
The Future of Hardware Blog Series – Blog #2
In my first blog in this three part series, I discussed the rapid growth of key performance metrics across CPU/GPU cores, memory, network throughput, storage capacity, and peripheral interconnects. These numbers certainly attest to the sheer scale that the compute industry is willing to throw at the problem of supporting the explosion of workloads and applications that we are experiencing with the mainstream adoption of cloud, mobile, and social technologies. In this second blog in this Future of Hardware series, I talk about how memory upgrades in high performance computing design today are changing the game.
Just throwing more resources at difficult and complex challenges willy-nilly can often be an inefficient solution. If the resources are not used smartly and efficiently, it can lead to a lot of waste and excess. A relevant example is internal storage in computing systems. Since the earliest days of computing system design, it was a given that embedded storage was a required component. That made sense – computers and their apps generate a lot of data, and it must be stored and retrieved from somewhere, right? It would make sense that the best place to house the storage would be as close to the apps themselves. Technology upgrades in high performance computing have certainly been a required addition.
But not every computing system (be it a server or laptop) is built and used the same. So, in an environment with multiple computing systems, e.g., a rack or data center, there was a natural variation of internal storage utilization between host to host. Some hosts ran hot and needed upgrades of storage capacity. For other hosts, storage usage was fallow as a wheat field in the coldest of winters. In this case, one of the best solutions was to disaggregate storage into external pools of drives and arrays, which led to a boom of external storage innovation by HDD array players like EMC and NetApp, and later by a number of flash/SSD array vendors like Pure Storage. Further, pooling and sharing storage required other innovations such as intelligent partitioning, snapshotting, and RAID striping. Shared external storage also simplified data backups and disaster recovery/business continuity, among many other benefits.
The upside of the disaggregating memory
What if we can do the same with the decoupling of computer memory to solve high performance computing complexities? Like internal storage, it has always been taken for granted in computing system design that memory had to be tightly coupled with CPU architectures. Look at any computer motherboard and you’ll see how close in “real estate” CPUs and memory chips tend to occupy – of course, this also applies to systems needed to power CPUs and memory chips. This approach logically impacted how CPUs (and GPUs) must be designed and installed. It also impacted how applications had to be developed and operated.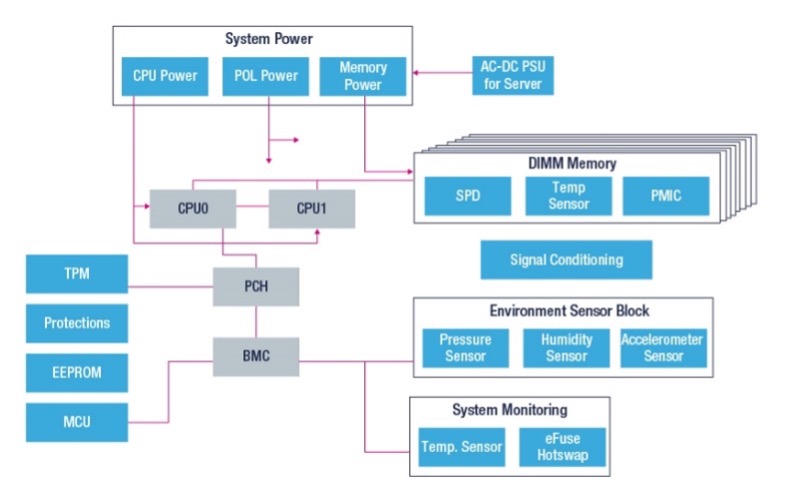
But change is afoot. Over the next three to five years, I see an acceleration of the decoupling of memory from computing systems. And like in the storage example, this memory can be pooled and shared by not just the CPUs/GPUs in a single host but by many. Further, it will lead to new innovations and approaches in how memory can be utilized (e.g., memory tiering). This approach will also solve some significant shortcomings of current compute system design with respect to internally attached memory:
- Compute and memory requirements no longer have to be pre-sized, which tends to eat up multiple terabytes just to ensure for growth.
- Like internal storage, memory utilization can vary from host to host, leaving some servers with a lot of unused embedded memory that could not be accessed by any other system.
- Embedded memory and its supporting componentry (power, cooling, and electrical) took up valuable space that could otherwise be allocated to other use cases, such as more processing power.
You can easily imagine how avoiding these system design restrictions can eliminate many of today’s complexity and limitations with compute operations. A logical result might be systems that are more compute intensive and more operationally efficient – think fewer physical servers that can support even more workloads and applications than possible today. Also imagine new and novel ways to scale disaggregated memory – by using hot-swappable and pluggable DIMM sticks, for example, that will free up blades and motherboards for more processing, power, and cooling.
This massive shift will not take place overnight and will require industry players in hardware, software, silicon, and applications to come together in an ecosystem to ensure success. There’s already a lot of activity in solving the challenges of memory hierarchy and tiering – e.g., VMware’s Project Capitola, Open Compute’s Hierarchical Memory project, as well as a number of startups like MemVerge who are rising to this challenge.
We are actively monitoring and participating in these new trends in high performance computing. In fact, we have already built a future-ready computing platform in the UCS X-Series Modular System with a refreshed converged fabric and new x-fabric that takes advantage of disaggregation of memory, storage, and networking to enable more efficient and compute intensive operations. So, whatever paths this exciting evolution may take, we’ll be ready.
Be sure to stay tuned for my third blog in this series coming soon, where will be taking an even deeper dive into more of the modern advancements of storage hardware from Cisco. If you missed the first blog in this Future of Hardware Series, visit Today’s Advancements in Compute Hardware Can Power the Next Generation of ‘Moonshots’.
Resources
The Future of Hardware Blog Series: Blog 1: Today’s Advancements in Compute Hardware Can Power the Next Generation of ‘Moonshots’



