
Guest Bloggers:
Siva Sivakumar, Senior Director, UCS Solutions, Computing Systems Product Group, Cisco
Karthik Kulkarni, Architect – Big Data Solutions, Computing Systems Product Group, Cisco
In today’s digital world where sensors, Internet of Things (IoT) devices, social media, and online transactions are generating enormous amount of data, the enterprises who have been processing this deluge of data for close to a decade are struggling to find newer and intelligent way on how to further distill this data to drive more innovation, insights and competitive advantage.
The availability of faster compute with GPUs and advancement in Artificial Intelligence and Machine Learning (AI/ML) and its frameworks have had a major impact in all verticals where industries are beginning to look at their old problems and adopting these new AI/ML techniques to solve the problems, get deeper insights which they didn’t have access to earlier.
This drove the next generation of Hadoop (Hadoop 3.0) which enables both different types of compute with GPUs and AI/ML applications to be natively scheduled in a Hadoop cluster.
If we see the larger Hadoop ecosystem, we are currently in a transition where it is “Big data or Hadoop meets AI”. Hadoop with its latest major release of Hadoop 3.0 is calling this out clearly where Hadoop is going to enable IT and data scientists by providing a single cluster to allow for not just managing and transforming data but also allow for different application frameworks and different types of compute operate on it to derive value out of this data, be it analytics, Machine learning or Deep learning.
Artificial Intelligence requires large amounts of data for its training and Hadoop is a natural fit for storing and retrieving these large amounts of data. Many AI/ML tasks requires the use of GPUs, a specialized, very high-performance processor that is massively parallel in nature. This solution focuses on Hadoop accelerating AI natively where GPUs are part of a Hadoop cluster and are natively scheduled by Hadoop schedulers to process massive amounts of data stored in the same cluster.
Hadoop 3.0 enables managing GPUs as a compute resource by providing GPU isolation and scheduling. It provides first class support for Docker containers and have deep learning applications run on these Docker containers which have access to GPU. All of this is natively managed and scheduled by Hadoop through its scheduler YARN (Yet another Resource Negotiator) while allowing these docker containers access petabytes of data resident in its cluster.
This will open up new doors to our customers in multiple different use cases including those which were typically not a Hadoop play to start with. One such use case is video analytics. We have large airports, railways which traditionally had a more canned video surveillance or “video analytics in box” solution considering alternatives, one which is more of a platform, where not only are they going to store data on Hadoop but keep adding newer applications to video feeds. Deep Learning techniques are very powerful in NLP (or Natural Language Processing), use cases which were doing rich sentiment analytics don’t need to leave a Hadoop cluster to run additional sentiment analysis. Fraud detection in banking and payments are empowered to run deep learning techniques to their current data sets to identify frauds.
Now, building this next-generation big data architecture requires simplified and centralized management, high performance, and a linearly-scaling infrastructure and software platform.
We are happy to announce our first Cisco Validated Design on Hadoop 3.0 in partnership with Hortonworks and Nvidia.
Solution Highlights:
- Ability to manage GPU as a compute resource by providing GPU isolation and scheduling
- Provides first class support for Docker containers and have deep learning applications, such as Tensor flow, run on these Docker containers
- Direct access to petabytes of data on UCS clusters from applications running in containers
- Cisco UCS reference architecture designed to scale from few to thousands of servers and hundreds of petabytes of storage with ease, and managed from a single pane of glass
The solution is on Cisco UCS Integrated Infrastructure for Big Data and Analytics on Cisco UCS M5 servers with Hortonworks Data Platform (HDP 3.0). The solution provides a large portfolio of servers with choice of 2,4, 6 or 8 GPUs in a single server. The CVD goes into details of our newly launched Cisco UCS C480 ML M5, custom built server for AI workloads with 8 Nvidia V100 GPUs with 32G memory connected through NVLink technology.
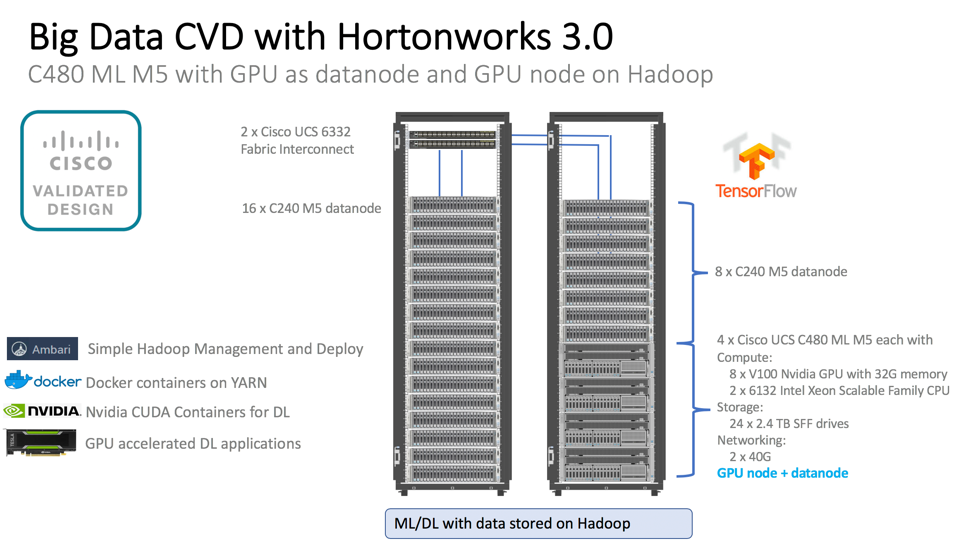
Link to Cisco Validated Design:




