
This article was co-written with Michael Maurer, Cisco Intersight’s Technical Marketing Engineer. See the previous article in this series: Get Ready for Machine Learning Ops.Make sure to check out Cisco Intersight.
If you upload your photos taken from your smartphone camera to your Google account (like I do), you can search your photos by keyword. See the screenshot below from my Google account, of all the hamburgers I have eaten:
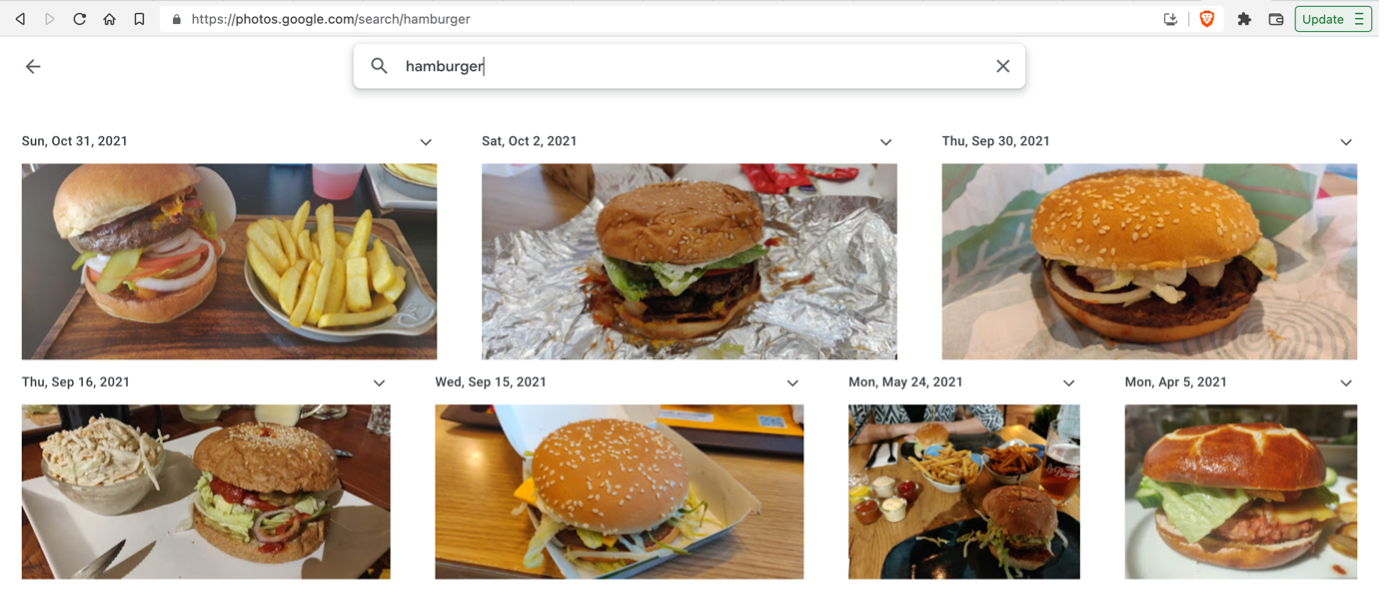
Google’s machine learning image classification and object detection algorithm saves its findings as metadata. There’s a rich infrastructure behind this function, which I covered in Get Ready for Machine Learning Ops.
Today I want to focus on how ML applications like this can be deployed using Cisco Intersight Kubernetes Service. And also how to build an automated ML pipeline using the machine learning framework Kubeflow. Instead of the hamburgers, we’re going to create a sample application to detect digits which you will draw with your mouse. You will get access to all files, and can try out deploying this sample application in your own lab. We’re going to start with setup, and cover the application in the next post.
What’s Kubeflow?
