
Cisco Intelligent Packet Flow marks a shift in data center networking, transforming the fabric from high-speed transport into an intelligent system built for AI and machine learning workloads. Beyond raw bandwidth, Cisco Silicon One transforms the network from a simple transport layer into an intelligent fabric by integrating telemetry, advanced load balancing, and congestion management directly into the silicon. This gives the network greater awareness of traffic behavior and path conditions, allowing it to respond more effectively to the bursty, latency-sensitive communication patterns common in modern AI environments.
Building upon this foundation, Cisco Intelligent Packet Flow now incorporates Intelligent Collective Networking from Cisco Silicon One G300 switching processor. As shown in Figure 1, this AI-first architecture delivers hardware-accelerated adaptive routing, fabric-level congestion awareness for collective operations at scale, proactive link-degradation detection before packet loss, advanced telemetry, and an Ultra Ethernet–ready foundation. With deep visibility and operational control available either through external analytics platforms using standards-based streaming telemetry infrastructure or through Cisco Nexus Dashboard with native Splunk, this evolution offers significant flexibility while bringing compute and networking closer together as a unified system of GPUs, switches, and data center fabric.
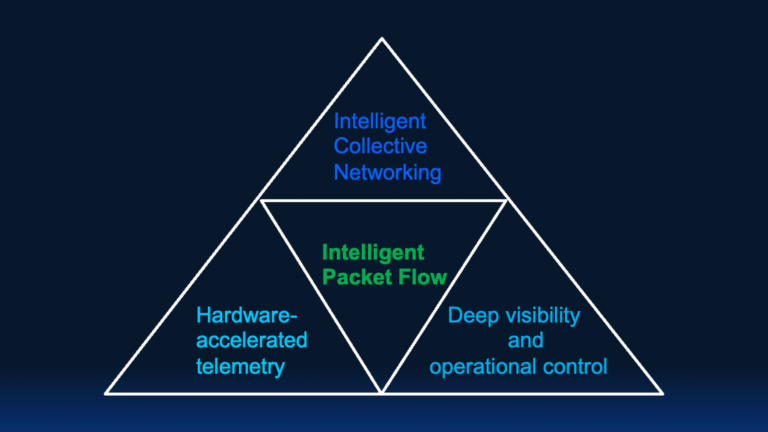
This holistic approach delivers end-to-end performance insights essential for managing the high-bandwidth, tightly synchronized, and latency-sensitive east-west traffic that defines modern AI infrastructure.
Enhanced features
In G300-based fabrics, the components of Cisco Intelligent Packet Flow work together as a closed-loop system: Proactive network telemetry detects congestion and link degradation, Intelligent Collective Networking uses that information to adaptively reroute traffic across the fabric, and a unified observability and orchestration platform turns those signals into actionable intelligence for assurance and operations.
| Key feature | Capabilities |
|---|---|
| Intelligent Collective Networking |
|
| Hardware-accelerated telemetry |
|
| Deep visibility and operational control |
|
Benchmarking with large-scale AI clusters
Cisco Intelligent Packet Flow evaluated using Collective Completion Time benchmarking demonstrates a significant leap in AI network efficiency by aligning fabric behavior with collective GPU operations:
- Across large-scale Clos deployments (8K–16K GPUs), it operates within 24% of ideal CCT, even under congestion and mixed traffic.
- Compared to traditional ECMP, G300 reduces CCT by up to 87%, translating up to 82% improvement in job completion time (JCT).
- It also outperforms advanced techniques like packet spraying by ~28%, while maintaining stable performance under failure scenarios.
- By minimizing tail latency and network-induced stalls, G300 maximizes GPU utilization and unlocks up to 28% additional cluster efficiency.
Cisco advantage: Cisco Silicon One G300-powered N9000 Series Switches
At the heart of our innovation is Cisco Silicon One. The Cisco Silicon One G300 leverages P4 programmability and Intelligent Collective Networking to provide a flexible, future-proof AI infrastructure. By enabling software-based updates and real-time traffic optimization, it significantly lowers TCO while ensuring seamless scalability for the future of agentic AI.
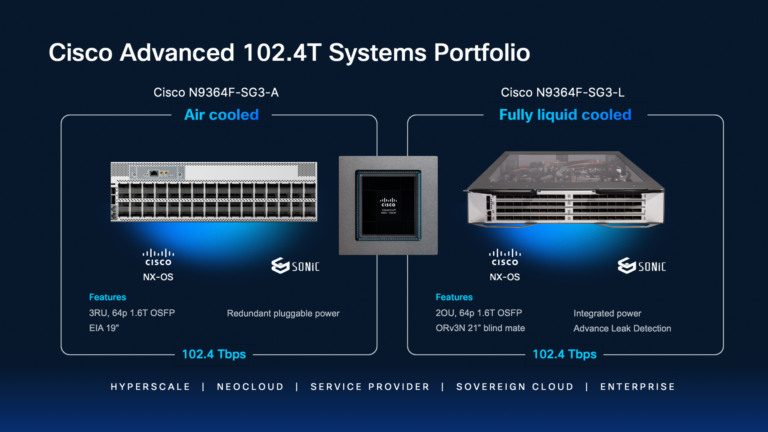
Cisco delivers Intelligent Packet Flow through the Cisco Silicon One G300-powered N9000 Series Switches. Designed for the demands of AI, the power-efficient 102.4-Tbps bandwidth portfolio offers flexible scale-out deployment options for both air-cooled and 100% liquid-cooled fabric architectures (see Figure 2). With support for both Cisco NX-OS and SONiC, and seamless integration with a unified operating model under Cisco Nexus One, organizations gain operational consistency at any scale.
“Our hyperscale and neocloud customers need networking that matches GPU density. Cisco N9000 with NX-OS delivers programmability and telemetry to optimize every flow. The G300 silicon enhances this with industry-leading buffers, power efficiency, and 1.6T port density. Through our strategic partnership with Cisco, we deliver lossless, high-performance networking for AI training and inference. The Nexus One platform ensures predictable performance—deep buffers manage bursty traffic, and Intelligent Packet Flow maximizes GPU utilization.”
—Thomas Berger, Director, Data Center Networking, Computacenter
Building the future of AI: Transforming your data center for AI workloads
Cisco Intelligent Packet Flow enables fabrics that can sense, adapt, and optimize in real time for the demands of large-scale AI workloads. The result is a more efficient, resilient, and intelligent infrastructure that improves collective performance, accelerates job completion, and helps unlock greater value from every GPU in the cluster. With the Cisco Silicon One G300-based N9000 Series Switches, Cisco brings this vision to market in a flexible, Ultra Ethernet–ready platform designed to unify networking and compute into a single high-performance AI system.
To experience the transformative power of Cisco Intelligent Packet Flow firsthand, request a demo or learn more by contacting your Cisco account representative.
Cisco Intelligent Packet Flow: Enhancing AI network performance
Additional resources:




