
It’s evident from the amount of news coverage, articles, blogs, and water cooler stories that artificial intelligence (AI) and machine learning (ML) are changing our society in fundamental ways—and that the industry is evolving quickly to try to keep up with the explosive growth.
Unfortunately, the network that we’ve used in the past for high-performance computing (HPC) cannot scale to meet the demands of AI/ML. As an industry, we must evolve our thinking and build a scalable and sustainable network for AI/ML.
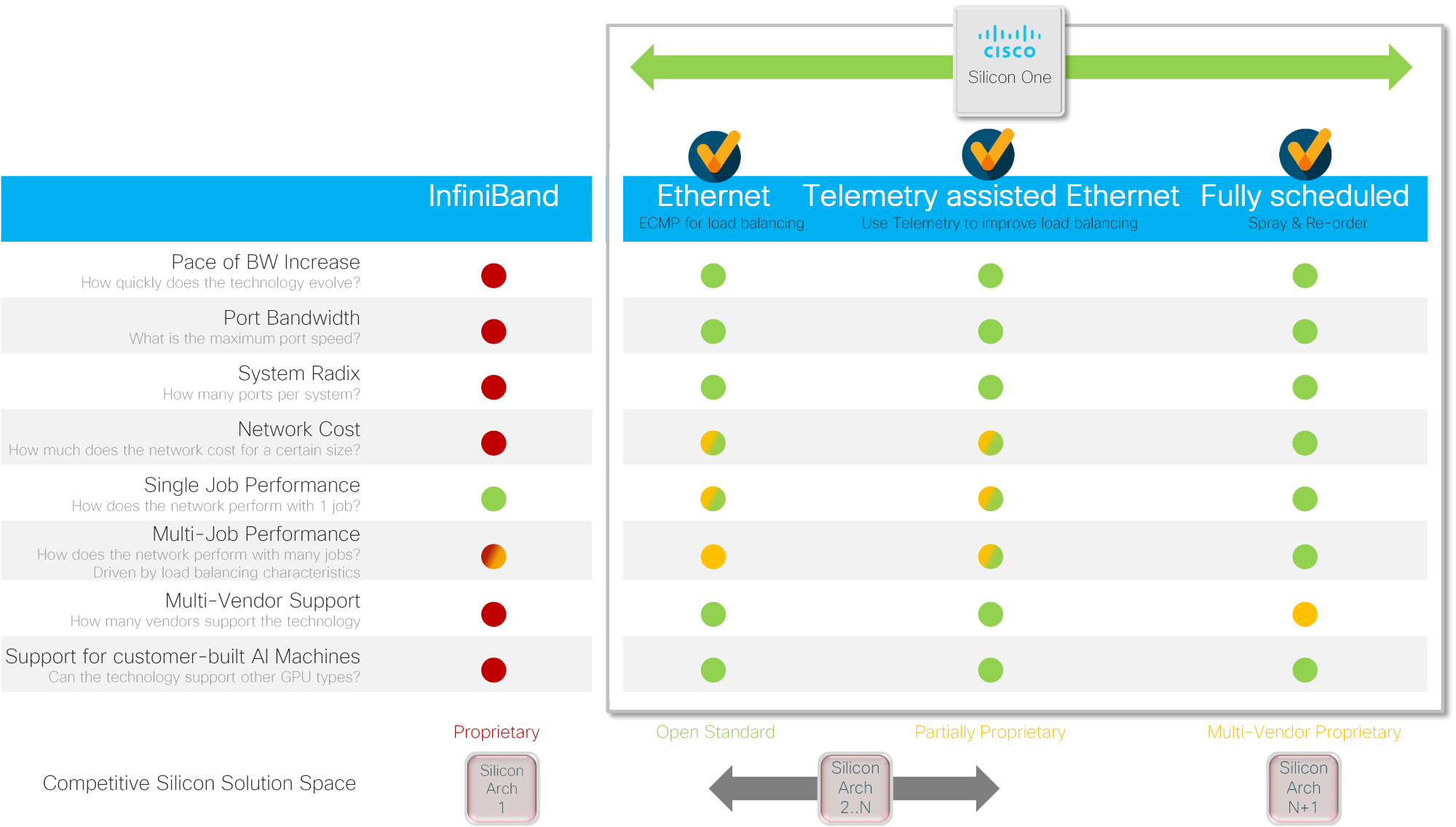
Today, the industry is fragmented between AI/ML networks built around four unique architectures: InfiniBand, Standard Ethernet, Enhanced Ethernet, and Scheduled Ethernet.
