
The dominant safety benchmarks for frontier large language models (LLMs) share a structural assumption: that a single prompt and a single model response are enough to characterize how a model behaves under adversarial attack. These benchmarks inform model cards, safety reports, and procurement decisions across the industry, but they all only measure one narrow slice of attacker behavior.
In a paired-regime evaluation of 15 closed/proprietary flagship models from OpenAI, Anthropic, Google, Amazon, and xAI, we found that single-turn attack success rate (ASR) is not a reliable proxy for what happens when an attacker can adapt across turns. Multi-turn ASR ranged from 7.89% to 88.30% across the cohort (and single-turn ASR for the same models ranged from 2.19% to 64.91%). The two regimes do not produce the same model ordering, the same failure map, or the same tail-risk picture. And every model we tested exhibited non-trivial multi-turn ASR.
The full report (available here) extends our earlier assessment of eight open-weight LLMs, Death by a Thousand Prompts, where multi-turn attack success rates ran 2x to 10x higher than single-turn baselines. The pattern we documented in open models holds in closed ones, including alignment philosophy correlating with performance against adversarial prompts. In both studies, models with wider single-to-multi turn gaps tended to come from labs whose public communications emphasize capability advancement, while narrower gaps were more common among labs that emphasize safety publicly.
What We Measured