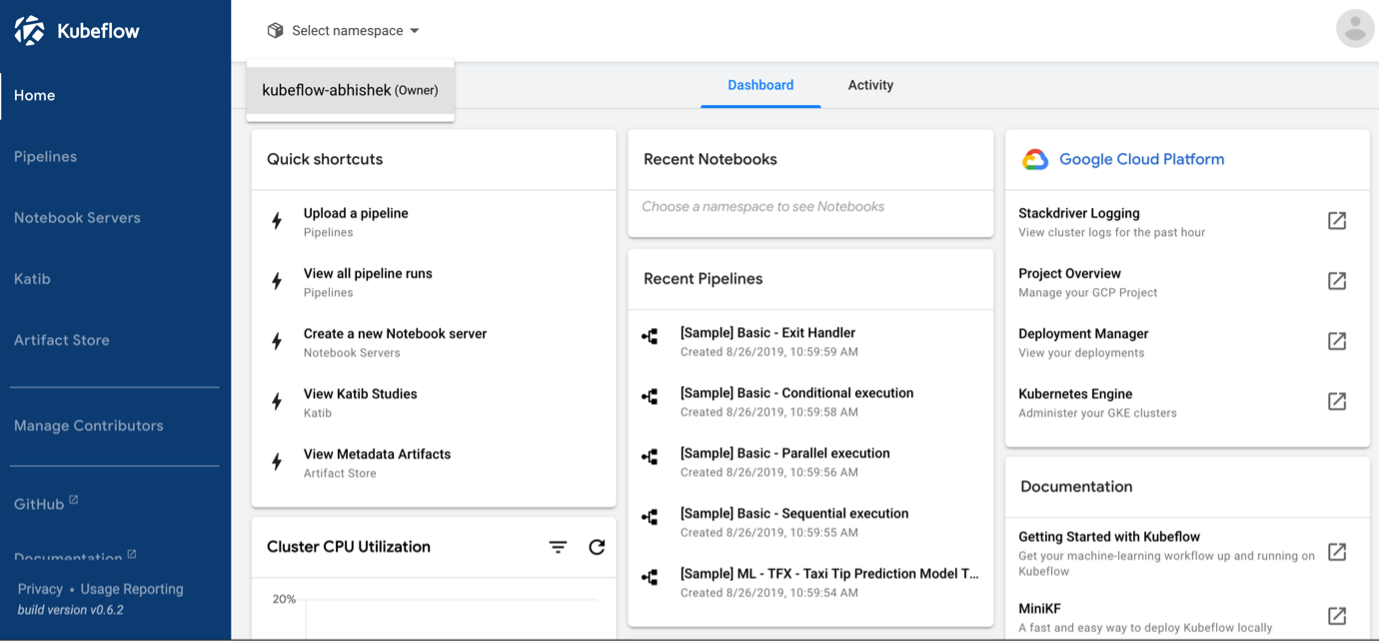
Kubeflow is an open source machine learning framework which orchestrates and automates machine learning workflows. A ML team can use Kubeflow to collaboratively build their ML model with theML library (e.g. Tensorflow, PyTorch) of their choice, and create ML pipelines to cover data transformation, model training, and model serving for production. Kubeflow can run only on Kubernetes clusters and therefore it leverages a lot from the Kubernetes ecosystem and containerizes many functions. Here is an overview of the major Kubeflow components:
Kubeflow Notebooks: Users can create notebook containers. These are containers which run web-based development environments such as JupyterLab, RStudio and VS Code in the browser. These are well-known tools for ML engineering teams to collaborate on their ML code.
Kubeflow Pipelines: This is the most-used component of Kubeflow. It allows you to create, for every step or function in your ML project, reusable containerized pipeline components which can be chained together as a ML pipeline. You can create such pipeline components with a Python SDK. It also allows you to add logic, pipeline inputs, outputs, and other useful functions.
Katib: This component is used for automated machine learning (AutoML) and supports hyperparameter tuning, which is crucial for maximizing the ML model performance. Hyperparameters are important values used during the learning process of the model, as changing them affects the performance of the model.
Kserve (previously KFServing): Kserve is used for model serving. Once the model is built and ready for inference, with Kserve you can spin up your model inference service in containers and add input transformers if needed. (At the end of 2021 Kserve became an independent project and is now an external Kubeflow addon.)
These are not all the components; you can find an overview in the Kubeflow Docs.
When to not use Kubeflow?
Kubeflow is a solid option for MLOps. But it might not fit your organization or use-case. Kubeflow offers a stable UI and Python SDK for you to use, but you might also need to deal with Kubernetes manifests, managing secrets, monitoring/debugging with kubectl etc.
Kubeflow is an especially powerful tool for larger ML applications, but it might be over-powered for smaller applications. Be aware of that and think about how many users will be served, how large the data input is, how often new data will arrive and be added to the training set.
Enter Cisco Intersight
Since we are building everything from scratch, we need to deploy a Kubernetes cluster! This can be done using Cisco Intersight, a hybrid cloud operations platform which allows customers to monitor and automate private and public cloud environments. The infrastructure services inside Intersight allow you to quickly build your core infrastructure.
We will use the Intersight Kubernetes Service (IKS) to build the Kubernetes cluster and the Intersight Cloud Orchestrator (ICO) to write a deployment workflow for Kubeflow.
IKS allows you to build 100% upstream Kubernetes clusters with all necessary services for production. Monitoring comes out of the box, networking and ingress load balancers are already set up and service mesh management is already included.
ICO is an orchestrator that allows you write workflows that can automate anything. With its visual editor you can build out complex environments without a single line of code. Many common operations are already modelled through built-in tasks that are pre-integrated with your inventory, and everything else can be automated using a custom task.