Each technology has its pros and cons, and various tier 1 web scalers view the trade-offs differently. This is why we see the industry moving in many directions simultaneously to meet the rapid large-scale buildouts occurring now.
This reality is at the heart of the value proposition of Cisco Silicon One.
Customers can deploy Cisco Silicon One to power their AI/ML networks and configure the network to use Standard Ethernet, Enhanced Ethernet, or Scheduled Ethernet. As workloads evolve, they can continue to evolve their thinking with Cisco Silicon One’s programmable architecture.
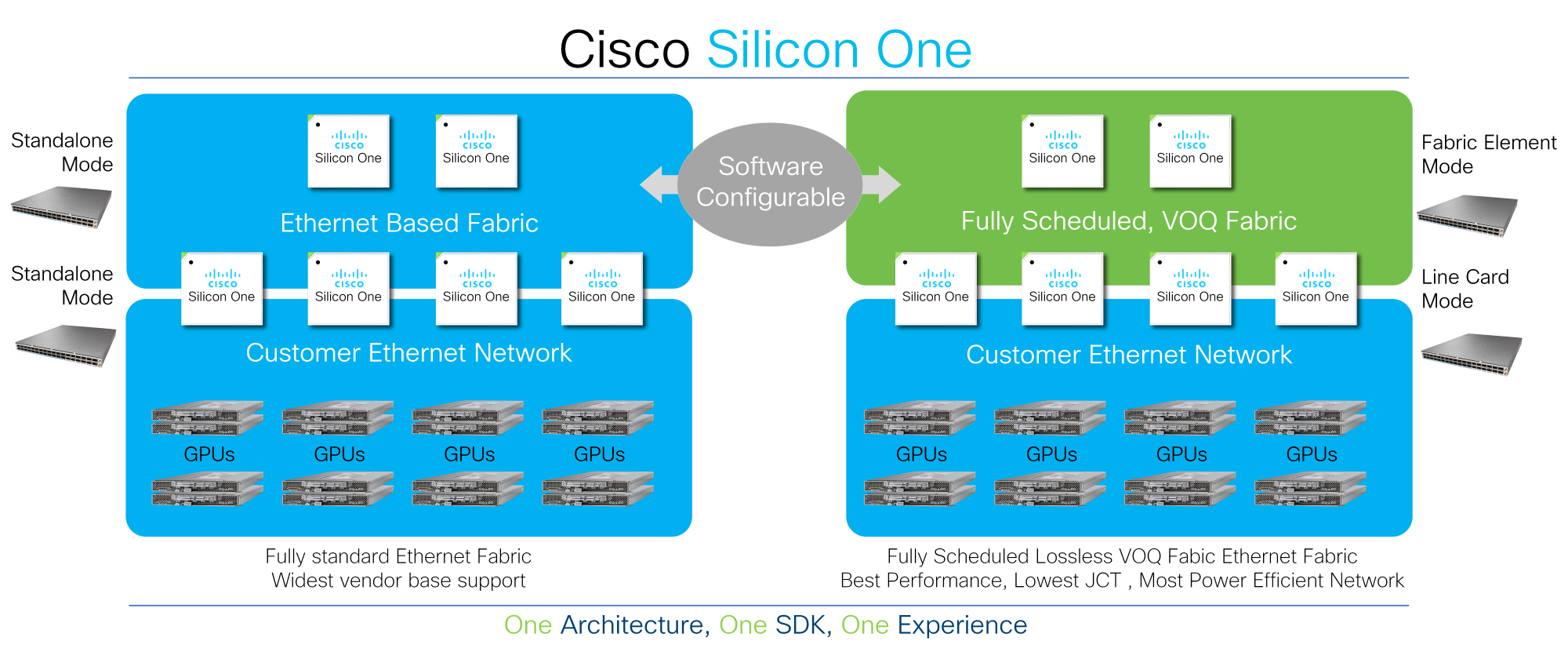
All other silicon architectures on the market lock organizations into a narrow deployment model, forcing customers to make early buying time decisions and limiting their flexibility to evolve.
Cisco Silicon One, however, gives customers the flexibility to program their network into various operational modes and provides best-of-breed characteristics in each mode. Because Cisco Silicon One can enable multiple architectures, customers can focus on the reality of the data and then make data-driven decisions according to their own criteria.
To help understand the relative merits of each of these technologies, it’s important to understand the fundamentals of AI/ML. Like many buzzwords, AI/ML is an oversimplification of many unique technologies, use cases, traffic patterns, and requirements. To simplify the discussion, we’ll focus on two aspects: training clusters and inference clusters.
