
Written by Mehdi Nikkhah, Software Engineer, Cisco Innovation Labs
Service providers are going through a massive network transformation. Increasing demands from new services, in respect to user experience as well as connecting millions of things every year or month as well as creating new value and revenue streams. The solution is to unlock the data that is hidden inside the network. Data that can help to improve services as well as to run networks more efficiently. However, as we unlock it, we get flooded and overwhelmed with data. The solution to this problem is Automation. Automation that gives you an autonomous network, a self-driving and self-healing network. Or in short, an intuitive network.
So, what is one of the underlying key technologies for Automation? It is often referred to as Artificial Intelligence or Machine Learning.
In this blog we want to explain in simple terms what’s so cool about machine learning and how it can be applied to turn overwhelming network data into meaningful output.
Machine learning is all about understanding data and sorting it into some kind of structure, to make them easier to understand. In the recent years, the world has moved from classical modeling schemes to models that are data-driven. This has been mostly fueled by the vast amount of data available from various sources, such as sensors, Internet of Things (IoT), etc. However, the evolution of machine learning algorithms driven by advancements in parallel processing power of GPUs, also played a critical role in exploiting data for modeling purposes. The following picture illustrates data driven vs. classical models:
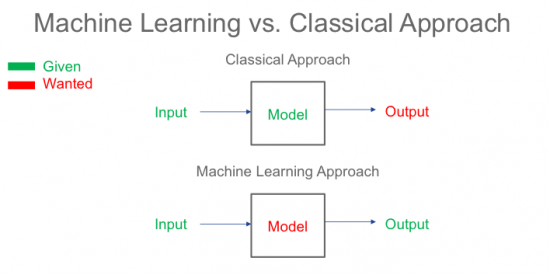
In the classical approach you know a given inputs and you have knowledge about the desired output. This way you could create a model to relate the input to the desired output. In a machine learning approach, however, the inputs and outputs are observed. Using optimization tools, you can create a model that relates the inputs to outputs with a certain precision. The observed inputs are what we call data. The outputs are usually called labels, and the optimization tools are called the machine learning algorithms. For instance, if the goal is to determine whether a picture is of a cat, the data is the picture itself and the existence of a cat is the label (0/1 labels). This is dubbed as “supervised learning”, since a supervisor is required to label the data initially. Usually the supervisor is a human, and that is why labeling is cumbersome. Who wants to look at pictures all day?
So, there may be a better way. Sometimes we deal with data that is not labeled and it is hard, if not impossible, to label it. In those scenarios, we use another approach called “unsupervised learning”. Basically, this is to ask the machine to find features in the data that partition the dataset. For instance, one can give a number of circles in the 2D space, and ask how they can be clustered.
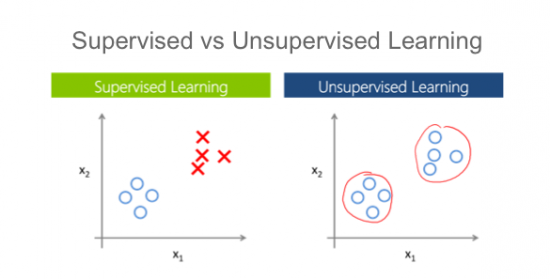
Unsupervised learning is useful, but has its limitations. For instance, a robot that needs to detect an object cannot accomplish this task using an unsupervised learning method, since initially there is no notion of objects given to it. As a result, in many practical scenarios we use supervised machine learning algorithms, and bear the burden of labeling. Although recently a new machine learning approach, called Reinforcement learning has become popular. In this method, we give minimal feedback to the system, while it learns to explore various possible scenarios. A good example of this method in practice is the Google’s Go challenge, where a machine learns to play the game Go much better than the most known Go player champions in the world.
One can categorize machine learning algorithms based on their usage. Some machine learning algorithms are better fits for classification, while others are particularly useful for pattern recognition. Neural networks, for instance, are useful for pattern recognition and prediction, as opposed to logistic regression which is more useful for classification and root cause analysis.
“How does this relate to the Internet of Things IoT?”, you may ask. An example is to use neural networks for pattern recognition in an IoT use-case.
Let us try to answer the following question. Is it possible to detect drunk/sleepy driving behavior using only speed, brake, and steering sensory data from a connected car?
To answer this question, we need to first understand what careless driving is. We know that a drunk or sleepy driver usually tends to swerve across the lanes. There might be other indications of such driving patterns, but this is probably enough for this example. Assuming the speed, brake and steering wheel sensor data is given at a high enough frequency, we need to train a neural network to recognize such driving patterns. First, we need to have labeled data, which can be easily gathered from police reports (vehicle info, time, and location can uniquely identify the car), and assuming that we already collected sensor data from that car, one can give that data to the neural network as a positive label. On the other hand, most of the other drivers are not driving under influence, therefore, we have plenty of data for negative labels. Next step is to train a neural network on a training dataset, and testing it on a separate dataset. This is usually done offline, so the computational load is not an issue.

When the model is ready, we can use it on data from any vehicle and detect whether the driver is under influence or sleepy. Therefore, the answer to the question is yes, detecting careless driving is possible with the right data and the right machine learning tools.
This is just one example, of how data, that is hidden in networks and sensors, can be used to identify a drunk driver in the massive network of cars, streets, roads and highways. This is the approach we also apply to find the “drunk drivers” in your network, that may cause trouble in form of outages, delays, jitter or simple degrading user experience.
Learn more about machine learning in my on-demand webinar and about network automation solutions in our blogs and website.
If you have comments or questions, feel free to drop us a note.







A simple and intuitive explanation, great post and insights within.
nice
Nice article.