
Networks rarely fail all at once.
More often, they drift.
It could look like this: a configuration tweak during an outage, a dashboard setting flipped during troubleshooting, or a change that seemed temporary but never got rolled back. Little by little, the running network moves away from what the source of truth says it should be.
This is known as configuration drift, and it’s behind a surprising number of network issues. But it doesn’t have to be.
Introducing the network agent. Instead of waiting for engineers to discover drift after something breaks, agents can continuously watch the network, investigate configuration changes, and act when something doesn’t match intent. In other words, stop chasing drift and let the agent fix it.
Why AI agents are good at this
AI is great at cross-examining information. When we give agents access to multiple data sources and the right context, they can compare systems, investigate changes, and reason about what’s happening. By exposing those systems through MCP servers, we can give agents controlled access to the tools and data they need.
Goodbye to writing complex automation logic that stitches APIs together. Hello to building agentic workflows where AI investigates events across systems and decides what action makes sense. Meanwhile, engineers remain firmly in the loop, managing the system.
To make this agentic workflow, we need the right players. Three systems provide the context the agent needs:
- NetBox – the network source of truth
- Cisco Meraki – the network controller
- Cisco Splunk – the log and audit trail source
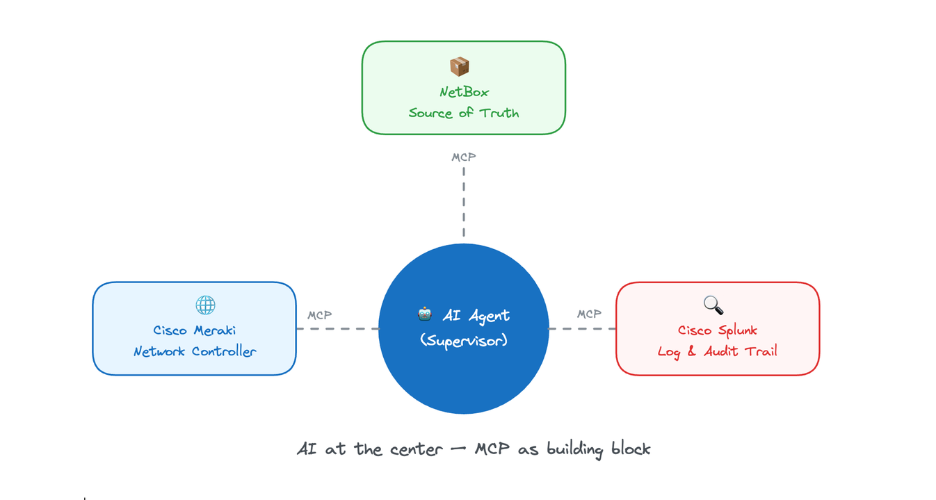
Together, these systems—powered by AI at their core and connected through MCP—form a powerful team for building self-healing networks that stop the drift.
To make it happen, I’ve used n8n as the orchestration platform with the configuration drift prevention system Drift Guard.
Inside the drift detection workflow
The entire Drift Guard system is built in n8n as a no-code/low-code agentic workflow.
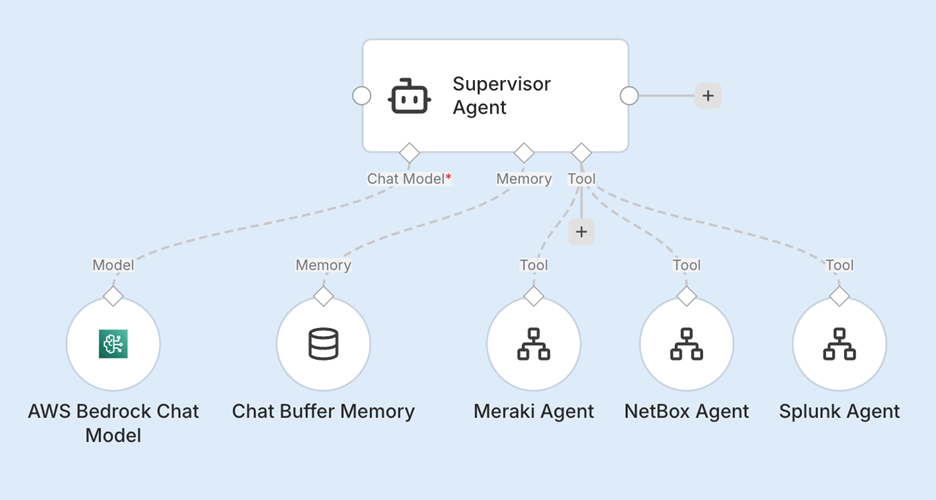
At the center of the workflow is a Supervisor Agent powered by AWS Bedrock using Claude Sonnet 4.6. Its job is to orchestrate the workflow, reason across the available tools, and decide what action to take.
The following three specialized sub-agents, each connected through its own MCP server, support it:
- NetBox Sub-Agent
- Cisco Meraki Sub-Agent
- Cisco Splunk Sub-Agent
The best part about building with MCP in n8n: Instead of creating one giant agent that tries to do everything, you can give the supervisor access to specialized agents with clear roles. With this architecture, the Supervisor Agent can autonomously prompt the sub-agents, orchestrating them for the information it needs to investigate an event. Each sub-agent provides context from its respective system, and the supervisor uses that information to determine which action to take. How cool is that?
The workflow triggers
DriftGuard can start in two ways.
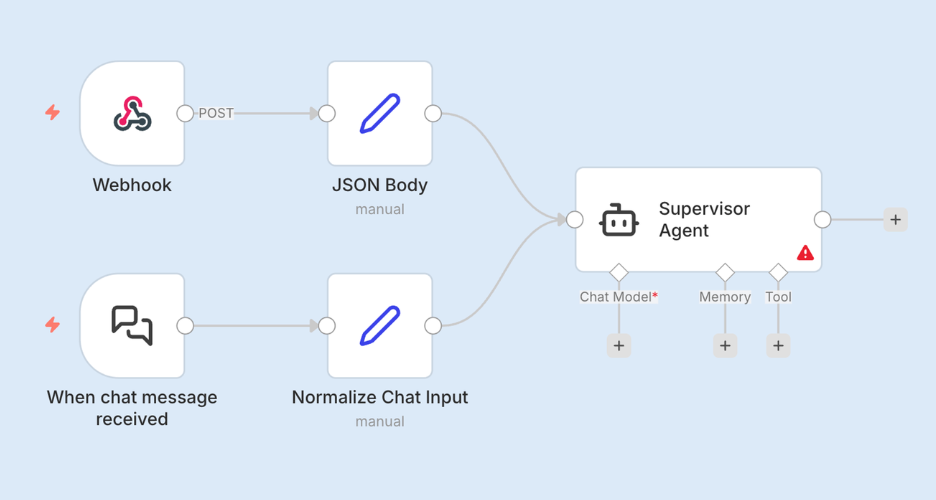
The first is a Webhook trigger. Whenever a configuration change occurs in the Cisco Meraki dashboard (drift), or in NetBox (no drift), a webhook fires and sends the event into the workflow. This allows the system to react to configuration changes in real time.
The second is a Chat trigger, which allows an operator to interact directly with the Supervisor Agent. Engineers can ask questions about devices, configurations, or recent changes, and the agent can gather information from the available systems to provide answers.
Both triggers feed into the same workflow.
Before reaching the Supervisor Agent, the inputs are normalized into a shared field. This ensures the agent receives a consistent request format regardless of whether the event came from a webhook or a chat interaction.
From the agent’s perspective, every request looks the same—which simplifies its reasoning about what to do next.
The brain of the system
The part that really makes Drift Guard work is the system prompt.
This is where the workflow gets its operating model. The prompt playbook tells the agent how to detect mode, which system to trust, how to investigate a change, and what to do next.
The following parts of the playbook do most of the heavy lifting:
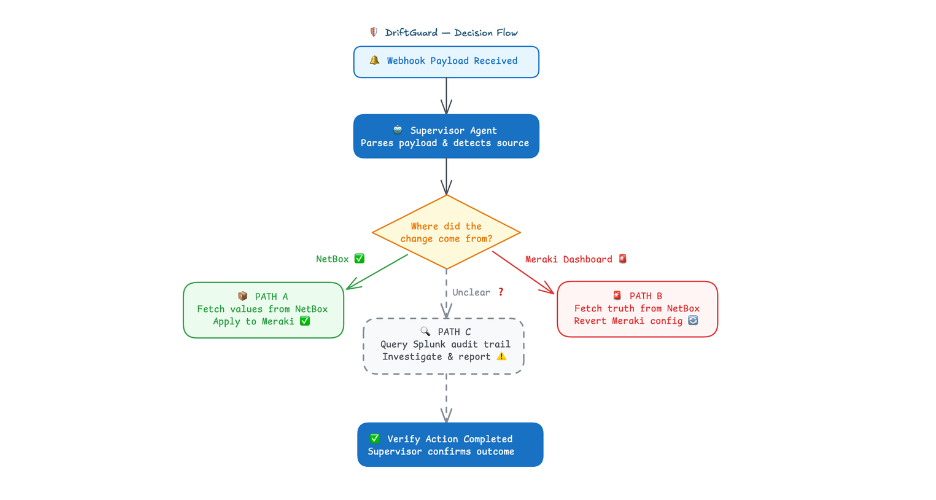
- Mode detection. The agent first determines how it should behave. If the input is a chat request, it acts as an operator assistant. If it’s a network event, it switches into Drift Guard mode and begins the remediation workflow.
- Source-of-truth enforcement. The prompt also makes one rule crystal clear: NetBox is the only source of truth. The agent is explicitly instructed not to trust the Cisco Meraki webhook payload as correct, because it may already reflect the drifted state.
- How to investigate a change and what to do next. And finally, the prompt gives the agent a simple decision path:
- If the change came from NetBox, apply it.
- If the change came from Cisco Meraki, revert it.
- If the context is unclear, investigate with Cisco Splunk.
The intelligence isn’t in the model. It’s in the playbook. For example, using playbook prompts the agent is explicitly instructed to never trust the Meraki webhook payload as correct, because that payload may already represent the drifted state.
Another plus of the system is that it uses shared memory. The workflow maintains memory across executions so the agent can retain investigation context. This allows follow-up interactions without repeating expensive lookups and helps keep token usage efficient.
Drift Guard in action
Okay, enough with the reading and architecture diagrams—let’s see it in action.
Watch for three things:
- An authorized change from NetBox
- A direct change in the Cisco Meraki dashboard
- Agent-to-agent communication
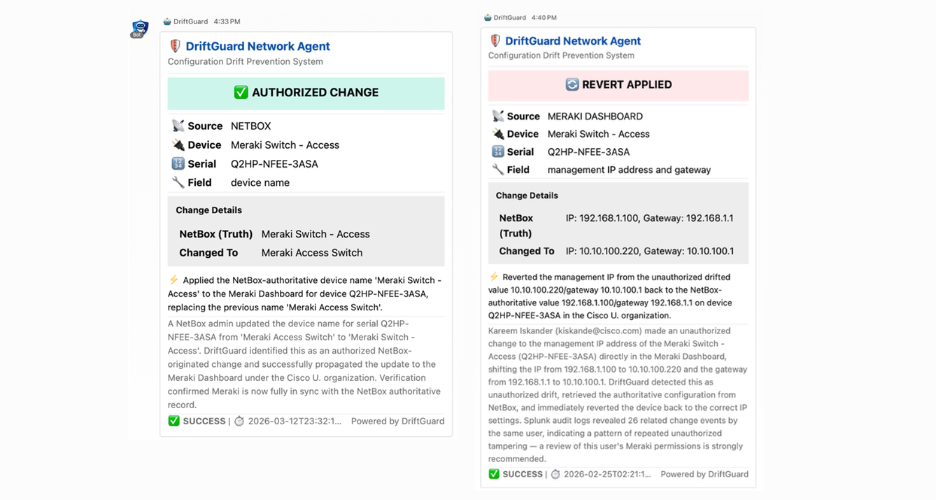
Changes from the source of truth (NetBox)
In this flow, the system recognizes it as expected and applies it to the network.

Configuration drift (Cisco Meraki)
Watch how the Supervisor Agent changes behavior when it detects configuration drift and moves to correct it.

Incident reports in Webex
Using incident reports in Webex, notice how the agents exchange context to investigate what happened.
Building a new solution to an old problem
Configuration drift isn’t a new problem. Every network engineer has dealt with it at some point. What is new is the ability to build systems that can detect, investigate, and correct drift automatically.
By combining AI agents, MCP-connected tools, and no-code/low-code orchestration with n8n, we can start building self-healing network workflows that help keep infrastructure aligned with the intended state—while engineers remain firmly in control.
The skills needed are becoming part of the modern network engineer’s toolkit:
- Network automation fundamentals, such as APIs, workflows, and event-driven automation
- Working with source-of-truth systems like NetBox
- Understanding how AI agents interact with tools through MCP
- Designing workflows that correlate multiple data sources like network state, logs, and configuration intent
Resources to build it yourself
If you’d like to explore this yourself, everything I showed in this post is available on GitHub, including the full n8n workflow, the agent prompts, and step-by-step instructions for setting it up in your own environment.
Because the best way to understand agentic systems…is to build one.






