
In a recent blog, Al Huger spoke about Cisco’s vision of Extended Detection and Response (XDR); specifically covering the breadth of definitions in the industry and clarifying Cisco’s definition of XDR:
“A unified security incident detection and response platform that automatically collects and correlates data from multiple proprietary security components.”
He also detailed the way Cisco’s approach to XDR is founded upon our cloud-native platform SecureX. In this blog series I’m going to expand on that XDR definition and explore how extended detection and other XDR outcomes can be achieved today leveraging the SecureX platform and integrated products.
The phrase “Extended Detection” conjures up an image of multiple data elements, perhaps many of them otherwise considered low fidelity signals, all merged into a single, high-fidelity alert. This extended detection is so wonderful that an analyst can immediately access the business relevance, the risk, the root cause and the appropriate response actions; perhaps this alert is so explainable that all this can be done automatically at machine-scale. Before we get to this state of nirvana, let’s take a step back and look at the phrase “Extended Detection” and that end state. It all begins with a detection.
But is it important?
That question – “but is it important” – stems from a more fundamental one: what does this alert mean to me? In our security operations centres today, we can have a number of products that generate detections, observations, sightings, etc. that feed into our operational processes. On their own these alerts indicate something potentially of interest in the space of that security tool. For example, an Endpoint Detection and Response product such as Cisco Secure Endpoint makes the observation of a malicious file seen on a host or a Network Detection and Response product such as Cisco Secure Network Analytics makes an observation of a host downloading a suspiciously high amount of data. These alerts tell us that something happened but not what it means in the context of the environment that it fired —your environment — creating that original question: “but is it important?”
In my experience “importance” is in the eye of the beholder. What can be considered a false positive in one environment is that high-fidelity, actionable pure-gold event in another: with the only difference being the environment the alert fired in. If we revisit the notion of the OODA (Observe, Orient, Decide, Act) loop for a moment, this is the second step of Orientation, bringing into account the environment variables that when held against the initial observation accelerate the decision and action phases.
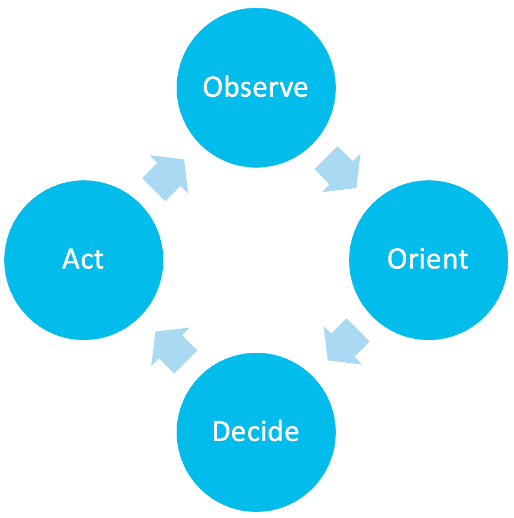
In the Orient stage we are bringing domain variables, such as the user, device, application, severity, etc., together to answer the question “but is it important?” and the essence behind what we are doing is extension: extending the observation, or that initial detection into something more. This is the empirical prioritisation of incidents that matter.
This elevation of an observation or a detection to an incident of importance is a central concept in Extended Detection and Response. The outcome that we are after is the creation of a highly actionable incident, one that is enriched with data and context about the nouns and verbs involved so that we can make an informed decision about the incident and, in an ideal world, playbook a response such that when similar incidents, with similar nouns and verbs appear, automatically trigger the correct response actions.
One of the trickiest parts of this conversation is what those variables – those nouns and verbs – are and what are the ones that matter to an organization. Some customers I’ve worked with treat endpoint events as the highest severity and highest risk, others choose MITRE Tactics, Techniques and Procedures (TTPs) as their primary objects of interest and others might prioritise around users, devices, applications and roles in an organization. This great degree of variability indicates that there must be flexibility in the methodology of incident creation, promotion and decoration.
Risk-Based Extended Detection with SecureX
Our objective is to enable a risk-based approach to incident management. This allows a user of Cisco’s security detection and response products to prioritise detections into incidents based on their own concept of risk – which as discussed, could vary organization by organization.
In Cisco SecureX we have an artifact called an Incident. The SecureX Incident is a combination of events, alerts, and intelligence concerning a possible security compromise, which drives an incident response process that includes confirmation, triage, investigation and remediation. This concept of an Incident, in combination with configuration settings in the integrated products and the investigation features of Cisco SecureX Response will be used as the basis for our Extended Detection and enrichment in this blog series.
Today, an Incident can be created manually through an investigation or threat hunting exercise, or promoted automatically, based on configuration, from some integrated products. As a construct the Incident is built on the Cisco Threat Intelligence Module (CTIM) and has several core tenants that allow for enrichment with different variables associated with the Incident.
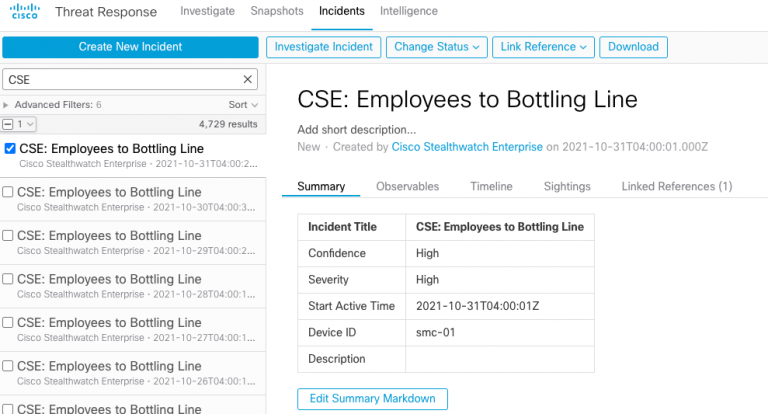
In the below figure for example we have an Incident that was automatically created through promotion from Cisco Secure Network Analytics. In the image below, we see a Custom Security Event “Employees to Bottling Line” with a high severity level (how the severity level was derived will be the topic of a future blog in this series).
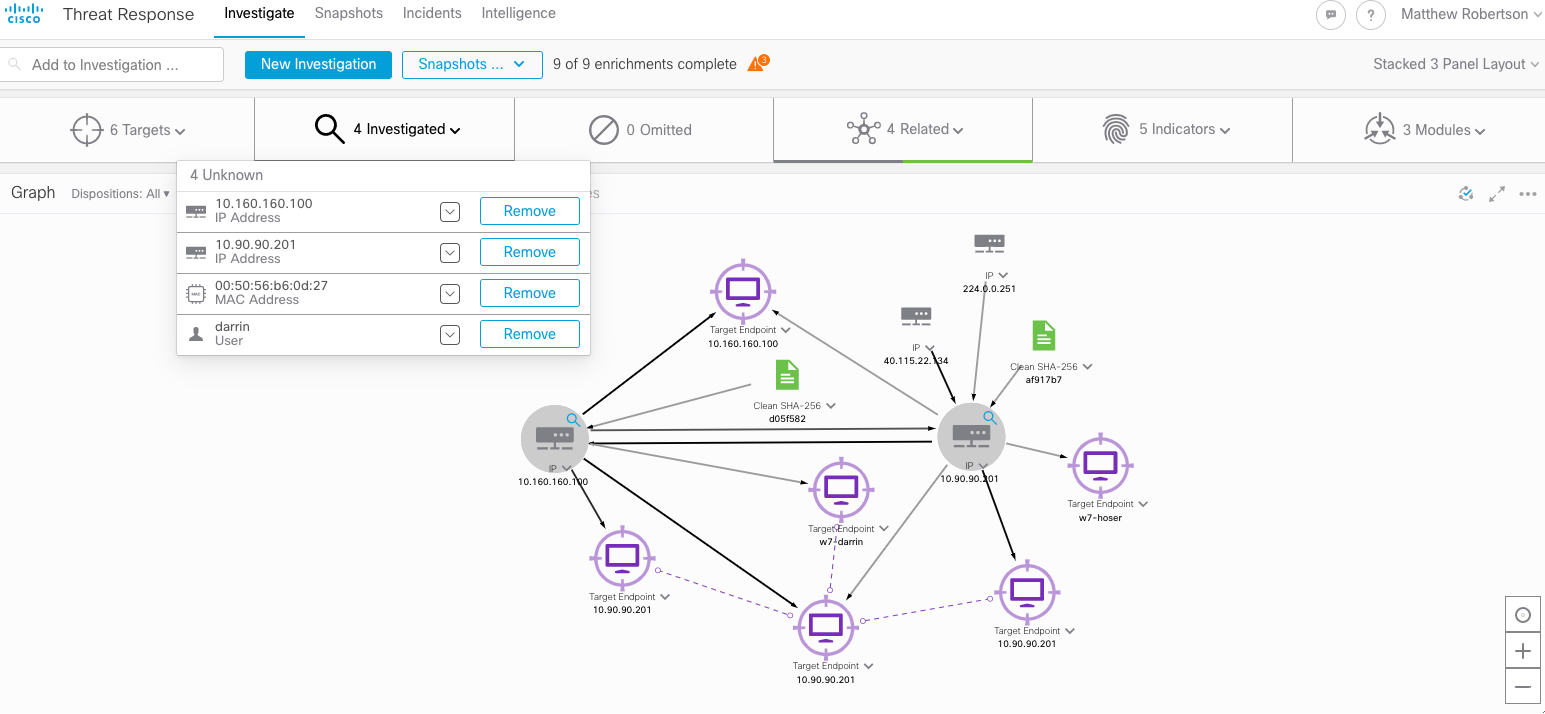
Clicking “Investigate Incident” will launch an investigation in Cisco SecureX Threat Response , automatically enriching the Observables in the Incident (in this case consisting of two IP Addresses, a MAC Address and a username) resulting in the below enrichment. This simple investigation enriched (or extended) the incident with data associated from those observables across nine different integrated products, resulting in the below diagram.
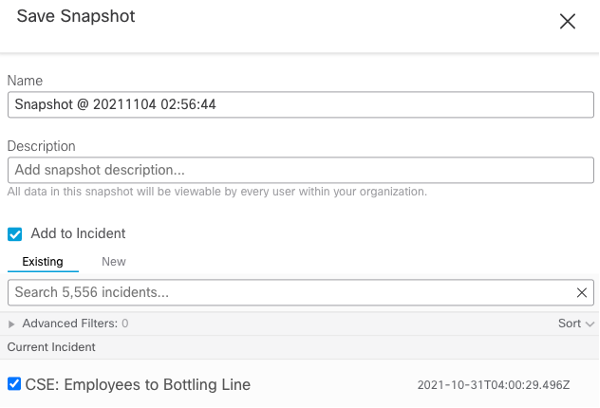
At this point we can investigate further, determining the impact or relevancy of the sightings. But first we are going to take a Snapshot and add it to the current incident, saving the enrichment.
While this very simple process took an alert from one product, manufactured an Incident and extended it with data from another product, we haven’t yet dug into some of the fundamentals that we want to explore in this series: namely, how we can triage, prioritise and respond to detections based on risk-driven metrics and variables that matter to our organization. Future posts in this series will explore the different integrated products in SecureX and how their detections can be promoted, enriched and extended in SecureX. In the next post in this series, we will begin with the automatic promotion and triaging of endpoint events into Cisco SecureX.
Interested in seeing the Incident Manager in action? Activate your SecureX account now.
We’d love to hear what you think. Ask a Question, Comment Below, and Stay Connected with Cisco Secure on social!
Cisco Secure Social Channels
Instagram
Facebook
Twitter
LinkedIn





