
It’s been a long time coming, it’s true. It was long the #1 request I have gotten when it comes to Cisco’s deployment for Fibre Channel over Ethernet (FCoE): when is UCS going to have “FCoE Northbound?”
Now, at long last, I can confirm that the answer is right now.
I saw the announcement over the weekend, and before I had a chance to even sneeze out a tweet of my own, I was beat to the punch by a few other intrepid UCS fiends. The reaction was one of unadulterated joy and pure, rapturous bliss.
Or something close to that.
In all seriousness, from a storage perspective the one thing that has driven people crazy is the fact that the UCS Fabric Interconnects (FIs) could not continue with convergence upstream. It’s been the #1 question I’ve gotten as a storage Product Manager, and while I’ve long said that FCoE is not the panacea for the Data Center, I believe this goes a long way in making converged network even more realistic in today’s environments.
When Last We Left Our Hero…
I confess, I’m not a UCS guru. I know the UCS system and understand at a very high, broad level, grasping what makes it an architecturally superior technology – but I really haven’t had the chance to get to know it very well.
However, I do know that the people who have UCS, those who “get it,” also get something near and dear to my heart: convergence.
For years the UCS has been stellar at convergence. Not just networking, but memory, CPU, power – all these resources have been successfully abstracted so that they could be applied to applications, data, and traffic in a far more efficient way.
The downside has been – until now – that the convergence ended when the UCS system did: at the Fabric Interconnect. This meant that while UCS itself supported convergence, it was designed to fit into a more traditional networking infrastructure; a separate Ethernet LAN network and Fibre Channel SAN network.
In retrospect, it could be argued that this made sense. After all, UCS was entering a world of data centers where convergence of the networks didn’t exist. It was preparing for the easiest and most useful means to slip inside a data center.
(After all, can you imagine what might have happened if it was the other way around, that it was only converged networking that it could connect to?)
As customers and administrators have become more comfortable and confident with the idea of end-to-end convergence and Multihop FCoE, though, the voices for the UCS to evolve along with rest of the infrastructure have been getting louder and louder.
Multihop FCoE in Under an Hour
Thing is, the UCS 2.1 release didn’t just introduce Multihop FCoE into the Fabric Interconnects, it also provides a great deal of choice and flexibility for how to deploy it.
Last week I had a chance to get my hands on a UCS environment and deploy Multihop FCoE using upstream Nexus 5548s. This is where I may embarrass myself by admitting that – until last week – I had never actually had a hands-on experience with the UCS Manager (UCSM). After all, I work with SANs and switches, not blade servers, and my role as a Product Manager doesn’t give me a lot of actual hands-on time with the equipment.
So, the lab environment looked like this:

- Multihop FCoE Lab Environment
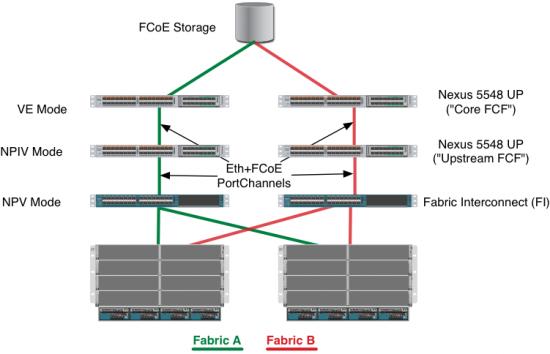
Some key things to note:
- Port Channels are supported and configured, though they are not explicitly called out in the diagram
- Ethernet and FCoE share links between the fabric interconnects and the Nexus 5548s (note: this is not possible on the Nexus 7000 at the time of this writing)
- You can not portchannel shared links with any sort of vPC
It’s important to note that I had never used UCS Manager or VMware’s vSphere 5.0 before.
Let me reiterate: I have never used UCSM or vSphere 5.0 in my life before this lab.
 Even so, I managed to configure the “upstream” Nexus 5548s (both of them), the “downstream” UCS Fabric Interconnects (both of them), the vHBAs (for both Fabric A and B) in vSphere – from scratch – in under an hour. (I didn’t have access to the core switches because they were being shared by all the participants in the lab).
Even so, I managed to configure the “upstream” Nexus 5548s (both of them), the “downstream” UCS Fabric Interconnects (both of them), the vHBAs (for both Fabric A and B) in vSphere – from scratch – in under an hour. (I didn’t have access to the core switches because they were being shared by all the participants in the lab).
Now, I’m obviously not going to pretend that this is 100% intuitive, of course. After all, this was a lab environment and the directions were laid out in front of me and, effectively, I was following a roadmap. And an excellently-written one at that.
But I would imagine that someone with UCSM or vSphere experience would have been able to fly through this in a much faster way than I did, even without step-by-step instructions. I found that much of my time was spent trying to familiarize myself with the UI for both systems, looking for the right tabs, reading the information on each section, etc.
The trade off here obviously is my novice experience with the systems versus the straightforward pre-written procedure.
Even so, I still made some errors because of my unfamiliarity with the GUI that forced me to go back and troubleshoot. For instance, at one point when I was attempting to map and zone the storage, I accidentally forgot to change a single drop-down box to the correct fabric, and accidentally overwrote my earlier mapping settings. Ooops. That took a couple of minutes to figure out and correct.
Even so, despite the errors, I was incredibly stoked that I was able to do all that configuration and get things working from scratch in under an hour.
Some Observations
The lab used a mix of CLI (for the Nexus 5548UPs) and GUI (for the UCSM and vSphere 5) environments. Generally speaking, I’m much more familiar with NX-OS than I was with the GUI, and yet even then I missed a couple of things that, quite frankly, I should have known better.
So, in the spirit of helping others who may be wishing to go forth (young man, go forth!), here are some observations when configuring multihop FCoE and UCS. Some of these may be obvious, others maybe not.
 1. Have a good understanding of “where you are.” This is a good general rule to follow when configuring equipment anyway, but because NX-OS is ubiquitous across Nexus platforms, it’s easy to forget whether you’re working on a “Fabric A” switch or a “Fabric B” switch, or if you’re working on a NPIV “upstream switch” or a VE “core switch.” My suggestion, if your terminal program allows you to change colors of the background, I usually create a light and dark color for Fabric A switches (e.g., light green for downstream switches and dark green for VE Fabric A switches) and a light and dark color scheme for Fabric B (e.g., Blue). It gives a quick visual representation of which switch I’m working on (dark for “VE”, etc.) and which fabric (green vs. blue).
1. Have a good understanding of “where you are.” This is a good general rule to follow when configuring equipment anyway, but because NX-OS is ubiquitous across Nexus platforms, it’s easy to forget whether you’re working on a “Fabric A” switch or a “Fabric B” switch, or if you’re working on a NPIV “upstream switch” or a VE “core switch.” My suggestion, if your terminal program allows you to change colors of the background, I usually create a light and dark color for Fabric A switches (e.g., light green for downstream switches and dark green for VE Fabric A switches) and a light and dark color scheme for Fabric B (e.g., Blue). It gives a quick visual representation of which switch I’m working on (dark for “VE”, etc.) and which fabric (green vs. blue).
2. Don’t forget that when you allocate the interfaces to the VSANs that they need to be in switchport mode trunk otherwise you’ll not get both the FIP VLAN and FCoE VLAN to run across the same link.
3. With the Nexus 5k systems, you can PortChannel FCoE and Ethernet links together, or you can use vPCs. You cannot do both. If you want need to use vPCs on your Ethernet links, you will need to use separate links for FCoE (but you can port-channel those together, if you wish). Using UCS with a Nexus 7k you will need to use dedicated FCoE links between the Fabric Interconnects and the 7k.
4. The UCS can be placed in either “switch mode” or “end-host mode (EHM)” (a.k.a “NPV” mode). In the former configuration, the UCS Fabric Interconnects have a full FC domain, complete with zoning and its own Domain ID. In this mode you will not need to configure an “upstream” NPIV switch, as you’ll be connecting via VE_Ports. In EHM, the UCS FIs will obtain the Domain and fabric login information from the upstream NPIV switch, and inherit all zoning information from there.

