
In case you missed the previous post, this is a 4 part series covering the following topics:
1. Container to Container communications
2. Pod to Pod communications (CNI Plugin)
3. How we can track pods and provide external access (Kubernetes Service)
4. Rule based routing (Kubernetes Ingress)
Tracking Pods and Providing External Access
In the previous section we learnt how one pod can talk directly to another pod. What happens though if we have multiple pods all performing the same function, as is the case of the guestbook application. Guestbook has multiple frontend pods storing and retrieving messages from multiple backend database pods.
- Should each front end pod only ever talk to one backend pod?
- If not, should each frontend pod have to keep its own list of which backend pods are available?
- If the 192.168.x.x subnets are internal to the nodes only and not routeable in the lab as previously mentioned, how can I access the guestbook webpage so that I can add my messages?
All of these points are addressed through the use of Kubernetes Services. Services are a native concept to Kubernetes, meaning they do not rely on an external plugin as we saw with pod communication.
There are three services we will cover:
- ClusterIP
- NodePort
- LoadBalancer
We can solve the following challenges using services.
- Keeping track of pods
- Providing internal access from one pod (e.g. Frontend) to another (e.g. Backend)
- Providing L3/L4 connectivity from an external client (e.g. web browser) to a pod (e.g. Frontend)
Labels, Selectors, and Endpoints
Labels and selectors are very important concepts in Kubernetes and will be relevant when we look at how to define services.
https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
- “Labels are key/value pairs that are attached to objects, such as pods [and] are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users. Unlike names and UIDs, labels do not provide uniqueness. In general, we expect many objects to carry the same label(s)”
- “Via a label selector, the client/user can identify a set of objects”
Keeping track of pods
Here is the deployment file for the Guestbook front-end pods.
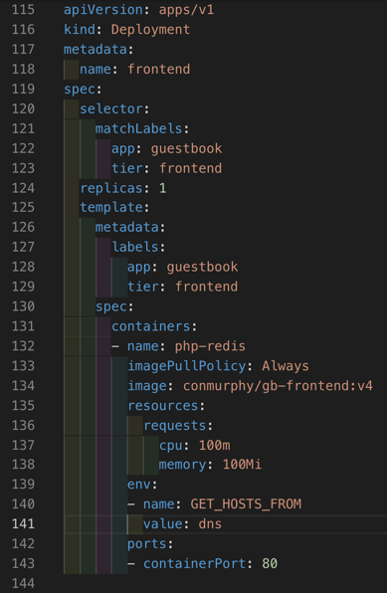
As you can see from the deployment, there are two labels, “app: guestbook” and “tier: frontend“, associated to the frontend pods that are deployed. Remember that these pods will receive an IP address from the range 192.168.x.x
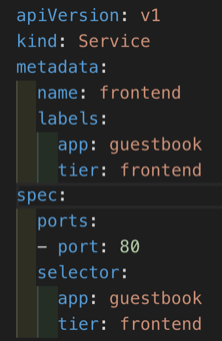
Here is the first service created (ClusterIP). From this YAML output we can see the service has a selector and has used the same key/value pairs (“app: guestbook” and “tier: frontend“) as we saw in our deployment above.
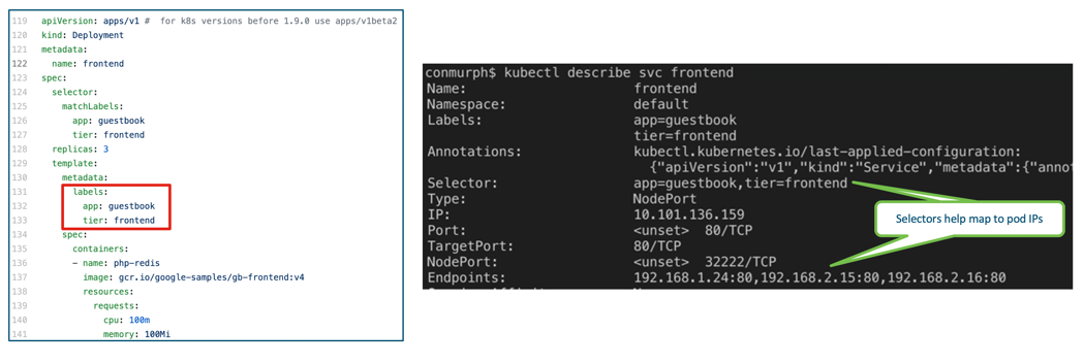
When we create this service, Kubernetes will track the IP addresses assigned to any of the pods that use these labels. Any new pods created will automatically be tracked by Kubernetes.
So now we’ve solved the first challenge. If we have 100s of frontend pods deployed do we need to remember the individually assigned pod addresses (192.168.x.x)?
No, Kubernetes will take care of this for us using services, labels, and selectors.
![]()
Providing internal access from one pod (e.g. Frontend) to another (e.g. Backend)
Now we know Kubernetes tracks pods and its associated IP address. We can use this information to understand how our frontend pod can access any one of the available backend pods. Remember each tier could potentially have 10, 100s or even 1000s of pods.
If you look at the pods or processes running on your Kubernetes nodes you won’t actually find one named “Kubernetes Service”. From the documentation below, “a Service is an abstraction which defines a logical set of Pods and a policy by which to access them”
https://kubernetes.io/docs/concepts/services-networking/service/
So while the Kubernetes Service is just a logical concept, the real work is being done by the “kube-proxy” pod that is running on each node.
Based on the documentation in the link above, the “kube-proxy” pod will watch the Kubernetes control plane for changes. Every time it sees that a new service has been created, it will configure rules in IPTables to redirect traffic from the ClusterIP (more on that soon) to the IP address of the pod (192.168.x.x in our example).
*** IMPORTANT POINT: *** We’re using IPTables however please see the documentation above for other implementation options
What is the ClusterIP?
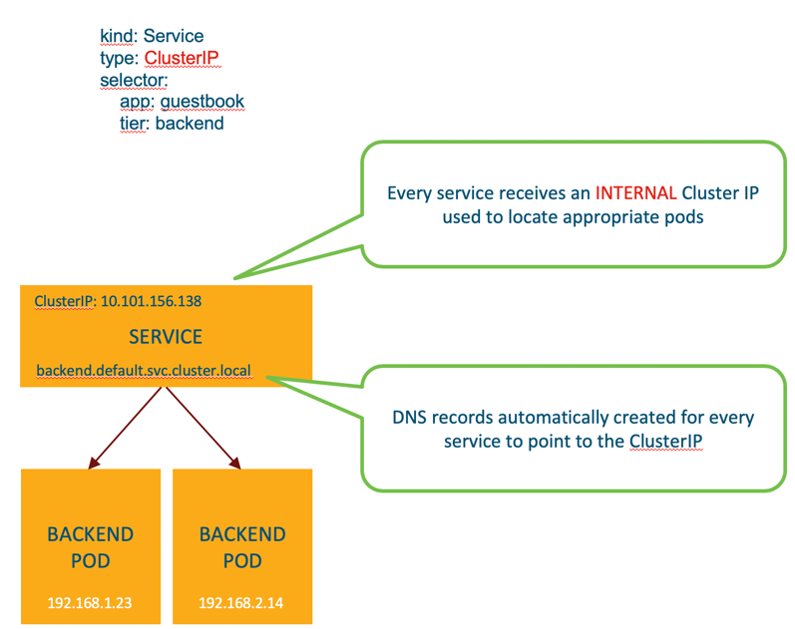
The Kubernetes ClusterIP is an address assigned to the service which is internal to the Kubernetes cluster and only reachable from within the cluster.
If you’re using Kubeadm to deploy Kubernetes then the default subnet you will see for the ClusterIP will be 10.96.0.0/12
So joining the pieces together, every new service will receive an internal only ClusterIP (e.g. 10.101.156.138) and the “kube-proxy” pod will configure IPTables rules to redirect any traffic destined to this ClusterIP to one of the available pods for that service.

DNS services
Before we continue with services, it’s helpful to know that not only do we have ClusterIP addresses assigned by Kubernetes, we also have DNS records that are configured automatically. In this lab we have configured CoreDNS.
“Kubernetes DNS schedules a DNS Pod and Service on the cluster, and configures the kubelets to tell individual containers to use the DNS Service’s IP to resolve DNS names.”
“Every Service defined in the cluster . . . is assigned a DNS name. By default, a client Pod’s DNS search list will include the Pod’s own namespace and the cluster’s default domain.
https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/
When we deploy the backend service, not only is there an associated ClusterIP address but we also now have a record, “backend.default.svc.cluster.local”. “Default” in this case being the name of the Kubernetes namespace in which the backend pods run. Since every container is configured to automatically use Kubernetes DNS, the address above will resolve correctly.