How to deploy Kubeflow on Cisco Intersight
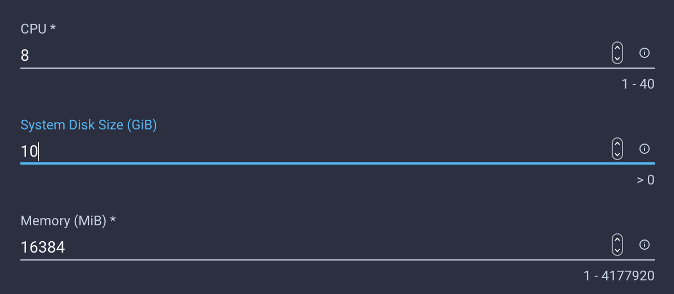
Let’s use IKS to create a Kubernetes cluster. The main decision you need to make is how many resources you want to provide for your machine learning use cases. Depending on that you can scale the number of nodes and their size.
Now that we have the cluster, we can write our deployment in ICO. We are going to do a custom installation using Kubeflow version 1.5. To do this, we will need a copy of the Kubeflow GitHub repository. We can then build our own YAML files using kustomize, which we can then apply to our Kubernetes cluster. Our ICO workflow mirrors these three steps.
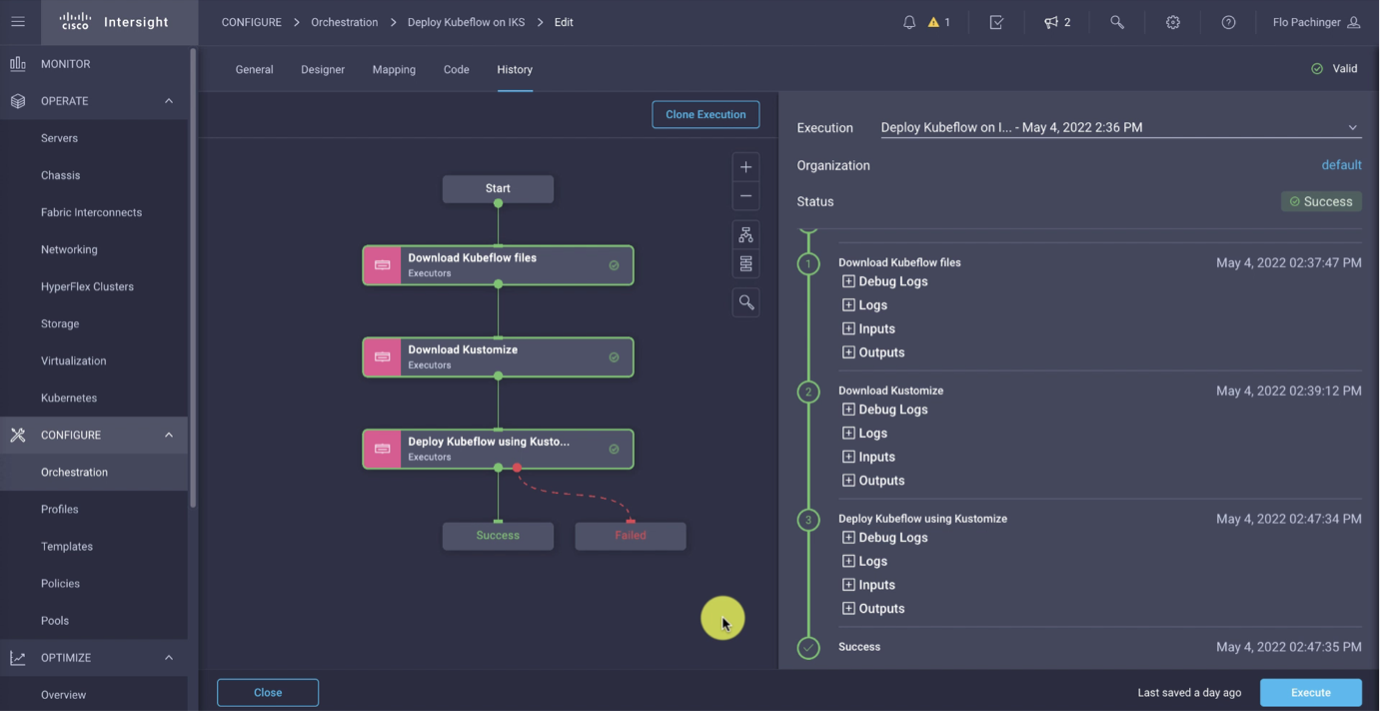
If you want to try it yourself, you can download the workflow.
We also put together an overview video where you can follow the process step-by-step:
Coming up: Building the ML pipeline with Kubeflow
Now you know about Kubeflow and how easy it is to deploy it with Cisco Intersight. In a future blog post, you will see the how you can build the ML pipeline for the digit recognizer application in Kubeflow.
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
LinkedIn | Twitter @CiscoDevNet | Facebook | Developer Video Channel