Training clusters are designed to create a model using known data. These clusters train the model. This is an incredibly complex iterative algorithm that is run across a massive number of GPUs and can run for many months to generate a new model.
Inference clusters, meanwhile, take a trained model to analyze unknown data and infer the answer. Simply put, these clusters infer what the unknown data is with an already trained model. Inference clusters are much smaller computational models. When we interact with OpenAI’s ChatGPT, or Google Bard, we are interacting with the inference models. These models are a result of a very significant training of the model with billions or even trillions of parameters over a long period of time.
In this blog, we’ll focus on training clusters and analyze how the performance of Standard Ethernet, Enhanced Ethernet, and Scheduled Ethernet behave. I shared further details about this topic in my OCP Global Summit, October 2022 presentation.
AI/ML training networks are built as self-contained, massive back-end networks and have significantly different traffic patterns than traditional front-end networks. These back-end networks are used to carry specialized traffic between specialized endpoints. In the past, they were used for storage interconnect, however, with the advent of remote direct memory access (RDMA) and RDMA over Converged Ethernet (RoCE), a significant portion of storage networks are now built over generic Ethernet.
Today, these back-end networks are being used for HPC and massive AI/ML training clusters. As we saw with storage, we are witnessing a migration away from legacy protocols.
The AI/ML training clusters have unique traffic patterns compared to traditional front-end networks. The GPUs can fully saturate high-bandwidth links as they send the results of their computations to their peers in a data transfer known as the all-to-all collective. At the end of this transfer, a barrier operation ensures that all GPUs are up to date. This creates a synchronization event in the network that causes GPUs to be idled, waiting for the slowest path through the network to complete. The job completion time (JCT) measures the performance of the network to ensure all paths are performing well.
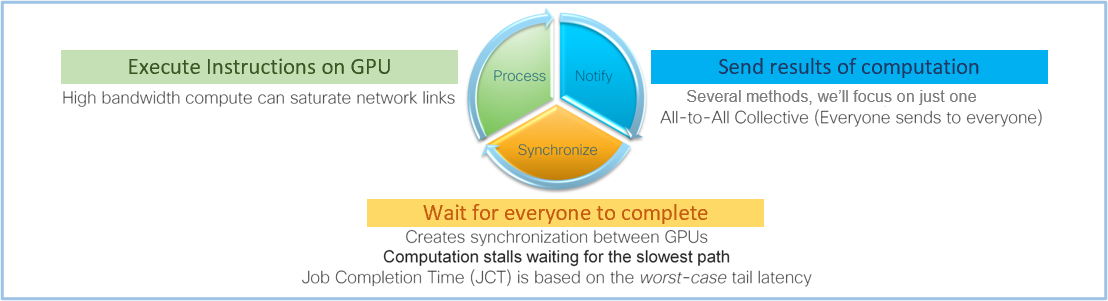
This traffic is non-blocking and results in synchronous, high-bandwidth, long-lived flows. It is vastly different from the data patterns in the front-end network, which are primarily built out of many asynchronous, small-bandwidth, and short-lived flows, with some larger asynchronous long-lived flows for storage. These differences along with the importance of the JCT mean network performance is critical.
