
This is Part 2 in a four part series covering the following topics:
1. Container-to-Container communications
2. Pod-to-Pod communications (CNI Plugin)
3. How we can track pods and provide external access (Kubernetes Service)
4. Rule based routing (Kubernetes Ingress)
2. Pod-to-Pod Communications
In the subsequent topics we will move away from the two-container pod example and instead use the Kubernetes Guestbook example. The Guestbook features a frontend web service (PHP and Apache), as well as a backend DB (Redis Master and Slave) for storing the guestbook messages.
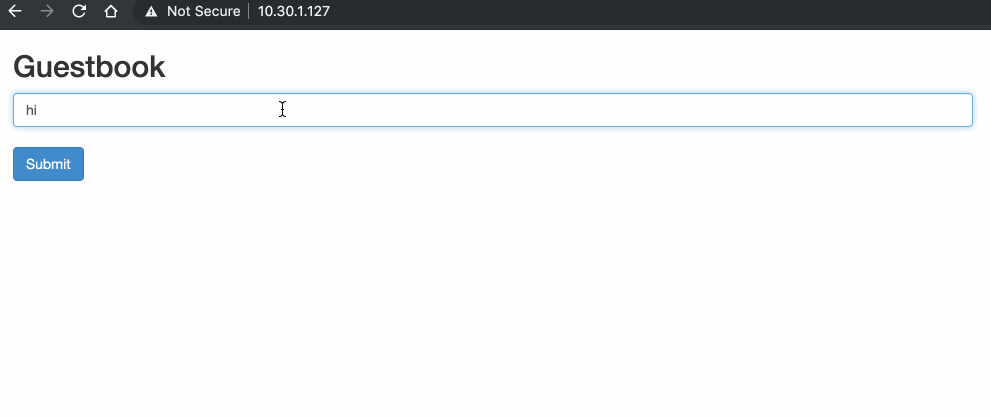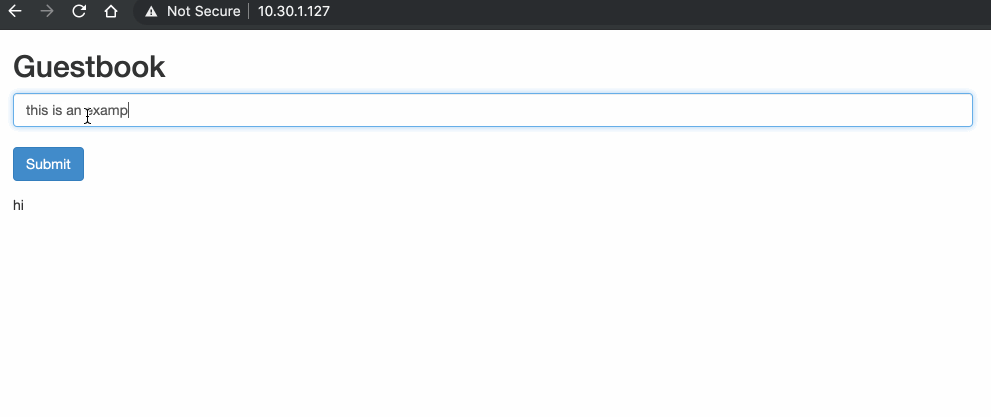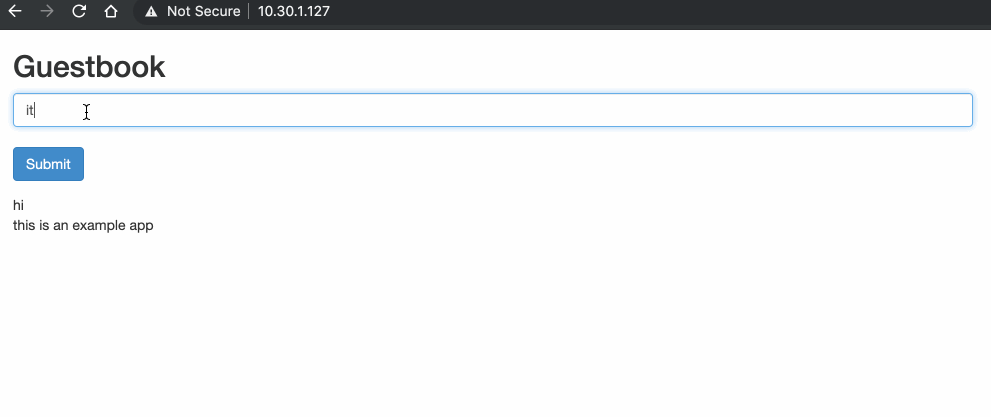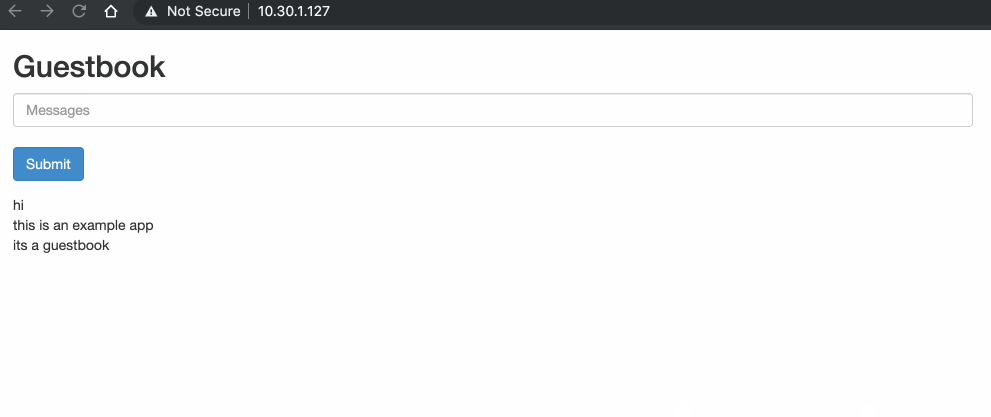
Before we get into pod-to-pod communication, we should first look at how the addresses and interfaces of our environment have been configured.
- In this environment there are two worker nodes, worker 1 and worker 2, where the pods from the Guestbook application will run.
- Each node receives it’s own /24 subnet, worker 1 is 192.168.1.0/24 and worker 2 is 192.168.2.0/24.
- These addresses are internal to the nodes; they are not routable in the lab.
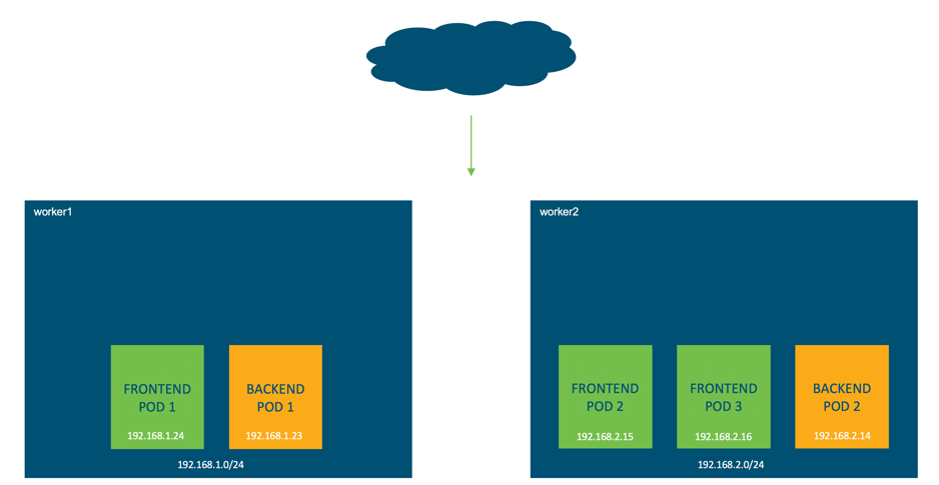
*** IMPORTANT POINT: *** Every Kubernetes pod receives its own unique IP address. As we previously saw, you can have multiple containers per pod. This means that all containers in a pod share the same network namespace, IP address and interfaces.
