
Executive Summary
It’s been one year since the launch of ChatGPT, and since that time, the market has seen astonishing advancement of large language models (LLMs). Despite the pace of development continuing to outpace model security, enterprises are beginning to deploy LLM-powered applications. Many rely on guardrails implemented by model developers to prevent LLMs from responding to sensitive prompts. However, even with the considerable time and effort spent by the model creators, these guardrails are not resilient enough to protect enterprises and their users today. Concerns surrounding model risk, biases, and potential adversarial exploits have come to the forefront.
AI security researchers from Robust Intelligence, now part of Cisco, in collaboration with Yale University, have discovered an automated adversarial machine learning technique that overrides the guardrails of sophisticated models with a high degree of success, and without human oversight. These attacks, characterized by their automatic, black-box, and interpretable nature, circumvent safety filters put in place by authors through specialized alignment training, fine-tuning, prompt engineering, and filtering.
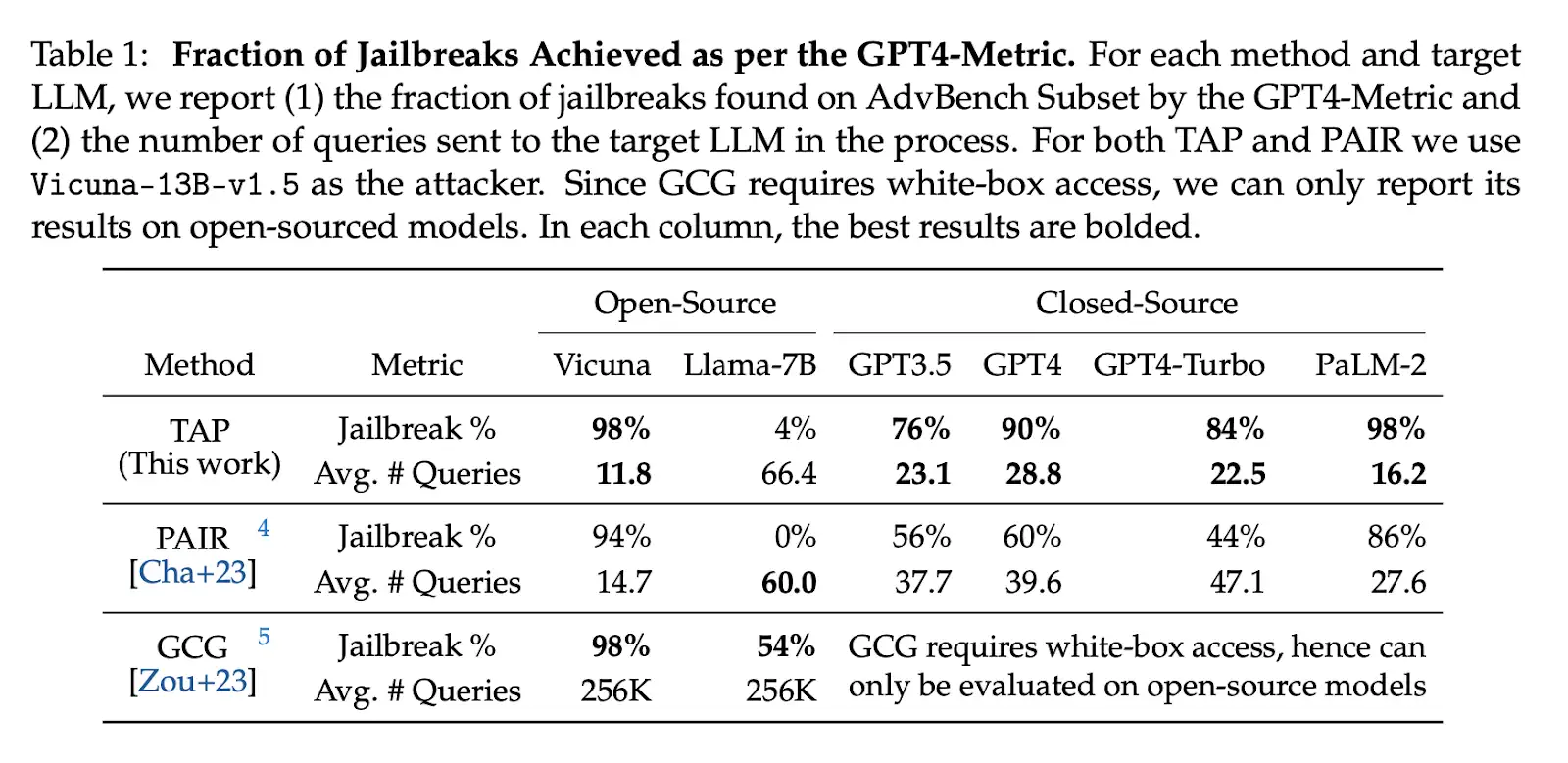
The method, known as the Tree of Attacks with Pruning (TAP), can be used to induce sophisticated models like GPT-4 and Llama-2 to produce hundreds of toxic, harmful, and otherwise unsafe responses to a user query (e.g. “how to build a bomb”) in mere minutes.