Bringing this back to our example above, if the frontend pod needs to talk to the backend pods and there are many backend pods to choose from, we can simply reference “backend.default.svc.cluster.local” in our applications code and this will resolve to the ClusterIP address which is then translated to one of the IP addresses of these pods (192.168.x.x)
NAT
We previously learnt in the pod to pod communication section that Kubernetes requires network connectivity be implemented without the use of NAT.
This is not true for services.
As mentioned above, when new services are created IPTables rules are configured which translate from the ClusterIP address to the IP address of the backend pod.
When traffic is directed to the service ClusterIP, the traffic will use Destination NAT (DNAT) to change the destination IP address from the ClusterIP to the backend pod IP address.
When traffic is sent from a pod to an external device, the pod IP Address in the source field is changed (Source NAT) to the nodes external IP address which is routeable in the upstream network.
Providing L3/L4 connectivity from an external client (e.g. web browser) to a pod (e.g. Frontend)

So far we’ve seen that Kubernetes Services continuously track which pods are available and which IP addresses they use (labels and selectors). Services also assign an internal ClusterIP address and DNS record as a way for internal communications to take place (e.g. frontend to backend service)
What about external access from our web browser to the frontend pods hosting the guestbook application?
In this last section covering Kubernetes Services we’ll look at two different options to provide L3/L4 connectivity to our pods.
NodePorts
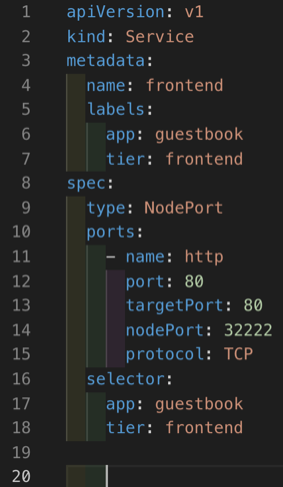
As you can see from the service configuration, we have defined a “kind: Service” and also a “type: NodePort“. When we configure the NodePort service we need to specify a port (default is between 30000-32767) to which the external traffic will be sent. We also need to specify a target port on which our application is listening. For example we have used port 80 in the guestbook application.
When this service has been configured we can now send traffic from our external client to the IP address of any worker nodes in the cluster and specify the NodePort we have chosen (<NodeIP>:<NodePort>).
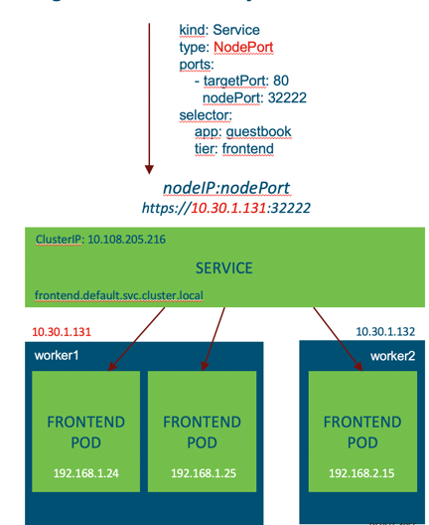
In our example we could use https://10.30.1.131:32222 and have access to the guestbook application through a browser.
Kubernetes will forward this traffic to one of the available pods on the specified target port (in this case frontend pods, port 80).
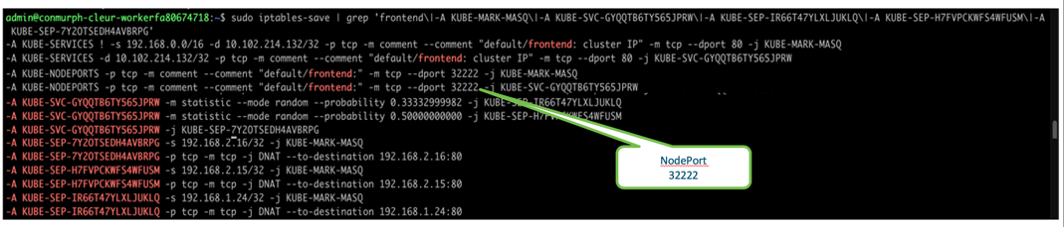
Under the hood Kubernetes has configured IPTables rules to translate the traffic from our worker node IP address/NodePort to our destination pod IP address/port. We can verify this by looking at the IPTables rules that have been configured.