Network Namespaces
Kubernetes and containers rely heavily on Linux namespaces to separate resources (processes, networking, mounts, users etc) on a machine.
“Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources.”
“Network namespaces virtualize the network stack.
Each network interface (physical or virtual) is present in exactly 1 namespace and can be moved between namespaces.
Each namespace will have a private set of IP addresses, its own routing table, socket listing, connection tracking table, firewall, and other network-related resources.”
https://en.wikipedia.org/wiki/Linux_namespaces
If you come from a networking background the easiest way to think of this is like a VRF and in Kubernetes each pod receives its own networking namespace (VRF).
Additionally, each Kubernetes node has a default or root networking namespace (VRF) which contains for example the external interface (ens192) of the Kubernetes node.
*** IMPORTANT POINT: *** Linux Namespaces are different from Kubernetes Namespaces. All mentions in this post are referring to the Linux network namespace.
Virtual Cables and Veth Pairs
In order to send traffic from one pod to another we first need some way to exit the pod. Within each pod exists an interface (e.g. eth0). This interface allows connectivity outside the pods network namespace and into the root network namespace.
Just like in the physical world you have two interfaces, one on the server and one on the switch, in Kubernetes and Linux we also have two interfaces. The eth0 interface resides in our pod and we also have a virtual ethernet (veth) interface that exists in the root namespace.
Instead of a physical cable connecting a server and switchport, we can think similarly of these two interfaces but this time connected by a virtual cable. This is known as a virtual ethernet (veth) device pair and allows connectivity outside of the pods.
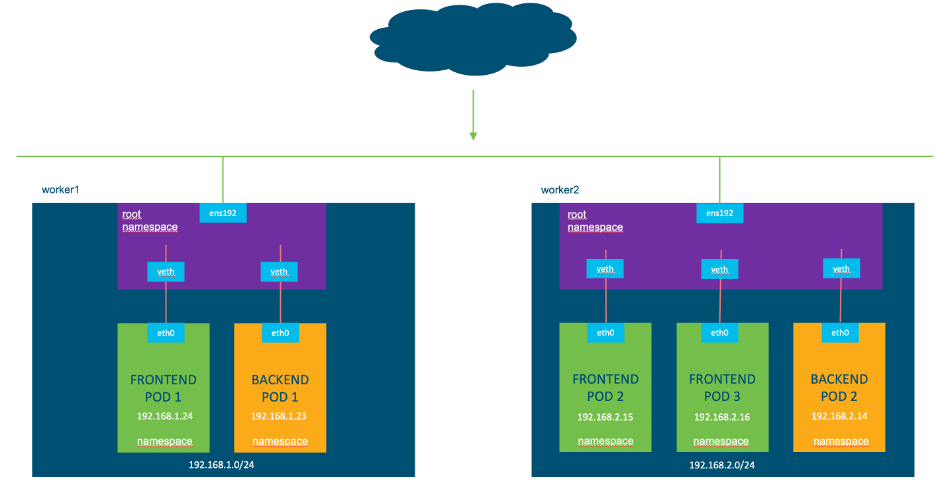
The next step is to understand how the veth interfaces connect upstream. This is determined by the plugin in use and for example may be a tunneled interface or a bridged interface.
*** IMPORTANT POINT: *** Kubernetes does not manage the configuration of the pod-to-pod networking itself, rather it outsources this configuration to another application, the Container Networking Interface(CNI) plugin.
“A CNI plugin is responsible for inserting a network interface into the container network namespace (e.g. one end of a veth pair) and making any necessary changes on the host (e.g. attaching the other end of the veth into a bridge). It should then assign the IP to the interface and setup the routes consistent with the IP Address Management section by invoking appropriate IPAM plugin.”
https://github.com/containernetworking/cni/blob/master/SPEC.md#overview-1
CNI plugins can be developed by anyone and Cisco have created one to integrate Kubernetes with ACI. Other popular plugins include Calico, Flannel, and Contiv, with each implementing the network connectivity in their own way.
Although the methods of implementing networking connectivity may differ between CNI plugins, every one of them must abide by the following requirements that Kubernetes imposes for pod to pod communications:
- Pods on a node can communicate with all pods on all nodes without NAT
- Agents on a node (e.g. system daemons, kubelet) can communicate with all pods on that node
- Pods in the host network of a node can communicate with all pods on all nodes without NAT
https://kubernetes.io/docs/concepts/cluster-administration/networking/
*** IMPORTANT POINT: *** Although pod to pod communication in Kubernetes is implemented without NAT, we will see NAT rules later when we look at Kubernetes services
What is a CNI Plugin?
A CNI plugin is in fact just an executable file which runs on each node and is located in the directory, “/opt/cni/bin”. Kubernetes runs this file and passes it the basic configuration details which can be found in “/etc/cni/net.d”.
Once the CNI plugin is running, it is responsible for the network configurations mentioned above.
To understand how CNI plugins implement the networking for Kubernetes pod to pod communications we will look at an example, Calico.
Calico
Calico has a number of options to configure Kubernetes networking. The one that we’ll be looking at today is using IPIP encapsulation however you could also implement unencapsulated peering, or encapsulated in VXLAN. See the following document for further details on these options.
https://docs.projectcalico.org/networking/determine-best-networking
There are two main components that Calico uses to configure networking on each node.
- Calico Felix agent
The Felix daemon is the heart of Calico networking. Felix’s primary job is to program routes and ACL’s on a workload host to provide desired connectivity to and from workloads on the host.
Felix also programs interface information to the kernel for outgoing endpoint traffic. Felix instructs the host to respond to ARPs for workloads with the MAC address of the host.
- BIRD internet routing daemon
BIRD is an open source BGP client that is used to exchange routing information between hosts. The routes that Felix programs into the kernel for endpoints are picked up by BIRD and distributed to BGP peers on the network, which provides inter-host routing.
https://docs.projectcalico.org/v3.2/reference/architecture/components
Now that we know that Calico programs the route table and creates interfaces we can confirm this in the lab.
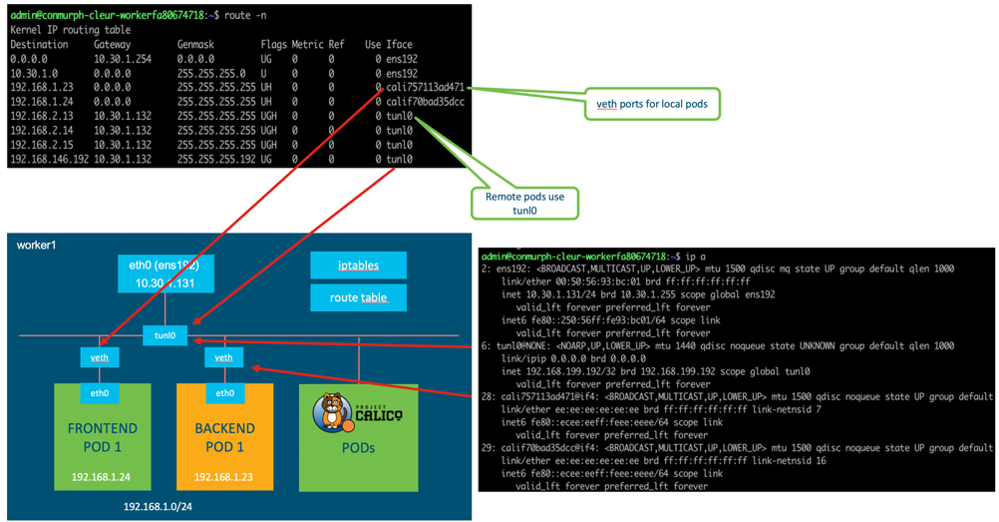
As you can see there are a few interfaces that have been created:
- ens192 is the interface for external connectivity outside of the node. This has an address in the 10.30.1.0/24 subnet which is routable in the lab
- tunl0 is the interface we will see shortly and provides the IPIP encapsulation for remote nodes
- calixxxxx are the virtual ethernet interfaces that exist in our root namespace. Remeber from before that this veth interface connects to the eth interface in our pod
*** IMPORTANT POINT: *** As previously mentioned this example is using Calico configured for IPIP encapsulation. This is the reason for the tunnelled interface (tunl0). If you are using a different CNI plugin or a different Calico configuration you may see different interfaces such as docker0, flannel0, or cbr0
If you look at the routing table you should see that Calico has inserted some routes. The default routes direct traffic out the external interface (ens192), and we can see our 192.168 subnets.