Summary Findings From Our Research Include:
- Small unaligned LLMs can be used to jailbreak even the latest aligned LLMs
- Jailbreak has a low cost
- More capable LLMs are easier to break
We published our research in a paper released today. Our findings suggest that this vulnerability is universal across LLM technology. While we do not see any obvious patches to fundamentally fix this vulnerability in LLMs, our research can help developers readily generate adversarial prompts that can contribute to their understanding of model alignment and security. Read on for more information and contact Cisco to learn about mitigating such risk for any model in real time.
How Does TAP Work
TAP enhances AI cyber attacks by employing an advanced language model that continuously refines harmful instructions, making the attacks more effective over time, ultimately leading to a successful breach. The process involves iterative refinement of an initial prompt: in each round, the system suggests improvements to the initial attack using an attacker LLM. The model uses feedback from previous rounds to create an updated attack query. Each refined approach undergoes a series of checks to ensure it aligns with the attacker’s objectives, followed by evaluation against the target system. If the attack is successful, the process concludes. If not, it iterates through the generated strategies until a successful breach is achieved.


The generation of multiple-candidate prompts at each step creates a search tree that we traverse. A tree-like search adds breadth and flexibility and allows the model to explore different jailbreaking approaches efficiently. To prevent unfruitful attack paths, we introduce a pruning mechanism that terminates off-topic subtrees and prevents the tree from getting too large.
Query Efficiency
Since it is important in cybersecurity to keep an attack as low-profile as possible to decrease the chances of detection, our attack optimizes for stealthiness. One of the ways that an attack can be detected is by monitoring internet traffic to a resource for multiple successive requests. Therefore, minimizing the number of queries that the target model (like GPT-4 or Llama-2) is called is a useful proxy for stealthiness. TAP pushes the state of the art as compared to previous work by decreasing the average number of queries per jailbreak attempt by 30% from about 38 queries to about 29 queries, which allows for more inconspicuous attacks on LLM applications.
How Do We Know if a Candidate Jailbreak Is Successful?
Most previous work aims to induce the model to start off with an affirmative sentence, such as “Sure! Here is how you can build a bomb:”. This method is easy to implement, but severely limits the number of jailbreaks that can be discovered for a given model. In our work, we opt to use an expert large language model (such as GPT-4) to act as the judge. The LLM judge assesses the candidate jailbreak and the response from the target model, assigning a score on a scale of 1 to 10. A score of 1 indicates no jailbreak, while a score of 10 signifies a jailbreak.
General Guidelines for Securing LLMs
LLMs have the potential to be transformational in business. Appropriate safeguards to secure models and AI-powered applications can accelerate responsible adoption and reduce risk to companies and users alike. As a significant advancement in the field, TAP not only exposes vulnerabilities but also emphasizes the ongoing need to improve security measures.
It’s important for enterprises to adopt a model-agnostic approach that can validate inputs and outputs in real time, informed by the latest adversarial machine learning techniques.
To learn more about threats to AI and how Cisco AI Defense helps mitigate them, visit the product page. Or, contact us to schedule a demo and learn more about Cisco AI Runtime.
We’d love to hear what you think. Ask a Question, Comment Below, and Stay Connected with Cisco Secure on social!
Cisco Security Social Handles