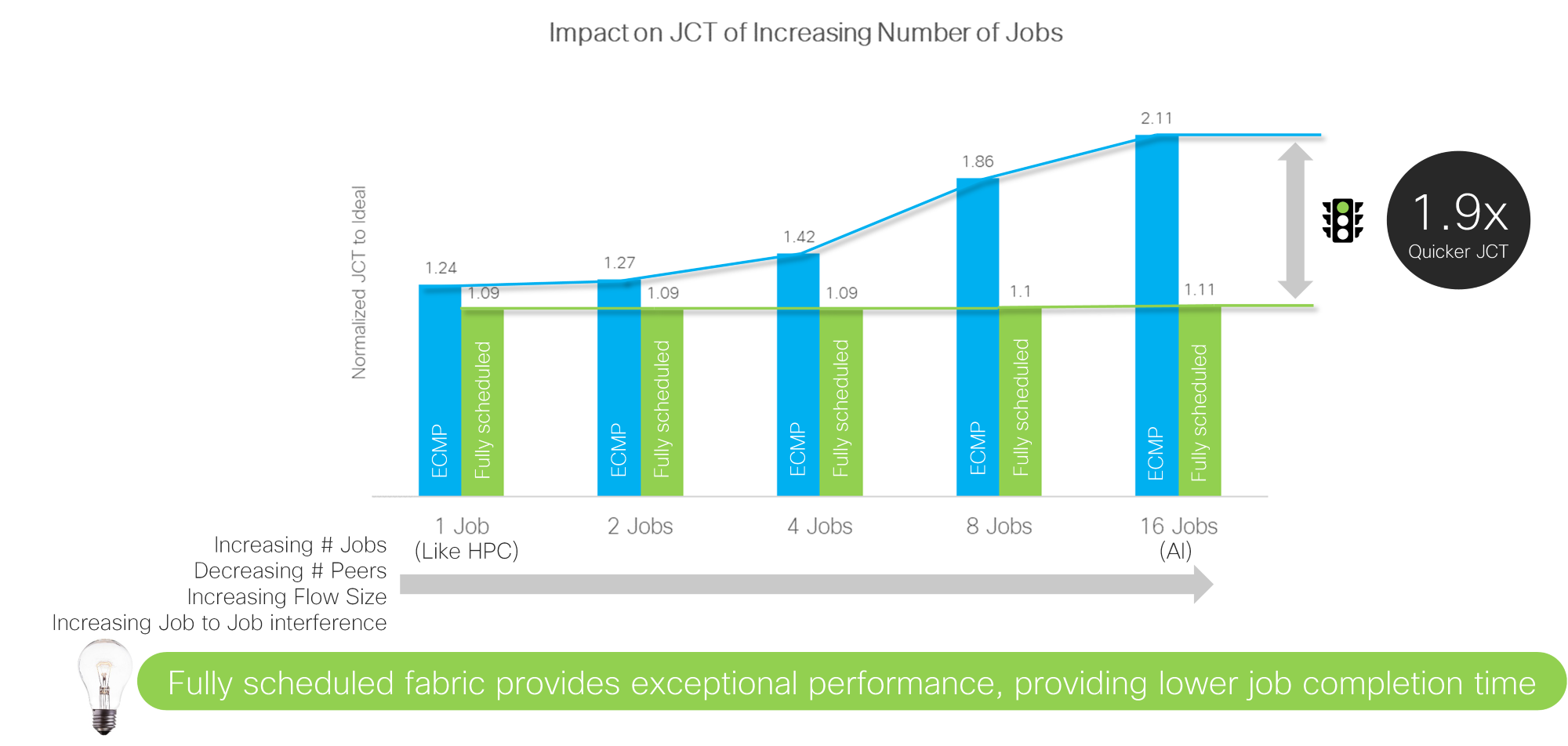
To analyze how these networks perform, we created a model of a small training cluster with 256 GPUs, eight top of rack (TOR) switches, and four spine switches. We then used an all-to-all collective to transfer a 64 MB collective size and vary the number of simultaneous jobs running on the network, as well as the amount of network in the speedup.
The results of the study are dramatic.
Unlike HPC, which was designed for a single job, large AI/ML training clusters are designed to run multiple simultaneous jobs, similarly to what happens in web scale data centers today. As the number of jobs increases, the effects of the load balancing scheme used in the network become more apparent. With 16 jobs running across the 256 GPUs, a Scheduled Ethernet results in a 1.9x quicker JCT.
Studying the data another way, if we monitor the amount of priority flow control (PFC) sent from the network to the GPU, we see that 5% of the GPUs slow down the remaining 95% of the GPUs. In comparison, a Scheduled Ethernet provides fully non-blocking performance, and the network never pauses the GPU.