We’re looking at the routing table on worker 1 which has been assigned the subnet 192.168.1.0/24. We can see that any pods on this worker (assigned an IP address starting with 192.168.1.x) will be accessible via the veth interface, starting with calixxxxx.
Any time we need to send traffic from a pod on worker 1 (192.168.1.x) to a pod on worker 2 (192.168.2.x) we will send it to the tunl0 interface.
As per the this document, “when the ipip module is loaded, or an IPIP device is created for the first time, the Linux kernel will create a tunl0 default device in each namespace”
Another useful link points out, “with the IP-in-IP ipipMode set to Always, Calico will route using IP-in-IP for all traffic originating from a Calico enabled host to all Calico networked containers and VMs within the IP Pool”
https://docs.projectcalico.org/v3.5/usage/configuration/ip-in-ip
So how does Calico implement pod to pod communication and without NAT?
Based on what we’ve learnt above, if it’s pod to pod communication on the same node it will send packets to the veth interfaces.
Traffic between pods on different worker nodes will be sent to the tunl0 interface which will encapsulate these packets with an outer IP packet. The source and destination IP addresses for the outer packet will be our external, routable addresses (10.30.1.x subnet).
*** IMPORTANT POINT: *** A reminder that in this example we’re using IPIP encapsulation with Calico however it could also be implemented using VXLAN.
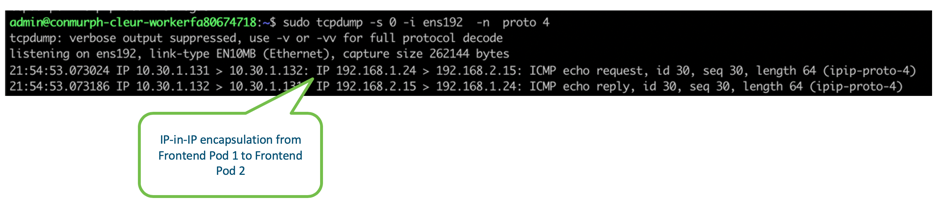
We can confirm this encapsulation is taking place by capturing the packets from the ens192 external interface. As you can see from the screenshot, when we send traffic from Frontend Pod 1 (192.168.1.24) to Frontend Pod 2 (192.168.2.15), our inner packets are encapsulated in an outer packet containing the external source and destination addresses of the ens192 interfaces (10.30.1.131 and 10.30.1.132).
Since the 10.30.1.0/24 subnet is routable in the lab, we can send the packets into the lab network and they will eventually find their way from worker 1 to worker 2. Once they’re at worker 2 they will be decapsulated and sent onto the local veth interface connecting to the Frontend Pod 2.
References
https://github.com/kubernetes/examples/tree/master/guestbook
https://kubernetes.io/docs/tutorials/stateless-application/guestbook/
https://docs.openstack.org/neutron/pike/admin/intro-network-namespaces.html
Related resources:
- Learn network programmability basics
- Should you get a DevNet certification?
- Register to attend DevNet Create 2020
Next Topic: Kubernetes Services
We’d love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel




