
Is your data pipeline static? Are you working with only fixed data sources with predictable data ingestion rate? Probably not? Based on many customer discussions, the data pipeline is constantly changing to accommodate new data sources; hence, the data ingestion rate is often unpredictable. The only thing that is certain is that more changes are coming. For many IT teams, this uncertainly leads to a lack of clear requirements making it challenging to proceed. Yet, it is in this dynamic environment that the enterprise needs to accelerate AI/ML deployment or risk having competitors leverage artificial intelligence and machine learning as a competitive advantage.
Unified, Scalable Architecture Enables Scaling at Your Own Pace
Here at Cisco, providing a unified, scalable architecture enables our customers to start small and then scale quickly. For example, some of our big data customers started with just a few nodes of UCS and grown to thousands of servers within a cluster. Having that scalable architecture has been the key for their growth. It has been awesome to see that the Hadoop community evolved its architecture to be able to support containers and GPUs. Hence, the big data scalable architecture is now able to support artificial intelligence and machine learning as well. Cisco Validated Design with Hortonworks even details how to run TensorFlow from NVIDIA’s container repository, NGC. In a similar way, Cisco’s solution for converged infrastructure are able to grow from terabytes of data to petabytes of data. Rather than creating a new infrastructure silo just for AI/ML, FlexPod Datacenter for AI/ML is able to extend existing architecture to support AI/ML. In a similar way, FlashStack for AI is also extending existing proven architecture to support AI/ML with Cisco UCS C480 ML. At Cisco Live Barcelona, we even showed how Cisco HyperFlex is able to provide customer sentiment analysis: Highlighting the need to extend the data pipeline all the way to the edge of the network.
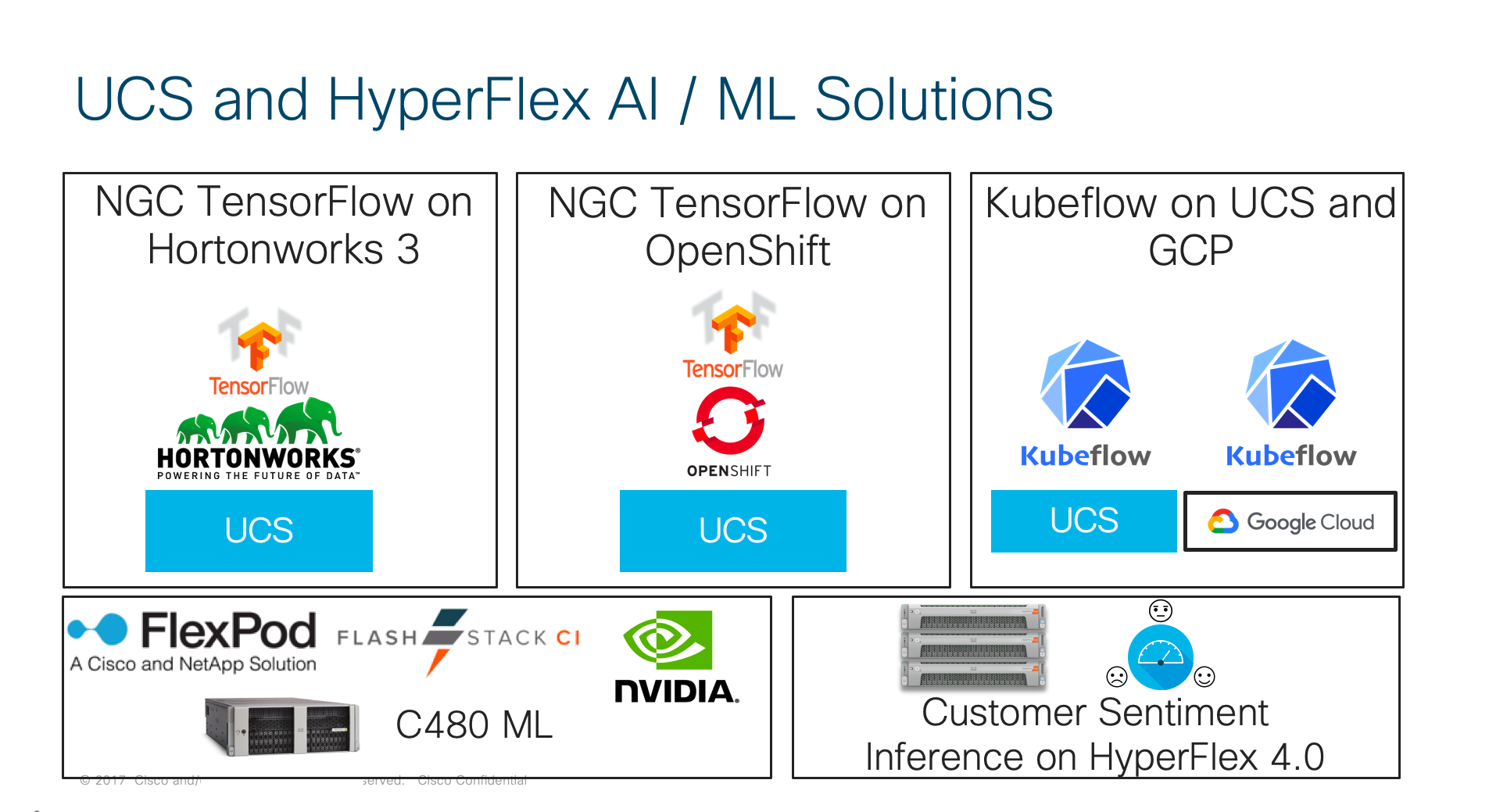
Kubeflow: A Single Data Pipeline and Workflow
Cisco is continues to enhance and expand the software solutions for AI/ML. For example, Cisco is working with Kubeflow, an open source project started by Google to provide a complete data lifecycle experience. With Kubeflow, customers can have a single data pipeline and workflow for training, model evaluation, and inferencing leveraging reusable software components.
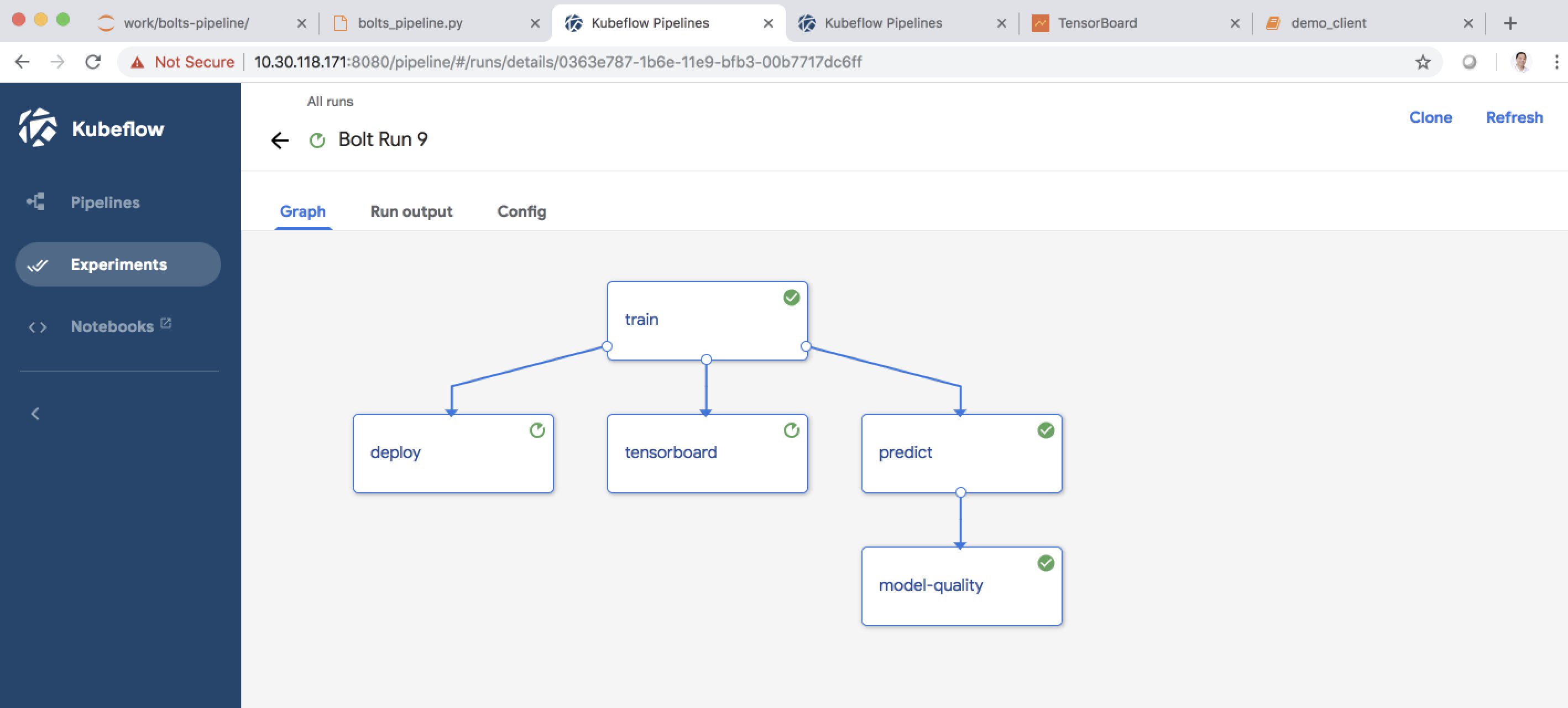
In fact, Cisco has contributed over 2.8 million lines of code with 3 major proposals in Kubeflow, such as Kubebench for benchmarking, PyTorch for additional deep learning framework support, and Katib for hyperparameter search and AutoML. At GTC in San Jose, I am excited to have Sina Chavoshi, Google Technical Program Manager for machine learning, and Debo Dutta, PhD, Cisco Distinguished Engineer join me on stage at the session titled Accelerate, Scale, and Operationalize Data Pipelines. We will go over the details of the collaboration between Cisco and Google ensuring that customers have consistent AI/ML experience whether on-premise or in the cloud. We will also show a demonstration of how deep learning image classification can be used to distinguish bolts that are measured in inches vs. centimeters. In a manufacturing line, using the wrong bolt can ruin equipment. I know I certainly have even in my own small projects in my garage!
In the world of AI/ML, rapid change is clearly a constant. Please stop by and continue to conversation at the Cisco booth, number 929, at GTC in San Jose next week. If you will not attending GTC next week, please tune in to the Google Cloud OnAir webinar on Thursday, March 21, 2019, Deploying the AI/ML Data Pipeline Anywhere, where Google and Cisco will go into more detail of the Kubeflow collaboration.