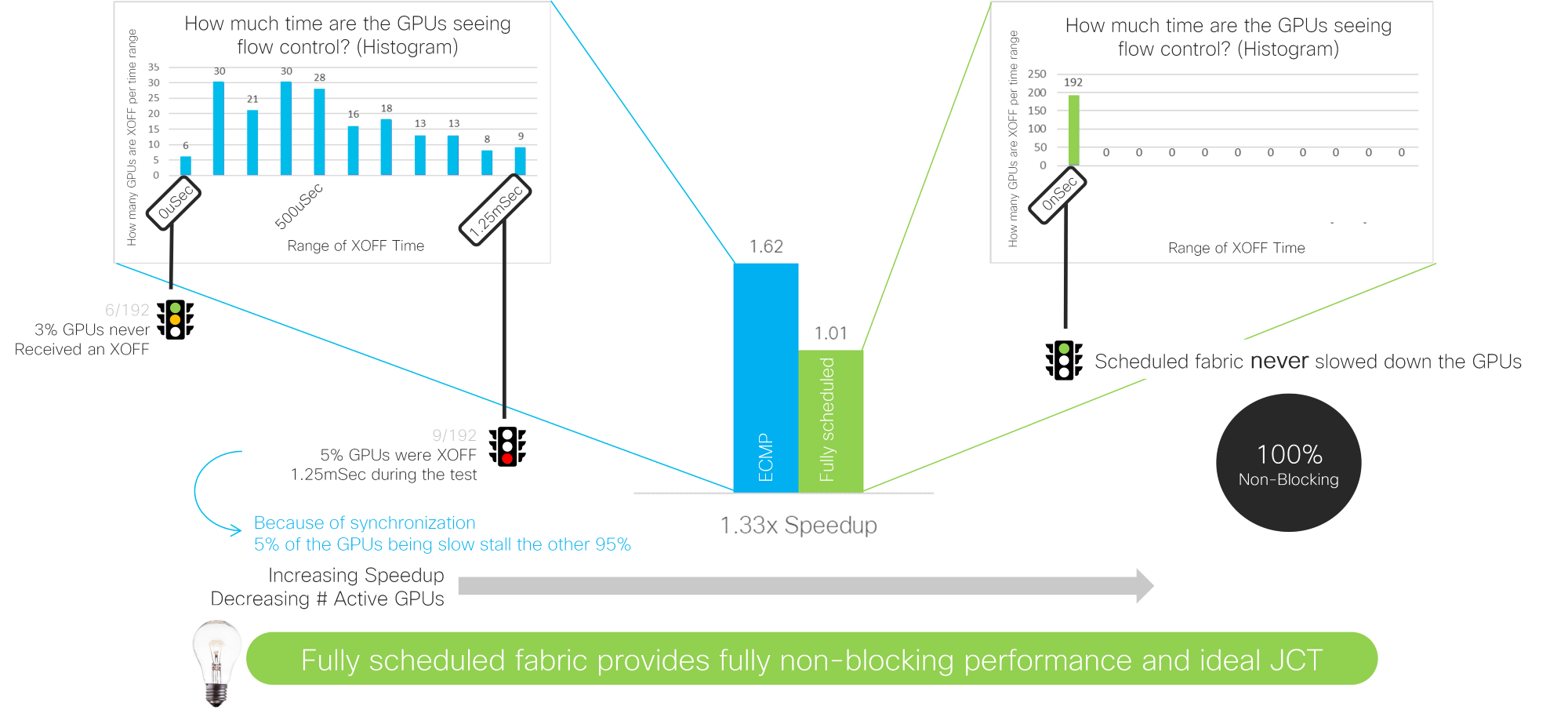
This means that for the same network, you can connect twice as many GPUs for the same size network with Scheduled Ethernet. The goal of Enhanced Ethernet is to improve the performance of Standard Ethernet by signaling congestion and improving load balancing decisions.
As I mentioned earlier, the relative merits of various technologies vary by each customer and are likely not constant over time. I believe Standard Ethernet, or Enhanced Ethernet, although lower performance than Scheduled Ethernet, are an incredibly valuable technology and will be deployed widely in AI/ML networks.
So why would customers choose one technology over the other?
Customers who want to enjoy the heavy investment, open standards, and favorable cost-bandwidth dynamics of Ethernet should deploy Scheduled Ethernet for AI/ML networks. Scheduled Ethernet is also great for customers who want to save cost and power by removing network elements, yet still achieve the same performance as Ethernet, with 2x more compute for the same network.
They can improve the performance by investing in telemetry and minimizing network load through careful placement of AI jobs on the infrastructure.
Customers who want to enjoy the full non-blocking performance of an ingress virtual output queue (VOQ), fully scheduled, spray and re-order fabric, resulting in an impressive 1.9x better job completion time, should deploy Scheduled Ethernet for AI/ML networks. Scheduled Ethernet is also great for customers who want to save cost and power by removing network elements, yet still achieve the same performance as Ethernet, with 2x more compute for the same network.
Cisco Silicon One is uniquely positioned to provide a solution for either of these customers with a converged architecture and industry-leading performance.

Learn more:
Read: AI/ML white paper
Visit: Cisco Silicon One







Way to go Cisco, I am a student and am learning about your company. To see the challenges you went through in 2021 and still be strong and innovative is inspiring and brave. Wishing you the best,
Thanks David. It’s a great time to work for Cisco. I myself have been here since 1997 and I can easily say that it’s the most exciting time to be an engineer at Cisco. Innovation at its finest !