
This introductory post explains how one of Cisco’s security research groups established a network data collection capability for large amounts of network traffic. This capability was necessary to support research into selected aspects of the Domain Name Service (DNS), but it can be adapted for other purposes.
DNS exploitation is frequently the means by which malicious actors seek to disrupt the normal operation of networks. This can include DNS Cache Poisoning, DNS Amplification Attacks and many others. A quick search at cisco.com/security yields a lot of content published, indicating both the criticality and exposures associated with DNS.
Our research required the ability to collect DNS data and extract DNS attributes for various analytical purposes. For this post, I’ll focus on collection capabilities regarding DNS data.
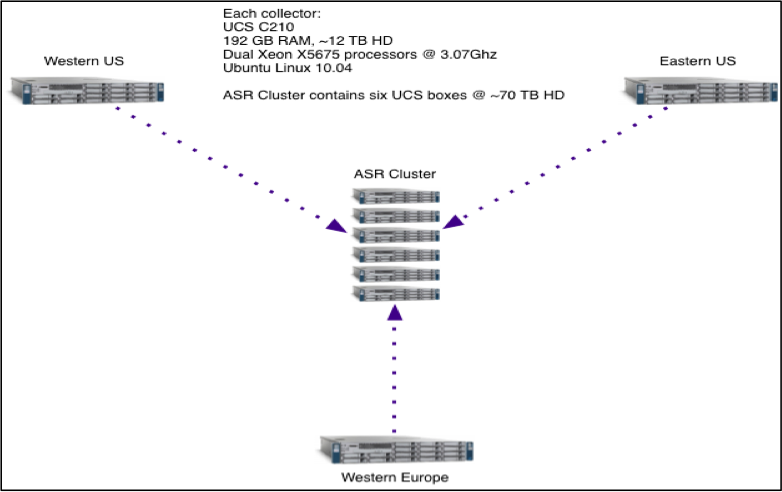
To enable our research, we utilized collection points in the Western and Eastern US as well as Western Europe. The capability required collecting raw network packet captures (pcap), and NetFlow, as well as a scheme to extract and transfer data for analysis.
Transmitting massive amounts of data to a central data store from the geographically distributed collection sites was an impractical option, so our on-premise collectors required substantial local capabilities. The basic requirements for the remote collection systems are:
- Enable collection of 1-3TBytes of data/day – be expandable to accommodate more if needed
- Have local storage capacity for several days of data
- Have local processing capability to extract meta-data from PCAP (Packet Capture) data
- Have local capability for some local analysis
- Accommodate various data types (PCAP/NetFlow in this case)
Each remote collector was based on the Cisco Unified Computing System servers (UCS 210) with attached storage. Each collector has 12TB of storage to store locally collected network traffic. Processing at each collector extracted meta-data from the raw packet capture data and transmitted it to a central storage location in one of Cisco’s East Coast campus locations.
Data Collection and Storage Infrastructure
NetFlow is collected continuously and automatically exported to the central storage location every five minutes. Raw packet capture data is also constantly recorded at the remote collectors and rotated first in, first out as necessary, given the constraints of the local storage. This data is not routinely transmitted to the central storage location unless required for detailed analysis. Analysis of meta-data determines whether any packet capture data is required– usually a relatively small timeslice of traffic for detailed analysis.
Several DNS attributes (meta-data) are collected and are the basis for the initial analysis. Attributes such as query type, payload size, and source port are extracted from the raw captured packets and stored in the time series trend analysis Graphite software package. Graphite is a real time engine for graphing time-series data and can be queried to get average counts per second and aggregate totals over a time period for various DNS attributes. This type of trending informs the need for detailed analysis. Future posts will explain analysis with Graphite in more detail.
Data is transferred back to long-term storage from the collectors. The centrally located, permanent storage cluster is comprised of a set of three (UCS 210 systems running the M3 MapR distribution of Hadoop/HBase). All hosts are currently running Ubuntu 10.04 LTS. Future BLOG posts will explain the central storage more completely.
This system has been used for several months to detect anomalies, accomplish research into malicious activity, and characterize DNS activity on the Internet.
A number of analysis projects are currently underway. Examples of questions we seek to answer include:
- Is the trend toward using DNSSEC increasing?
- What is the distribution of Query Types?
- Can we identify bad actors using DNS meta-data?
The remote collectors are capable of storing several days of raw data, allowing plenty of time for meta-data analysis. A simple, straightforward analysis scheme can quickly and easily help identify obvious anomalies for which packet data may be required for detailed analysis. Any packet data required is transferred back to the central storage leaving us to safely discard the overwhelming majority of raw data. This approach is what enables our storage and transmission requirements to be relatively light weight and manageable.
This data collection and analysis infrastructure will be extended as necessary and adapted to other data sources and types. This approach has enabled analysis of network traffic anomalies and some detailed research into DNS current events. Look for additional posts covering aspects of this project in detail.





