
Posting this blog on behalf of Mark Nowell, Distinguished Engineer, INSBU.
The rapid growth of cloud data center in terms of storage and networking is something Cisco has been tracking through the Cisco Global Cloud Index for several years now. Our latest forecast shows that we’re on track to meet and likely exceed the 14 zettabyte target for global cloud IP traffic by 2020. That’s astounding considering that the world was marveling at reaching the one zettabyte milestone just a couple years ago.
As a result, the networking and interconnect industries are pushing their technology development teams hard to meet the unabated and ever higher bandwidth connectivity demands. The next major transition will be the general availability of 400 Gigabit Ethernet technology, which is soon to be undergoing trials at various cloud providers, telcos, and other environments that require ultra-high bandwidth connectivity.
While there is no dispute that the 400 GbE will be mainstream soon enough, there are still active debates as to which pluggable form factor that this technology is best delivered. We can all acknowledge that cost is a main concern for any technology transition. Thus, driving the optics volume up to drive the cost down is imperative for smooth transition.
With the current trends, optics cost is becoming a barrier to transition: the reduction of ASIC cost-per-bit is outpacing that of optics. In this blog we will make the case for using QSFP-DD (Quad Small Form Factor – Double Density) modules as the ideal connectivity option for all next-generation cloud and other hyperscale data centers.
The Criticality of Cost Containment
It almost goes without saying that there are significant costs associated with developing any new technology with new optical form factors being no exception. Each change in form factor delays the volume ramp and can accelerate associated costs. These are significant barriers to smooth seamless transition from one technology to another.
Ideally, the “final”, high volume, form factor for a new speed should be the same as for the previous version (aka backwards compatibility) as detours through transitional form factors will reduce market traction and drive cost up. Backwards compatibility ensures that users have access to technologies that are already optimized for the systems it is being designed in to.
Network and system requirements, such as density, drive optical module requirements and optical component integration capabilities drives optical module feasibility. In the past, this has led to initial larger form factors transitioning to form factors that get smaller, denser, and lower cost as the technology moves towards higher and higher adoption. We’ve seen this cycle before.
For example, 10 GbE optical modules moved from the bulky 300 pin module, to XENPAK, to X2, to XFP and finally to SFP+. Similarly, 100 GbE modules transitioned from the initial CFP form factor, to CPAK or CFP2, to CFP4 and finally to QSFP28. In case of Fibre Channel, there was no deviation from SFP throughout the speed increases from 1G to 2G to 4G to 8G to 16G to 32G since the use cases did not change.
With Ethernet, we’ve seen these transitional form factors occur as the dominant use case changed over time: initially longer reach, lower density before moving to shorter reach, higher density, higher volume. The longer reach technologies always miniaturized in time to fit into the higher volume form factor providing a complete solution. In either case, the lowest cost points and most frictionless development paths always won. There are reasons for the industry to repeatedly converge with the same form factor.
There is also a general preference to stick with same switch port density per rack unit to maintain proven fabric designs as networking equipment is architected around them to achieve certain densities. Maintaining this consistency limits the impact on the ecosystem. Significant experience and reuse benefits system and module suppliers to help minimize costs and accelerate development. And finally the use-case advantage of using the same form factor is significant as it enables multi-speed port options on switches – slower optics in higher speed ports are often required for migrating to higher port speeds seamlessly.
The Transition from 100 GbE to 400 GbE (QSFP28 to QSFP-DD)
The market urgency to achieve 400 GbE general availability is largely due to the shifting market dynamics. With the introduction of 10 GbE, early adopters deployed well ahead of the high-volume data center deployments. At 100 GbE, again early Service Provider adopters deployed ahead of high volume data center markets, though market demands required the development cycle to be slashed in half.
