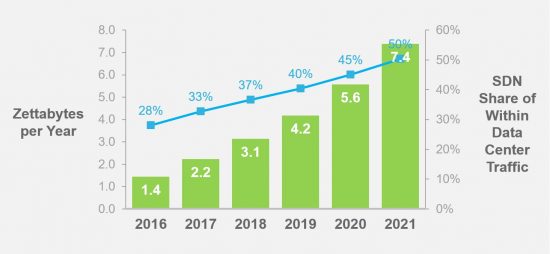
SDN allows for traffic handling policies to follow virtual machines and containers rather than the other way around. With greater mobility, workloads can be re-located within a data center to eliminate any bandwidth bottlenecks.
- Big Data Within Data Centers
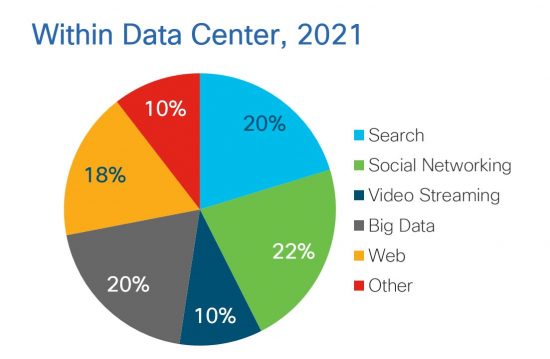
A subset of traffic within the data center (described above), traffic associated with big data within data centers will reach 2.9 zettabytes per year by 2021, compared to the Internet’s 2.8 zettabytes per year. Big data, defined as data deployed in a distributed processing and storage environment, is a key driver of overall data center traffic. By 2021, big data will account for 20 percent of all traffic within the data center, up from 12 percent in 2016.
- Traffic Between Data Centers (Almost)
Traffic between data centers will nearly equal Internet traffic by 2021, at 2.8 Zettabytes. Driven by multicloud and by content delivery networks, an entire Internet’s worth of traffic will be crossing the lines connecting data centers by 2021. Historically, this has not been the case. One video might be delivered to 1000 users, but that video generally only needs to be sent once between data centers. The “Internet scale” milestone for data center to data center traffic is significant – it means data centers (and the cloud applications within them) are starting to need to talk to each other as much as they talk to the end users.
Globally, traffic between data centers is growing faster than traffic within data centers and faster than traffic to end users, as a CAGR of 33% from 2016 to 2021.
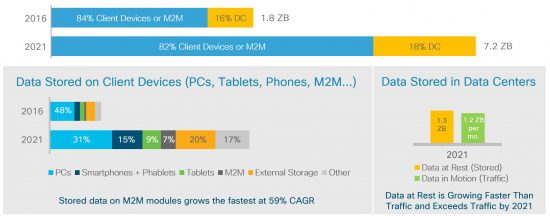
- Total Stored Data
The total amount of data stored in data centers and on users devices will reach 7.2 Zettabytes by 2021, several times higher than the 2.8 Zettabytes of annual Internet traffic. The majority of this stored data resides on end-user devices – PCs, smartphones, tablets, and (increasingly) IoT or M2M devices. More of this data is moving to the cloud over time, with data stored within data centers growing from 16 percent in 2016 to 18 percent in 2021. But there is still a lot of data stored on edge devices, and there appears to be a need to blur the boundaries of the data center in order to allow the intelligence associated with data center big data to encompass even “bigger” data – the data outside the data center.
- Total Data Created
The biggest data of all, and the biggest number we track in any of our efforts, is the total amount of data created each year – not only data created by people, but also machines (including industrial equipment that may not be directly connected to a network). This data will amount to nearly 850 Zettabytes per year by 2021 – which means we are approaching the yottabyte scale for annual data generation (one yottabyte is 1,000 zettabytes). Not all data created is useable or useful. A Boeing 787 can generate 40 terabytes of data per hour, though generally less than half a terabyte of that is retained. But there is a vast quantity of data created that is potentially useful that is not being captured today. An example is the data generated during the course of an ultrasound. An entire video feed is generated, but what is retained are a few dozen snapshots only. As AI-enabled diagnosis matures, the video associated with the entire scan will be useful.
We estimate that at least 10 percent of the 850 Zettabytes created is useful. That means that there will be 85 zettabytes of useful data created in 2021, but there will be only 7 Zettabytes of stored data in that year. This implies there is an opportunity for fog or edge computing – bringing the intelligence to the data instead of the data to the intelligence.

Implications
Will all data be Internet data some day? While the trend towards cloud does imply that an increasing amount of data storage and processing will be done within a data center as time goes by, the overall data landscape will remain highly distributed for the foreseeable future. Machines will generate large amounts of data on the edge, and it will not be feasible or even desirable to move all this data to a datacenter. The cloud of the future will evolve into more of a fog, with intelligence distributed to the extremities of the network.
There is a wealth of content in our most recent report, this blog post only covers a few aspects. See the below links to get you started.
- View our infographic: Growth in the Cloud.
- Visit the Cisco Global Cloud Index webpage.
- Read the Cisco Global Cloud Index, Forecast and Methodology, 2016–2021 White Paper.
- Explore the Cisco Global Cloud Index Highlights Tool.