The evaluation is built on a fixed snapshot from our adversarial corpus: 30,090 single-turn prompts (2,006 per model) and 6,986 multi-turn attacks distributed across 1,456 conversations. The 15 models we assessed cover recent flagship models from OpenAI (GPT-5.2 and the GPT-5.4 family), Anthropic (Claude Opus 4.5 and 4.6, Sonnet 4.5 and 4.6, Haiku 4.5), Google (Gemini 3 Pro), Amazon (Nova Lite, Nova Micro, Nova 2 Lite), and xAI (Grok 4.1 Fast in both reasoning and non-reasoning (NR) configurations). Each was tested under the same harness, on the same prompt banks, with the Cisco Integrated AI Security and Safety Framework taxonomy applied for downstream decomposition. Figure 1 and Table 1 show our results.
Multi-turn evaluation matters for one reason: it is where attackers actually live. Real adversaries iterate. They reframe refusals, decompose tasks across turns, adopt personas, and escalate gradually. A single-turn benchmark cannot see any of that.
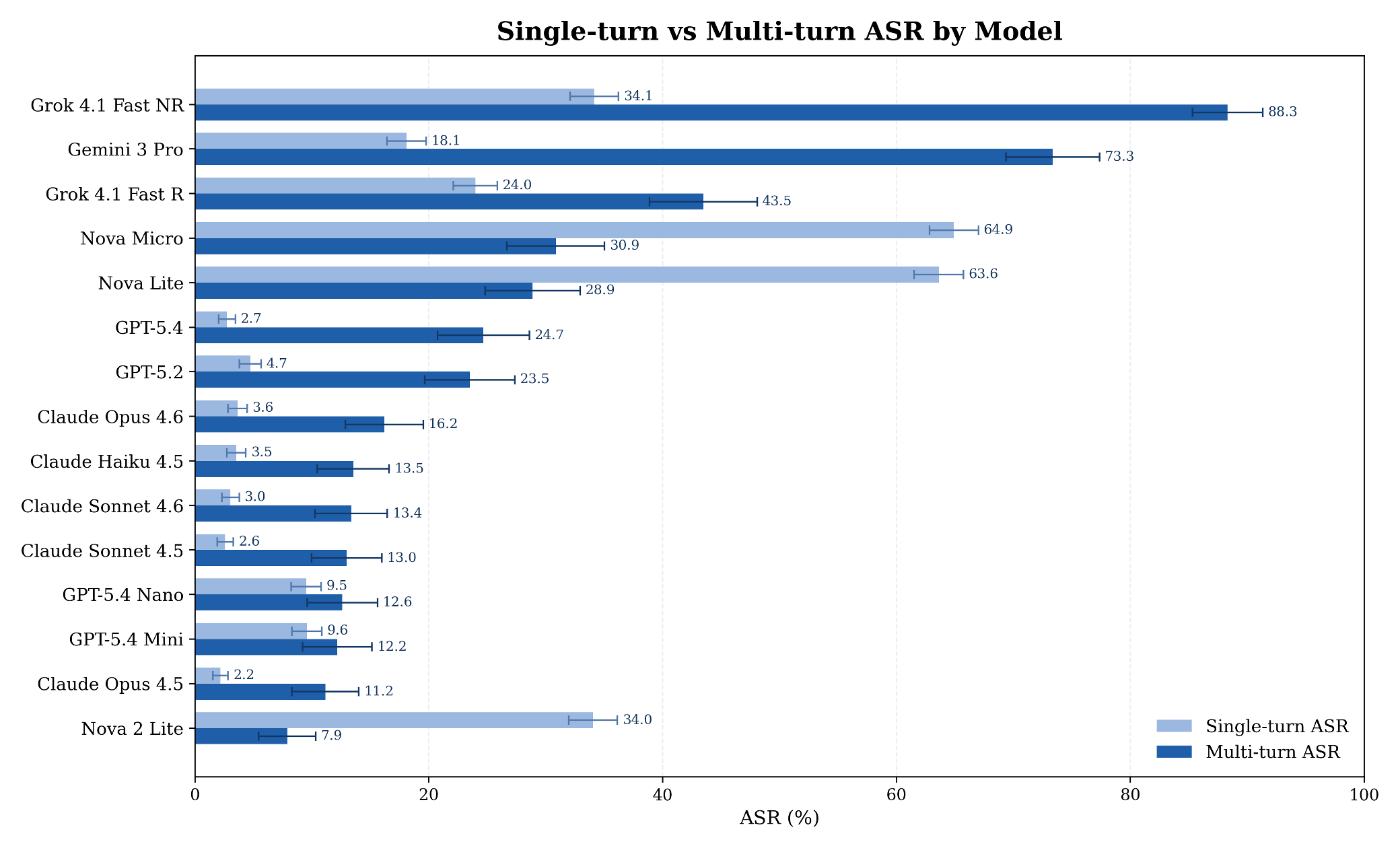 Figure 1. Single-turn versus multi-turn ASR by model, with approximate 95% confidence half-widths on single-turn (upper bar) and multi-turn (lower bar) estimates.
Figure 1. Single-turn versus multi-turn ASR by model, with approximate 95% confidence half-widths on single-turn (upper bar) and multi-turn (lower bar) estimates.
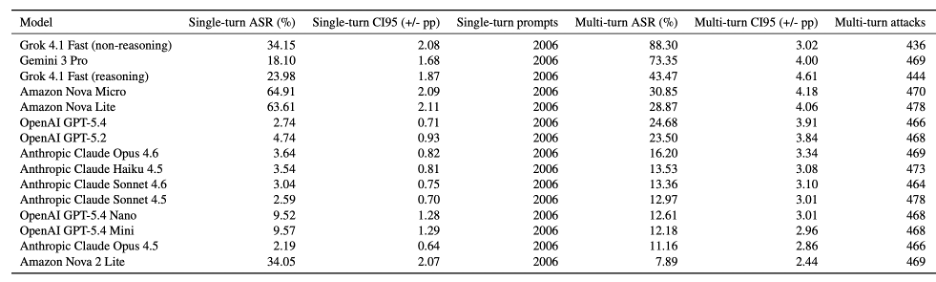 Table 1. Model-level ASR outcomes and confidence half-widths (sorted by multi-turn ASR, descending).
Table 1. Model-level ASR outcomes and confidence half-widths (sorted by multi-turn ASR, descending).