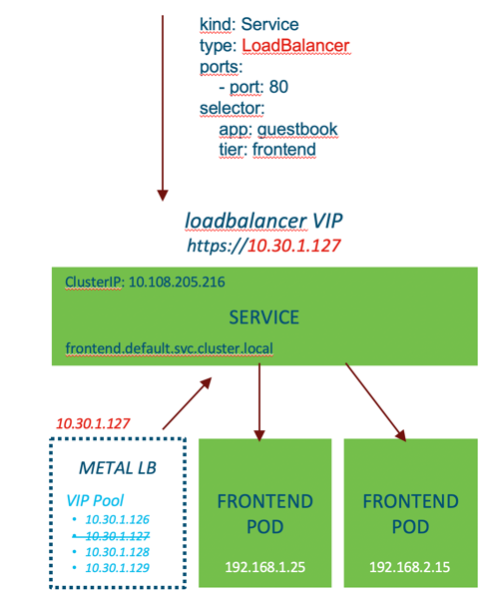
LoadBalancer
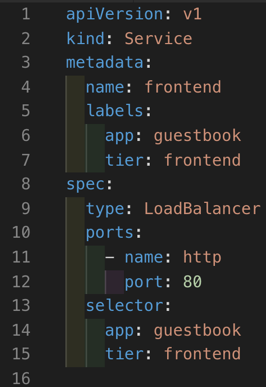
The final topic in the Kubernetes Services section will be the LoadBalancer type which exposes the service externally using either a public cloud provider or an on premises load balancer.
https://kubernetes.io/docs/concepts/services-networking/service/
Unlike the NodePort service, the LoadBalancer service does not use the IP address from the worker nodes. Instead it relies upon an address selected from a pool that has been configured.
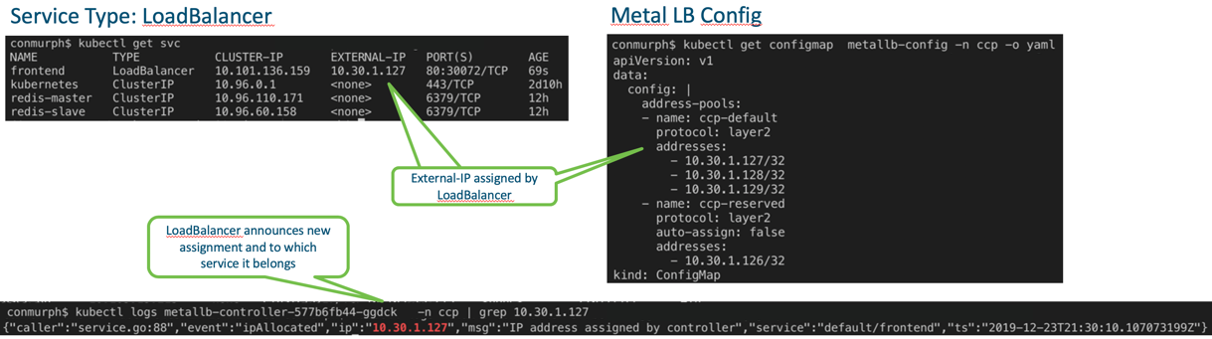
This example uses the Cisco Container Platform (CCP) to deploy the tenant clusters and CCP automatically installs and configures MetalLB for the L3/L4 loadbalancer. We have also specified a range of IP addresses that can be used for the LoadBalancer services.
“MetalLB is a load-balancer implementation for bare metal Kubernetes clusters, using standard routing protocols.”
As you can see from YAML above, we configure the service using “type: LoadBalancer” however we don’t need to specify a NodePort this time.
When we deploy this service, MetalLB will allocate the next available IP address from the pool of addresses we’ve configured. Any traffic destined to the IP will be handled by MetalLB and forwarded onto the correct pods.
We can verify that MetalLb is assigning IPs correctly by looking at the logs.
Related resources:
- Learn network programmability basics
- Should you get a DevNet certification?
- Register to attend DevNet Create 2020
Next Topic: Kubernetes Ingress
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel





Hi Conor,
i have one Springboot app that is deployed on kubernetes and application is listening kafka topics from inteternet but timeout is coming as it is not able to connect it to public internet api