
At the recently concluded OpenStack summit in Austin, I was impressed by the amount of interest shown by attendees on containers. Almost all of the container related sessions were packed as customers are now realizing its advantages. By containerizing applications, you are able to virtualize the host operating system. What this means is that you now create isolated environments within the host OS for each container, such as the file system, network stack and process space that prevents containers from seeing each other. Besides, the containers are also light-weight and portable not only across the OS distributions but also across clouds. These features enable developers to quickly build, deploy, port and scale apps in a manner that was not possible before with apps running in a virtual machine environment.
At the summit, I had the opportunity to present to a fairly large group of audience on one of my passionate projects that immensely helped our team. A recording of my presentation can be found here- my session . The project was to stand up an automated deployment of Kubernetes in our OpenStack Kilo environment. In this blog post, I will describe our approach and also provide an overview of the code repo available on github for anyone to use. Hopefully, you could leverage some of these to build an automated deployment of your own Kubernetes cluster. Do keep in mind that the software has been tested in a development environment only and for any production deployment ensure that you conduct the necessary due diligence as always.
The first question to answer is the why and what of kubernetes and ansible. Kubernetes (k8s) is an API driven platform for orchestrating and managing docker containers. Besides basic orchestration, it also has control processes that continuously drive the state of the system towards the user specified desired state. When using this platform you have the ability to group your application containers together into a composite unit called pod. A pod is a grouping of containers that share networking and storage. When you create docker containers, by default, each container gets its own network namespace i.e. its own TCP/IP stack. Kubernetes combines the network space of all its pod containers by using the –net=”<container-name>|<container-id>” setting in docker. This setting enables one container to reuse another container’s network stack. K8s accomplishes this by creating a pod level holding container with its own network stack and all of the pod containers are configured to use reuse the holding container’s network space.
At the pod level, kubernetes provides a variety of services such as scheduling, replication, self-healing, monitoring, naming/discovery, identity, authorization etc. Kubernetes also has a pluggable model that enables developers to write their own modules and build services atop this platform. As of this writing, it is one of the most advanced open-source platforms available to orchestrate and manage docker containers.
We chose Ansible for automation as is one of the most popular, intuitive and easy to use automation platforms today. It is agent-less and uses ssh to login to systems in the infrastructure and enforces policies that you have described in a file called a playbook. The policies are modeled as a list of tasks in yaml format. In the world without automation, these could be thought of as the manual tasks that an IT admin would have to execute to deploy the infrastructure software.
This post describes how to setup a working kubernetes cluster on OpenStack virtual machines. A K8s cluster has a master node, which runs the API server and a set of worker nodes that run the pod containers. The setup uses Ansible (>2.0), Ubuntu and Neutron networking. It has been tested using the OpenStack kilo release. Ansible deploys the k8s software components, launches VMs, classifies VMs into master and worker nodes and deploys kubernetes manifests. We use neutron to provide networking to both the OpenStack VMs and k8s pod containers. All VMs in the test environment run the ubuntu 14.04 server OS.
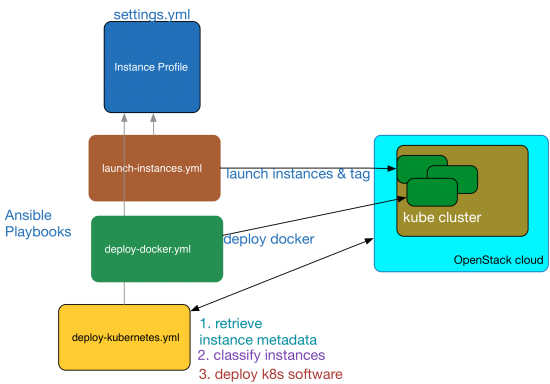
The below diagram shows the various software components in play and how they interact to automate the cluster. I will use this diagram as a reference to illustrate the automation process and it should all make sense as you read through this post.
Kubernetes Cluster Automation
Setup
This setup assumes that you have an OpenStack cloud running core services such as Nova, Neutron, Glance and Keystone. You will also need ansible version >2.x, on a machine that has the credentials and network connectivity to ssh into the compute nodes and VMs. This ansible node should also be able to access the OpenStack APIs. I have ansible installed on my macbook using the commands:
sudo easy_install pip
sudo pip install ansible
After you have installed ansible, verify its version using the command: “ansible –version”. It should output a 2.x. release.
Kubernetes Cluster Deployment
The automated cluster deployment is controlled by three ansible playbooks. You can pull the playbooks, templates and code from my repo here: cluster repo . The three playbooks are
- launch-instances.yml — launches kubernetes cluster instances
- deploy-docker.yml — deploys docker on all of the cluster instances
- deploy-kubernetes.yml — deploys kubernetes control and worker software components and brings up the cluster
All playbooks get their input variables from a file named settings.yml, which will be referred to as the settings file. The nodes dictionary in the settings file specifies the names of the nodes in the cluster along with their metadata a.k.a. tags, that are injected into the nodes at launch time. These tags are used by a cloud inventory script [ inventory.py ] to classify the nodes as master and worker during subsequent playbooks runs. For instance, the node whose tag ansible_host_groups equals k8s_master will be classified as the master node and the nodes whose tag value equals k8s_worker will be classified as workers. The settings file also contains a dictionary named os_cloud_profile, which provides ansible with the nova virtual machine launch settings. To launch the instances, run the playbook as below:
ansible-playbook -i hosts launch-instances.yml.
If everything goes well, you will see that all the nova instances are created without any errors in your OpenStack cloud. These instances will provide the underlying infrastructure to run the k8s cluster. After spawning the instances, you can run the remaining playbooks to deploy docker and kubernetes. During the playbook run, use the inventory script named ‘inventory.py’ to classify nodes so the control and worker components are deployed to the correct VMs.
Run the playbooks as shown below:
ansible-playbook -i scripts/inventory.py deploy-docker.yml
ansible-playbook -i scripts/inventory.py deploy-kubernetes.yml
The control plane for the k8s cluster which includes the API server, scheduler, etcd database and kube controller manager is deployed using a master manifest file. This file can be found in the templates folder and is named master-manifest.j2 . The version of the k8s control plane software is determined from the settings file. The playbook named deploy-kubernetes.yml first downloads and deploys the kubelet and kube-proxy binaries and starts these two services on all the nodes. Then the master-manifest template file is deployed to a config directory named /etc/kubernetes/manifests on the master node. This directory is watched by the kubelet daemon process and it starts all the docker containers that provide control plane services. When you use the docker ps command, you should see the kube-apiserver, kube-controller-manager, etcd and kube-scheduler processes running in their own containers in the master node.
The API server is configured to use HTTPS to serve the API. The certificates needed for SSL are generated by running the script make-ca-cert.sh as one of the playbook tasks. This script generates the below certificates in the certificate directory on each node. It is generated on each node because the docker daemon is also configured to use the same server certificate for TLS. The cert directory value is configurable in the settings file.
ca.pem – Self signed CA certificate
server.crt / server.key – Signed kube API server certificate and its key file. This cert is also used by the docker daemon process to secure client access.
cert.pem / key.pem – Signed client certificate and its key file. Used by both the kubectl and docker clients.
On the client machine, you can find these certs in the certs folder within the repo. Docker environment files are created in the client machine for each node using the convention <nodename>.env. You can source this environment variables and run the docker client against its docker host. For example to run docker commands on the master node named master1, first do a “source master1.env” and then run the commands. Also, for the kubectl client a config file is created with the necessary credentials and cluster master IP address. The config file could be found in $HOME/.kube/config. This will enable you to run the kubectl commands from your terminal window against the cluster.
Using OpenStack neutron for Kubernetes Networking
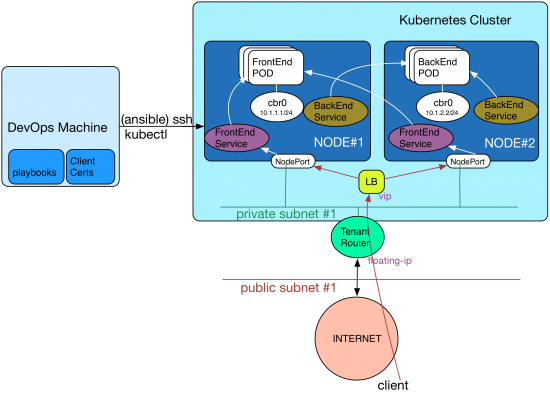
In this post, I will describe how to use the OpenStack neutron service for networking the k8s pods. This is similar to the setup used in GCE. There are other options such as flannel that uses UDP encapsulation to create an overlay network for routing pod traffic over existing tenant neutron networks. Using neutron for pod networking removes this overlay-over-overlay network architecture for containers.
It is important to note that in k8s each pod i.e. a group of containers, has an IP address. This is different from the networking model in docker in which each container has its own host private IP address. In order for k8s networking to work, the pod ip addresses must be made routable without NAT. This means two things:
a) When a pod container communicates with other containers in other pods, the traffic must be routed directly without NAT
b) When a pod container communicates with the IP address of the VM, the traffic must be routed directly without NAT
In order to accomplish this, as a first step, the default docker bridge named docker0 in each node is replaced with a linux bridge named cbr0. An IP block is allocated for pod networking across all nodes say a /16. This block is subnetted and a node-to-pod cidr mapping is created in the settings file. In the above digram, I have allocated 10.1.0.0/16 for pod networking and created a mapping as below:
node1 : 10.1.1.1/24
node2: 10.1.2.1/24
nodeN: 10.1.n.1/24
A script named create-bridge.sh [create-bridge.sh] creates cbr0 and configures it with the IP address of the pod subnet using the mapping defined in the settings file.
The second step is to configure the tenant router to route traffic to the pod subnet. For example in the above diagram, the tenant router must be configured to route the traffic to the pod subnet 10.1.1.0/24 to the node#1’s ethernet address on the private-subnet#1. Similarly a route must be added with a destination pointing to each node in the cluster on the tenant router to route traffic destined to the pod network. This is accomplished using the script add_neutron_routes.py .
The third step is to add an ip tables rule to masquerade traffic destined from the pod subnet to the Internet for outbound connectivity. This is because the neutron tenant router does not know that it needs to SNAT the traffic from the pod subnet.
The last step is to enable ip forwarding on the linux kernel of each node to route packets to the bridged container network. All of these tasks are performed by the playbook deploy-kubernetes.yml .
The end result of running this playbook is that neutron networking is now programmed to route traffic between the pods and to the Internet.
Note: By default, as an anti-spoofing security measure, neutron installs iptables firewall rules on the hypervisor to lock-down traffic originating from and destined to a virtual machine’s port. So when you route traffic destined to the pod network to the virtual machine’s port, it is filtered by the hypervisor firewall. Fortunately, there is a neutron extension named AllowedAddressPairs , which is available as of the Havana release that allows additional networks such as the pod subnets to pass though the hypervisor firewall.
Exposing Pod Services
For all practical purposes, each pod must be front-ended by a service abstraction. The service provides a stable IP address using which you can connect to the application running in a pod container. This is because the pods could be scheduled on any node and can get any IP address from the allocated node_pod_cidr range. Also, as you scale-out/scale-back these pods to accommodate varying traffic loads or even when failed pods are re-created by the platform, their IP addresses will change. The service abstraction ensures that the ip address of the pods remain fixed from the a client’s perspective. It is important to note that the CIDR for the service, also known as cluster_cidr, only lives locally in each node and does not need to be routed by the neutron tenant router. Traffic hitting this service IP is distributed by k8s to the backend pod using a proxy function (kube-proxy) implemented in each node typically using iptables.
This stable service ip can be exposed to the outside using the NodePort capability of kubernetes. What nodeport does is that it uses the IP addresses of the worker node and a high tcp port say 31000, to expose the service ip address and port to the external world. So if you allocate a floating-ip to the node, the application will serve traffic on that ip and its node-port. If you use a neutron load balancer, add the worker nodes as members and program the vip to distribute traffic to the nodePort. This approach is illustrated in the above diagram.
Service Discovery
Service discovery is fully automated using a DNS cluster add-on service. This is deployed using a skydns-manifest and skydns-service . Every service defined in the cluster is assigned a DNS name automatically by k8s. So an application running in a pod can lookup the cluster dns server to resolve the service name and location. The cluster DNS service supports both A and SRV record lookups.
Conclusion
In conclusion, I hope this blog post has shed some light on how to standup a Kubernetes cluster within OpenStack using Ansible. Feel free to send me your comments and suggestions. You can reach me at najoy@cisco.com.




Super! Nice article
What’s the advantage of ansible over other tools like chef?
With Chef you need an agent on each managed node. Also, you need to deploy a chef server. The primary advantage with Ansible is that the architecture is simpler.It is agentless and does not mandate the use of a server machine. You can run Ansible directly from your workstation.
Great read! Thanks for sharing!
This level of automation and delivery is what the future of the enterprise will be!
Awesome! Fantastic article
I love seeing this kind of automation. Nice work.
Really interesting. Thanks for sharing.
Nice!
Kubernetes is the future!