
Author: Siva Sivakumar – Senior Director, Data Center Solutions
Data scientists constant search for newer techniques and technologies that can unlock the power of their data is leading them towards artificial intelligence (AI) and machine learning (ML) tools and methods. Consequently, this evolution is creating a need for data intensive and compute intensive workloads to come closer together and operate within the same overall architecture rather than in silos. So, in order to address this problem, we introduced the Cisco Data Intelligence Platform (CDIP) a few months ago.
Today, as part of our phased launch approach, I’m happy to announce two new Cisco Validated Designs implementing our Cisco Data Intelligence Platform–with Hortonworks Data Platform 3.1. and Cloudera Enterprise Data Hub 6.2.
Working with Cloudera and Hortonworks
Cisco and Cloudera have worked together to create a solution that addresses today’s most challenging problems for data scientists and IT. Thanks to this collaboration, earlier this year, we created the industry’s first fully comprehensive Hadoop meets AI Cisco Validated Design with Hadoop 3.0 and Hortonworks.
Today, we are announcing two new reference architectures (CVDs) that implement our CDIP with Cloudera, which include advancements in AI technologies.
- Distributed deep learning: Apache Submarine allows for AI workloads to pool GPU resources from different nodes to work on a single job within a data lake (managed by YARN);
- Cloudera Data Science Workbench: The Kubernetes stack provides a self-service portal for AI and machine learning workloads; and
- Data Lake: Provides data and processing for data intensive workloads.
Cisco CVD with Cloudera Enterprise Data Hub 6.2
Cisco CVD with Hortonworks Data Platform 3.1
An overview of CDIP
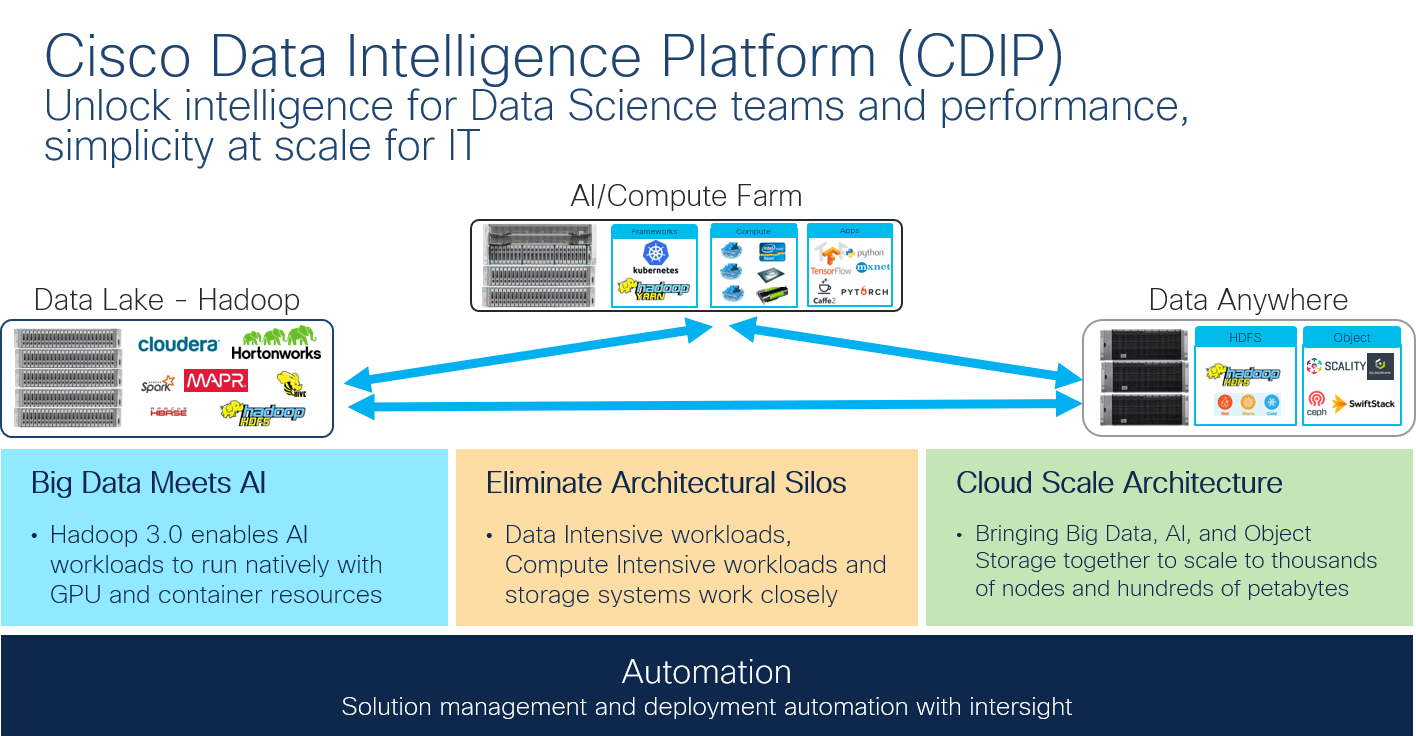
CDIP is a disaggregated architecture that brings together a more integrated and scalable solution for Hadoop. Specifically, it is designed to provide the following benefits to your AI workloads:
- Extremely fast data ingest and data engineering done at the data lake for data intensive workloads;
- AI compute/Kubernetes farm allowing for different types of AI frameworks and compute types (GPU, CPU, FPGA) to perform compute intensive work on this data for further analytics; and
A storage tier, allowing to gradually retire data which has been worked on to a storage dense system with a lower $/TB, hence providing a better TCO.
Most importantly, this architecture seamlessly scales to thousands of nodes with a single pane of glass management using Cisco Application Centric Infrastructure (ACI) and Cisco Intersight, as outlined below:
What’s Next?
We at Cisco are committed to enable customers on their journeys towards data excellence. As another step in our phased approach, you’ll see updates to this architecture that include:
- Providing an agile infrastructure to cater to your data growth fully managed from the cloud with Cisco Intersight and Solution Automation;
- Delivering a tighter integration and richer user (IT / Data scientist) experience with data lake, Kubernetes and Object store in partnership with Cloudera;
- Enabling your data anywhere strategy and lowering TCO; and
- Modernizing your Hadoop infrastructure with Flash.
I will be presenting my vision of Cisco Data Intelligence Platform in my keynote speech at the Strata Data conference, the largest data conference in the world, which takes place in New York City September 23-26. I look forward to seeing you there, but if you can’t make it, feel free to check out our Strata Data conference page to find out everything that we will be up to.





