
The Other Half of the Story
With model-driven telemetry (MDT), routers can stream out large amounts of operational data in a highly efficient, easily consumable way. But getting data off the box is only half the story. You have to have something on the other end to collect and transform the raw data in preparation for storage and analysis. MDT uses standard transports, RPCs and encodings, so theoretically it wouldn’t be too hard to whip up your own collector using standard libraries and packages. Luckily, you don’t have to start from scratch. Last week, we open-sourced Pipeline, a lightweight collection service that provides the first step in scalable data collection.
Input, Transform, Output
Pipeline is a flexible, multi-function collection service that is written in Go. It can ingest telemetry data from any XR release starting from 6.0.1. Pipeline’s input stages support raw UDP and TCP, as well as gRPC dial-in and dial-out capability. For encoding, Pipeline can consume JSON, compact GPB and self-describing GPB. On the output side, Pipeline can write the telemetry data to a text file as a JSON object, push the data to a Kafka bus and/or format it for consumption by open source stacks. Pipeline can easily be extended to include other output stages and we encourage contributions from anyone who wants to get involved.
What It’s Not
It’s important to understand that Pipeline is not a complete big data analytics stack. Think of it as the first layer in a scalable, modular, analytics architecture. Depending on your use case, that architecture would also include separate components for big data storage, stream processing, analysis, alerting and visualization.
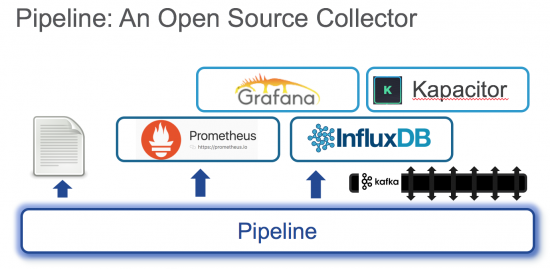 Big data platforms in open source include (among many) PNDA, the Prometheus eco-system and the InfluxDB stack. Pipeline’s function is to process the raw telemetry data from the network and transform it into a format that can be leveraged by powerful systems like these.
Big data platforms in open source include (among many) PNDA, the Prometheus eco-system and the InfluxDB stack. Pipeline’s function is to process the raw telemetry data from the network and transform it into a format that can be leveraged by powerful systems like these.
Try It Today!
If you’re ready to unleash the power of model-driven telemetry, head on over to github and check out the Pipeline repo. And if you need some help getting started with MDT, be sure to check out our tutorials. It’s time to discover what big data analytics can do for your network.






i wonder if you could manipulate the data with Python ?
There are lots of ways you could use Python to interact with the data. If you’re the DIY type, you could write your own version of Pipeline in Python. Or you could deploy Pipeline as is and then write a Python script that pulls data off a Kafka bus or even use Python to query a TSDB like InfluxDB. It’s really just a matter of figuring out what you want to do.
–Shelly
Is this different or better than Telegraf?
Hey, Greg.
First, a disclaimer: while I’ve played with it a little, I’m not a Telegraf expert! There are clearly some similarities with Pipeline, but Pipeline’s specializes in ingesting model-driven telemetry data and making it available to multiple types of consumers. Pipeline can terminate gRPC and TCP sessions as well as perform gRPC dial-in. It can handle all GPB formats and translate to other formats like JSON, multiple TSDB wire formats, etc. It supports all the XR YANG oper models and it can export metrics about its own performance. In short, Pipeline works out of the box for model-driven-telemetry. That said, there’s no reason you couldn’t use Telegraf for MDT if you wanted to spend some time whipping up an input plugin — it looks pretty straightforward and you could use Pipeline as a reference implementation. Or use Pipeline as-is and connect to Telegraf via the Kafka bus if that makes sense in your architecture.
Hope that helps,
Shelly
Great contribution to the open source community. Great piece of software!
Thanks for your Reply Stephanie. You’re right about the longevity and your designs prove this in a very aesthetic way. It’s just sad to see clients downgrade themselves with worse versions after working with you in a short period. I am hoping that for USAToday. Inspiring!
how much is the similar rolex ladies 18k watch http://www.crownuhr.nl/rolex-daydate-president-watch-fluted-bezel-silver-dial-118238sdp-p36/
I would like to thnkx for the efforts you have put in writing this site. I am hoping the same high-grade web site post from you in the upcoming as well. Actually your creative writing abilities has inspired me to get my own blog now. Really the blogging is spreading its wings quickly. Your write up is a great example of it.
http://rakeworld.com/index.php?do=/blog/29857/useful-secret-resources-to-help-looking-for-taxi-company/
As a Newbie, I am continuously exploring online for articles that can benefit me. Thank you
http://clowescourt.co.uk/index.php?title=Best-Anti-Wrinkle-Cream–Best-Face-Cream-r