
Software testing. For a long time, software testing was one of those dark alleys of the software development process. Often ignored, considered as an afterthought, and staffed by “someone else” who did an important job but was outside of the core development process.
Well, that has all changed.
In the SaaS world – especially one governed by continuous delivery – testing is not just an afterthought. It’s a core part of the development process. And like many other engineering processes, there are differing levels of maturity that SaaS development shops can evolve through. In a lot of ways, these different stages of maturity are like Maslow’s hierarchy of human needs. You really, really have to execute on the stuff at the bottom. As you succeed with that you move up to higher levels and achieve greater levels of happiness – in this case through greater quality of software. In the case of testing, each layer is like a filter – each of them catching bugs. The layers at the bottom catch the most basic, easy-to-find bugs. As you go up the stack, the technology helps you catch problems that are rarer and more troubling to identify, reproduce, and fix.
Here is my view on the layers of the hierarchy of SaaS testing needs:
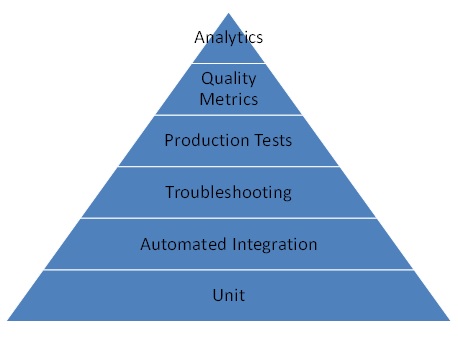
Unit Test: The bottom of the hierarchy is really the only area where things aren’t different between SaaS and premises software. Developers need to build unit tests for the code modules they run. They must be automated and be included as part of the build process. This catches basic programming errors.
Automated Integration Test: SaaS and continuous delivery introduce a unique requirement – that integration test is fully automated. Because of the rapid clip of delivery of software into production, there is no time for manual test. As such, a SaaS delivery shop needs to have an integration environment that contains functional versions of all components – including clients and databases, and automated tests that can stimulate the clients to run tests against the entire system. These tests must be incorporated into the build process and run before code is pushed into production. These tests are built by the developers – not a separate testing team. This layer of the hierarchy catches systemic problems that manifest due to dependencies between cross-functional components.
Troubleshooting: The next level of maturity for SaaS software is to develop troubleshooting tools and processes. These tools typically parse through logs of the various components and show end-to-end flows of how messages and information pass through the system. These tools get utilized by engineering teams to fix sporadic problems – and specifically issues reported by end users – which only sometimes happen and are not caught by integration testing. This layer only catches problems actively reported since it’s a reactive process.
Production Tests (e.g. Chaos Monkey): At this next layer in the hierarchy, the tests used in integration are run against production systems. These tests are used to proactively identify systemic failure cases which are due to the real-time states of the production system, and thus not catchable in integration test. More advanced production tests can proactively cause components or entire data centers to fail, constantly ensuring the system stays available. An example of this is Netflix’s widely discussed Chaos Monkey tool, part of its “Simian Army” of production testing.
Quality Metrics: The next level of maturity is around metrics. Software is developed that produce metrics that measure the actual end-user experiences of quality. For example – in a system that provides a social-networking experience, how many users in a day experience an error when they post an update? And, how long does it take to refresh the feed? Once measured, this allows the developers to understand – quantitatively – what the actual user experience is and, in particular, identify areas where the user experience is not meeting quality objectives, without relying on the users to report those problems. This is then combined with some basic troubleshooting tooling to manually try and reconstruct use cases where a user saw a problem, and to reproduce and fix.
Analytics: The top of the hierarchy involves utilization of data analytics to identify trouble cases, rather than relying on manually going through logs. Specifically, based on metrics, the system would aggregate logs for the failure cases, do automated or semi-automated clustering to group similar ones, and then the engineers can attack the groups of cases in order of priority. Even better if the tools can automatically identify where things fell apart and provide pointers to the trouble spots. This allows for a truly proactive and continuous improvement in software quality. When done well, the success of the efforts on quality improvement are measurable in the improvements in the quality metrics from the prior layer in this hierarchy.





Hi, the image is broken for me.
Do you mean the word “Analytics”, that’s breaking out the chart or don’t you see a picture at all?