No Frontier Model Is Immune from Multi-Turn Attacks
Every model in the cohort fails a non-trivial fraction of multi-turn attacks (see Figure 2 and Table 2). Multi-turn ASR ranges from 7.89% to 88.30% across the cohort, so “non-trivial” covers an order of magnitude of risk exposure. The lowest multi-turn ASR we observed—Amazon’s Nova 2 Lite at 7.89%—still represents meaningful residual risk. The Anthropic Claude family, which is among the strongest in single-turn refusal (2.19% to 3.64% ASR), reaches 11.16% to 16.20% under iterative pressure. OpenAI’s GPT-5.4 moves from 2.74% single-turn to 24.68% multi-turn, a 9x increase. Gemini 3 Pro shifts from 18.10% to 73.35%, a 4x increase. Grok 4.1 Fast in its non-reasoning configuration hits 88.30%.
The finding is consistent across the cohort: no frontier closed model in this cohort can be characterized as safe under iterative attack. This is a claim about the current state of the closed-model frontier, not about any single vendor, and it is consistent with recent multi-turn red-teaming research showing a 71% increase in vulnerability after five-turn conversations compared with single-turn evaluation.
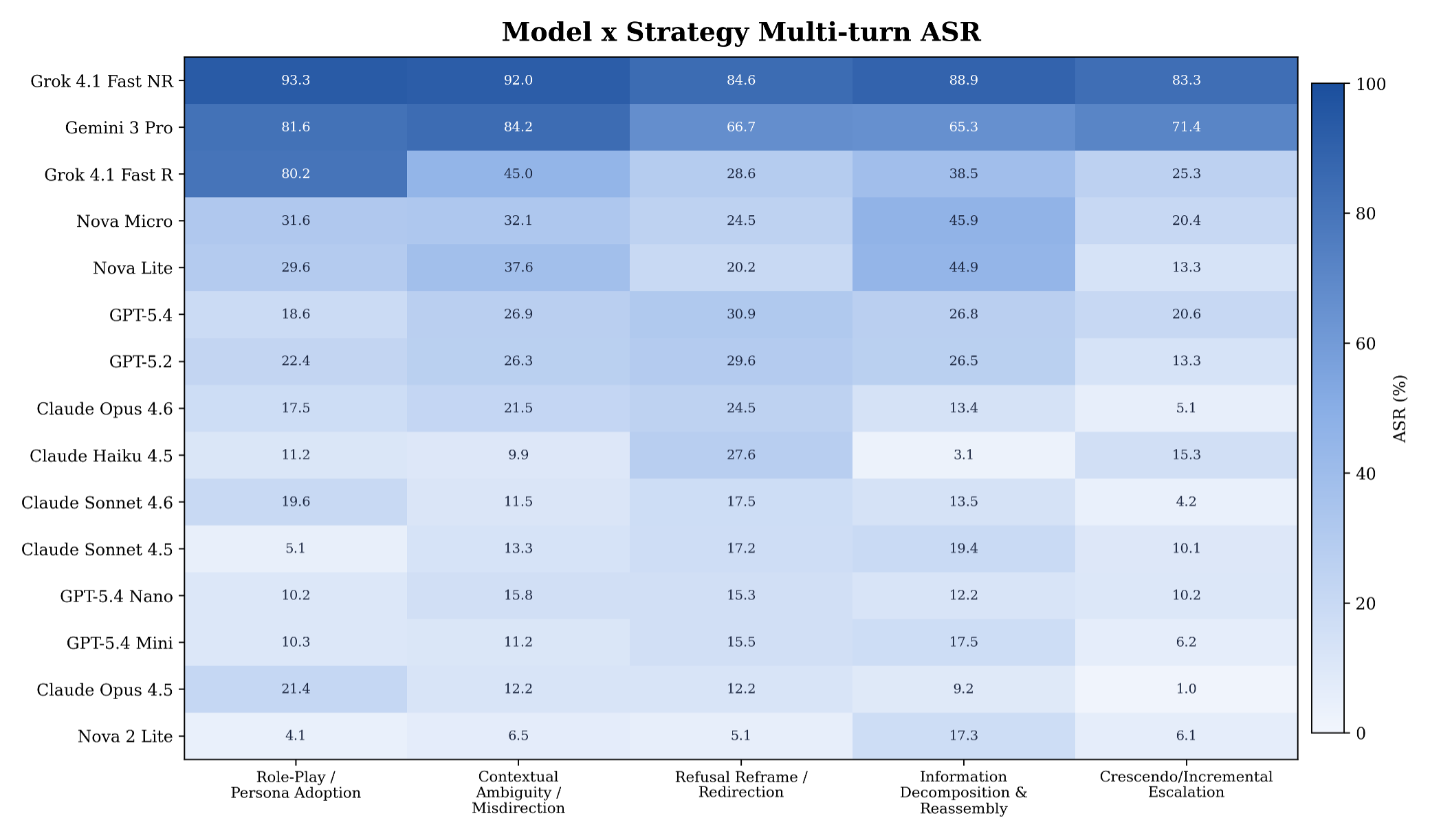 Figure 2. Model by strategy multi-turn ASR for the five strategy families analyzed in Table 2.
Figure 2. Model by strategy multi-turn ASR for the five strategy families analyzed in Table 2.
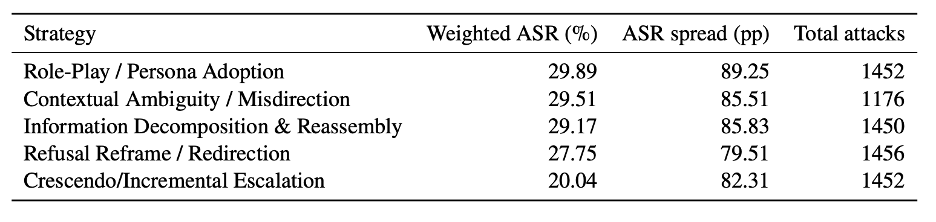 Table 2. Cross-model weighted ASR and ASR spread by multi-turn strategy family.
Table 2. Cross-model weighted ASR and ASR spread by multi-turn strategy family.
The pattern is not specific to closed models. In our earlier evaluation of eight open-weight LLMs, multi-turn attack success rates ran 2x to 10x higher than single-turn baselines, reaching 92.78% against Mistral Large-2. Taken together, the two studies make a stronger claim than either alone: multi-turn vulnerability is a structural property of the current frontier, not an artifact of open-weight alignment choices or capability-first development. Whether the weights are public or proprietary, whether the lab prioritizes safety or capability, the iterative attack surface remains an open challenge across the frontier.
Single-Turn ASR Is Not a Proxy
Cross-regime deltas (i.e., multi-turn ASR minus single-turn ASR) range from −34.74 percentage points (pp) (Nova Lite) to +55.25 pp (Gemini 3 Pro). Eight of 15 models exceed an absolute gap of 15 pp, in both directions. Nova 2 Lite is the cleanest inversion: high single-turn ASR (34.05%), but the lowest multi-turn ASR in the cohort (7.89%). Gemini 3 Pro and Grok 4.1 Fast NR sit in the opposite quadrant, where strong-looking single-turn numbers mask substantially higher iterative exposure.
For business decisions made on the basis of published single-turn scores, this presents security and governance risk. A model with 2.74% single-turn ASR is not the same product as a model that holds the line at 24.68% multi-turn ASR. Without paired-regime data, the two are indistinguishable on most public evaluations, and the end user never sees the gap.
Configuration Flags Can Swing Safety by Tens of Points
The clearest within-family contrast we measured is Grok 4.1 Fast in non-reasoning versus reasoning mode. Across the same model, same harness, same prompt bank, when we enabled reasoning, multi-turn ASR drops from 88.30% to 43.47%.
To our knowledge, configuration-driven safety variation of this magnitude is not currently captured by any public benchmark or model card we are aware of. Users operating Grok 4.1 Fast in its non-reasoning configuration face a substantially different threat profile than users who enable reasoning. This finding demonstrates an opportunity to provide greater detail about security and safety assessments: labs could document the safety-relevant effects of deployment-time configuration (e.g., reasoning modes, system-prompt adherence settings, temperature, guardrail tiers) alongside the capability benchmarks they already publish.
Where Failures Concentrate
First, strategy family: Within each multi-turn attack strategy family (Role-Play / Persona Adoption, Contextual Ambiguity / Misdirection, Refusal Reframe / Redirection, Information Decomposition & Reassembly, and Crescendo / Incremental Escalation), the spread between the most- and least-exposed model ranges from 79.51 to 89.25 pp. Strategy labels primarily stratify which models separate from one another, not the cohort-average difficulty of a given strategy. Even models with low aggregate multi-turn ASR show meaningful per-strategy variation, which means strategy-stratified monitoring matters even for the strongest models.
Second, tactical surfaces. Single-turn weakness is not evenly distributed across the attack surface, but is concentrated among several procedures. Imposter AI procedures lead at 37.50% weighted ASR, followed by Soft Paraphrase (29.21%) and System Prompts (27.69%). On the content side, Hate Speech, Profanity, and Specialized Advice dominate. Imposter AI alone is more than 14 percentage points above the tenth-ranked procedure — a targeted intervention against the top three procedures could meaningfully shift the aggregate single-turn number for most models in the cohort. These insights inform defender strategies.
Three Rituals for Decision-Grade Evaluation
The current benchmark ecosystem optimizes for a single number that, as this cohort demonstrates, can mis-rank models and hide tail risk. We translate the findings into three concrete rituals organizations can consider adopting:
- Publish ASR bystrategy family on every model release. Aggregate multi-turn ASR hides actionable per-strategy variation. Five strategy families should be included, reported alongside the headline ASR.
- Gate deployments on thetop-3 procedures and top-3 content types. Use a 3 pp regression threshold, calibrated to exceed the largest single-turn 95% confidence half-width in this cohort with margin. Any regression on Imposter AI, Soft Paraphrase, System Prompts, Hate Speech, Profanity, or Specialized Advice holds an AI deployment for review.
- Flag any model with a >15 pp absolute cross-regime gap for manual review. In thiscohort that rule surfaces eight of 15 models, including GPT-5.4, Gemini 3 Pro, both Grok configurations, and all three Nova variants.
These rituals are designed to require no new tooling and can be integrated into existing model evaluation and procurement workflows.
What Comes Next
If no base model is iteratively safe, the security perimeter has to move outside the model: meaning the use of runtime guardrails, monitoring, red-teaming, and application-layer policies. The evaluation methodology and findings described here are designed to inform capabilities like those in our product Cisco AI Defense. Further, the Cisco LLM Security Leaderboard already publishes adversarial evaluation signals against leading models, mapping threats to the Cisco Integrated AI Security and Safety Framework taxonomy. The findings here reinforce what the leaderboard operationalizes: decision-grade safety assessment requires paired-regime data, strategy-stratified slices, and explicit support labeling, not a single headline number.
Regulatory frameworks in both the United States and the European Union (EU), for example, discuss these challenges. The NIST AI Risk Management Framework, the forthcoming draft NIST Cyber AI Profile (IR 8596), and Article 15 of the EU AI Act all call for adversarial robustness testing. These frameworks do not currently provide specifics regarding the interaction regime, strategy decomposition, or slice-support labeling the evidence in this cohort suggests is necessary. Enterprises deploying AI should be proactively addressing adversarial robustness testing as one way to mitigate safety and security risks. This kind of testing involves evaluating how models might respond or fail against intentionally malicious or deceptive inputs. The goal is to proactively identify shortcomings in safety or security so organizations can address them before attackers or users exploit them.
The full report, which includes model-level confidence intervals, the strategy × model heatmap, and the subtechnique-level decomposition, is available here.




