
Author: Siva Sivakumar – Senior Director, Data Center Solutions
Overview: Provide Hadoop and AI customers additional options to run their AI workloads on Hadoop or a Kubernetes farm natively using Apache Spark.
This new release of Apache Spark 3.0 enables customers to pool hundreds of NVIDIA GPU resources across hundreds of nodes to run a single distributed deep learning workload. This will bring different AI frameworks such as TensorFlow to work within Spark, paving the way to more NVIDIA GPU-accelerated workloads within Hadoop.
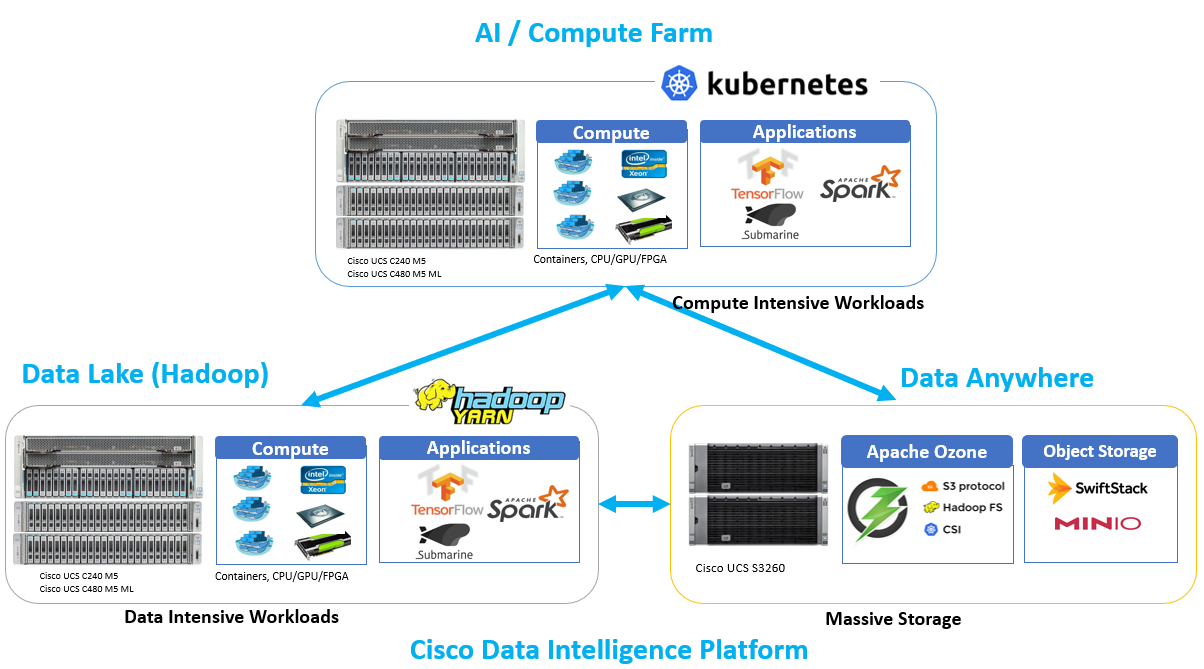
Distributed Deep Learning with Apache Spark 3.0 on Cisco Data Intelligence Platform with NVIDIA GPUs
A few months ago I wrote about how, for the first time, data scientists could run distributed deep learning workloads by pooling NVIDIA GPU resources from different nodes to work on a single job within a data lake (managed by YARN) through Apache Submarine.
With today’s announcement by NVIDIA to contribute GPU support for Apache Spark 3.0, data scientists will now have the option to accelerate such distributed deep learning workloads natively in Apache Spark.
The Apache community released a preview of Spark 3.0 that enables Spark to natively access GPUs (through YARN or Kubernetes), opening the way for a variety of newer frameworks and methodologies to analyze data within Hadoop.
This natural evolution of Apache Spark will cater to newer forms of compute, such as acceleration with NVIDIA GPUs, and will provide our customers with more options to analyze their data:
- Different forms of compute: Spark is no longer limited to CPUs for its workloads. It can now make use of different forms of compute such as CPUs and GPUs for ETL (Extract, Transform and Load) and AI jobs in a distributed fashion.
- Distributed GPU pooling: This new release of Spark 3.0 enables customers to pool hundreds of NVIDIA GPU resources across hundreds of nodes to run a single, distributed GPU-accelerated workload.
- Supporting multiple schedulers: Spark 3.0 can work with both YARN – a native Hadoop scheduler for both YARN containers or Docker containers – or with Kubernetes for Docker containers – giving customers more options to address different use cases.
Enable New Workloads with the Cisco Data Intelligence Platform
Cisco Data Intelligence Platform is a robust platform that provides the architectural foundation for enabling these exciting new developments in the Hadoop community. These features will enable new workloads and use cases for data scientists and data engineers including:
- Deep learning workloads directly with Apache Spark on YARN or Kubernetes
- Deep Learning workloads with AI frameworks such as TensorFlow, PyTorch and others on YARN or Kubernetes through Apache Submarine
Cisco and NVIDIA: A Collaboration that Delivers
Together, Cisco and NVIDIA deliver the GPU-accelerated data center to power your artificial intelligence and accelerated analytics practice, enabling you to accelerate insights and outcomes, turbocharge your data center, and innovate for the future.
Cisco Unified Computing System (UCS) supports a variety of NVIDIA GPUs that can deliver the compute power needed for your most demanding data analytics workloads.
Cisco’s long history in the data analytics space, combined with NVIDIA’s leadership position in powering GPU-accelerated workloads, make it easy for customers to capitalize on these new Apache Spark capabilities.
Apache Spark 3.0 Demo
Cisco and NVIDIA have teamed up to illustrate how data scientists can take advantage of Apache Spark 3.0 to launch a massive deep learning workload running a TensorFlow application. The demo below showcases how YARN pools and schedules GPUs can be utilized across nodes for a Spark 3.0 distributed job. It also illustrates how data scientists can monitor the progress of their jobs and IT can monitor the resources.
In Summary
The Cisco Data Intelligence Platform with NVIDIA GPUs will provide Hadoop and AI customers additional options to run their AI workloads on Hadoop or a Kubernetes farm natively using Apache Spark 3.0.
Learn more about Cisco data analytics solution: www.cisco.com/go/bigdata






Sowoowowoww