5. Okay, I gotta say it. The UCS Manager is wicked cool. I love the way that there’s more way to skin a cat. Forget to configure the VSAN before you create the vHBA? No problem! There’s a link next to the vHBA button to take you to that part of the configuration tool and brings you straight back when you’re done. No need to back all the way out and start over. I was really impressed with how well-thought out this was.
Bottom Line
We’ve had the ability to do end-to-end FCoE for quite a while now (almost 2 years, in fact). But the configuration options have always been a somewhat rigid. There is still some way to go but as we move forward with converged network capabilities the UCS B-Series “FCoE Northbound” capability is a huge milestone.
You can find out more information about UCS 2.1 and all the other additions and enhancements by looking through the release notes or the data sheet.
NB: I’d like to make a special shout-out to Marc Rossen, who developed the lab, and Craig Ashapa, the storage Technical Marketing Engineer for UCS. Craig, in particular, has simplified a lot of the multitudes of configuration options and the Cisco community owes him a great deal for his work in breaking it down into plain English.






Very useful and informative article. I’m yet to get my hands on any native FCoE storage a sadly!
This is great news as I have a UCS 6100 in place now. I’m looking to integrate a FCoE SAN into the environment so this is very helpful.
Did Cisco change its definition of multi-hop ? as i recall the Cisco definition of a hop in FC was an ISL or E_Port to E_Port connection and their definition of a hop in FCoE was a virtual ISL or a VE_Port to VE_Port connection.
(put to side for a minute that a 2 fc switch or 2 fcf/fcoe-switch san would only be a single hop).
in this diagram and blog i only see reference to FCoE to FCoE N_Port-Virtualizer mode for the UCS switch and not the UCS switch acting as an FCF with a VE Port to the next hop FCF – or did i miss something ???
now, personally i agree that ALL hops matter equally whether FSB, NPV, or FCF.
No, the definition still stays the same. You raise an excellent point. This specific example is, in reality, a single-hop deployment as the FI is put into NPV mode and the upstream NPIV switch is the one connected via E-port to the core switch. That is, the Domain ID encompasses the FI, and there is only one ISL in this topology.
However, the option also exists to have the FI in FC-SW mode, connecting via VE_Port to the upstream switch, maintaining separate FCIDs and creating ISLs. From a configuration standpoint, it takes no more or less time to set up.
Thanks for the clarification both on capability and diagram. i miss read the picture because looking at the left i saw (bottom to top) ‘ve mode’ ‘npiv mode’ and ‘npv mode’. however i now see on the right the labelling of ‘fi’ ‘upstream fcf’ and ‘core fcf’.
just to nit pick, i think you intend to say ‘fcf with npiv enabled’ rather than ‘npiv switch’.