
It’s been two weeks since the launch of Project Squared and the Cisco Collaboration Cloud. We’ve received fantastic feedback and great uptake. And we’re really happy that so many people are using Project Squared – and liking the experience.
I’d like to take you on a little behind-the-scenes tour and shed some light on the Cisco Collaboration Cloud and how it works. Here is a 10,000 foot view of the architecture:
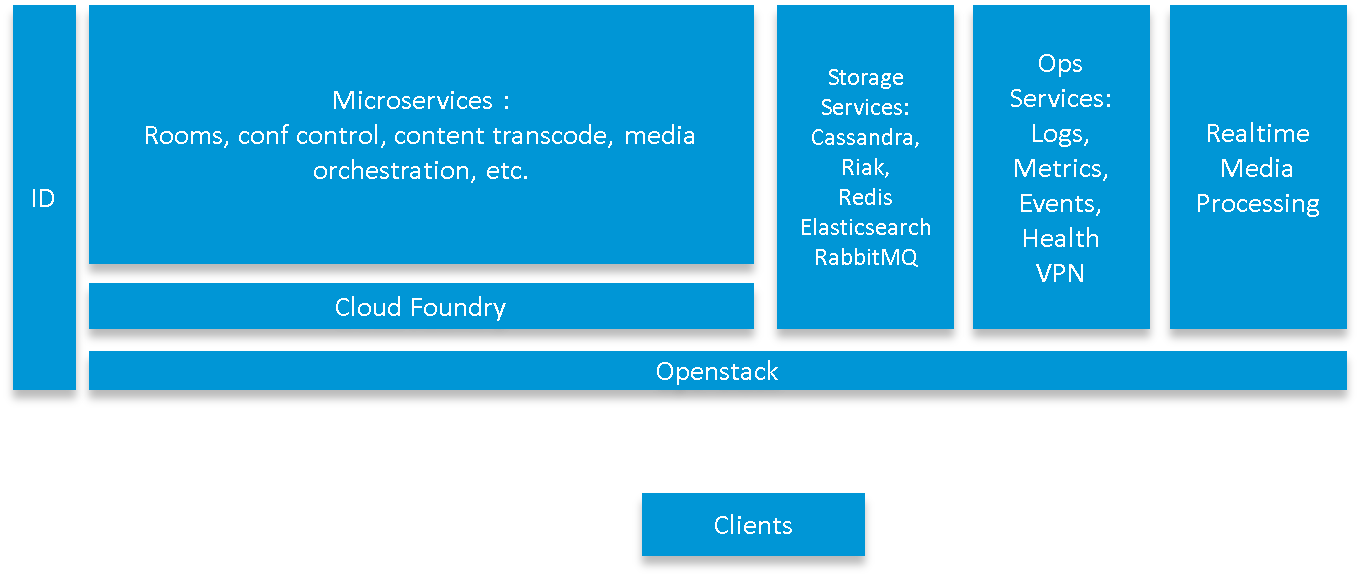
The core architecture is built on OpenStack. We use it for compute, networking, and storage services. OpenStack supports both the functional components of the architecture as well as the operational services, such as: logging, metrics, events, health and even VPN services (for inter-DC messaging and replication).
Much of the functional code is deployed on Cloud Foundry, which we use as our PaaS (Platform as a Service Layer). This functional code is built as a set of microservices, which are coarse-grained elements that provide independent and loosely coupled functions. These functions are consumed by the client and include the room service, which handles room creation, synchronization, and posting of activities.
Other services include document previewing, conference control, media orchestration, avatar management, admin portal services, and notifications. These services are all accessed via REST (aka Web2.0) APIs over HTTPS. We’re an HTTPS-only shop – no unencrypted access.
We use the Cloud Foundry HTTP reverse proxy to distribute inbound requests to the right microservice. Each of these services is stateless: They do not retain any kind of state between HTTP transactions. Any data requiring persistence is placed into one of our data services, which allows our services to achieve horizontal scale and reliability. It also greatly eases software upgrades.
For data storage, we use several different storage technologies: We use a fair amount of noSQL tech, including Cassandra, Riak, Redis, Elasticsearch, and RabbitMQ. We also have more traditional database technologies that support our user identity service, for example. Microservices exchange data through their REST interface alone, and not through shared data services.
Several of our functional components require tight real-time performance and direct, non-proxied network access and thus run natively on OpenStack, and not on Cloud Foundry. This includes our software that does the real-time voice and video-conferencing functions.
And that’s a high level snapshot of what we’ve built. Stay tuned for more deep dives!





Hi Jonathan
Good overview, looks cool and modern. I have a few quick questions.
Inter-DC replication was covered, how do you handle replication between DC-s, do you rely on the storage services like Cassanda replication implementation for Cassandra, Riak for Riak etc ?
Do you do any Chaos Monkey like tests and how quickly monitoring picks up any issues with the services ? What do you use for alerting about issues, is it part of monitoring or a separate sub-system ?
How do you do authentication between the micro-services, is it cert based ?
Depends on your DC setup, but how do you choose the media services for real-time processing in geographically sparse participants ?
Anyway, I have more questions, but looking forward to more deep dives!
@Rain – good to hear from you 🙂
On inter-DC replication: yes we are relying on the replication capabilities of the DB itself. A few of these (eg.., Redis) are used strictly for transient data like caches and thus dont do inter-DC replication.
On chaos monkey: we typically run our entire battery of integaration tests on the production network, constantly. This is primarily functional testing, not the destructive testing that chaos monkey does. Running integration tests on production has been a frequent source of finding outages (though typically lots of other alarms are going off too). We’re working towards a fuller Simian army type of testing but arent there yet.
Inter-service authentication is entire OAuth based. All inter-service comms is via REST, there are no backdoors.
Discovering the right media service to use: this is an evolving story and we’re going to be taking a big step soon in an upcoming push; stay tuned 🙂
Very good high level architecture view and definitely helpful before the deep dive. So far, the experience with the Project Squared is good and sure that it will be more robust (may be with settings, built-in alarms, etc.) soon.
My question would be, when we say that those real time functional components (controllers) runs natively on OpenStack, it could be directly accessed from clients using non-REST interfaces as well. Correct? In that case, it may end up in writing more json API’s and become complex.
Looking forward to hear more during the deep dive.
The stuff running on openstack primarily does real-time media, i.e., RTP.