With 400 GbE, we’re seeing the key customer environments – cloud providers, telcos, hyperscale data center – wanting to adopt the technology almost simultaneously as the number of bandwidth-hungry apps and workloads explode. With lower distance/ higher volume use cases (<2km distance) needed day one – the industry can’t afford to detour through transitional form factors as illustrated in this chart:
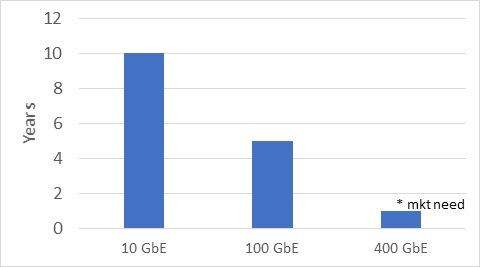
Time to High Volume form factor for initial form factor
This requires vendors to find the optimal solution to meet all those needs, we do not have the luxury to work through multiple form factor iterations to get to the lowest cost points that appeal to customers. The QSFP-DD form factor is being adopted by the industry as the initial and the high-volume final form factor for 400 GbE. It has been shown to be able to achieve the multiple goals of technical feasibility, backwards compatibility and breadth of reach support.
The higher volume shorter reach optics are all in development for various reaches and fiber types including active optical cables, parallel multimode fiber and both parallel and duplex single-mode fiber within QSFP-DD.
Some first generation QSFP-DD modules are expected to dissipate powers of up to 15W, while most will be below that. Cooling of modules is a system design issue and this is where the power of industry experience comes to the fore. With advanced thermal designs in systems and cages, we are seeing no issues with cooling even these higher power modules.
The longer reach use case (400GbE DWDM for Data Center Interconnect) is also technically feasible in the same QSFP-DD form factor – a transition of technologies means that the industry no longer needs to wait for integration to catch up. With the adoption of coherent technology much of the complexity shifts into silicon integration and away from optical integration. CMOS integration enables QSFP-DD to be built for these “complicated optics” which are already in design. To support that, the Optical Internetworking Forum is working to define a pluggable 400 GbE solution for Data Center Interconnect called 400GZR (~120km DWDM) for QSFP-DD form factor.
For network deployments, over-subscription ratios needs to stay the same as 25G/100G moves to 100G/400G; the same port density per RU is needed this can’t be given up. End-users, system designers, networking and ASIC developers all understand the importance of backward compatibility. Enabling products and networks that can accept lower speed pluggable modules into the same port has widespread benefit from network upgrade strategies, cost-reduction strategies, and development cost reduction strategies. Even though some networks deployment strategies may not have this as a requirement, they do still value the lower costs enabled from riding the aggregate volumes of the rest of the industry that do have these requirements.
QSFP-DD: Crossing the Chasm
QSFP-DD has been designed to meet all of the market needs and optimized system designs for 400 GbE in order to establish itself as the dominant and successful pluggable form factor. This starts with it being backwards compatibility with 100 GbE QSFP28 and even 40 GbE QSFP+.
The beauty of the QSFP form factor is that the industry has more than a decade of experience building solutions around this form factor. This enables rapid innovation and rapid maturity to happen. The three key challenges for any form factor are always: can the connector work at this higher speed? Can the system cool the module? And can the optics fit? In all cases, QSFP-DD successfully meets those challenges.
The networking industry needs to focus on maximizing volume and extending form factor life across multiple generations. The former lower costs which drives wider adoption, the latter lowers risk of adoption for everyone from end-users, to system designers, to module and component manufacturers. Given the anticipated overlapping market adoptions of 400 GbE, short-lived form factors hold no benefit, the focus must be on addressing all the market requirements in an optimal way as possible to allow all the markets to adopt and allow all the suppliers to benefit from economies of scale.
The “Double-Density” approach is now being further adopted to extend the other dominant form factor (SFP becoming SFP-DD) for future solutions so the industry and continue to leverage the backwards compatible solutions that have been the hallmark of success so far. This continues the roadmap of access (10GbE SFP, 25 GbE SFP, 50 GbE SFP, 100 GbE SFP-DD) and interconnects (40 GbE QSFP, 100 GbE QSFP, 200 GbE QSFP, 400 GbE QSFP-DD).
Summary
The industry is therefore well on its way to achieving the necessary steps for success at 400 GbE. The initially daunting task of building a solution that accelerated the transition to high-volume, low-cost solutions to meet the needs of all the markets expected to adopt 400 GbE around the same time is well on its way. Solutions are being built and tested in labs today and public demonstrations and deployments are soon to follow. Watch this space!
References:
QSFP-DD MSA (www.QSFP-DD.com)
SFP-DD MSA (www.SFP-DD.com)
Optical Internetworking Forum (http://www.oiforum.com/technical-work/current-oif-work/)




