
AI/ML is a dominant trend in the enterprise. While AI/ML is not fundamentally new, the ubiquity of large amounts of observed data, the rise of distributed computing frameworks and the prevalence of large hardware-accelerated computing infrastructure has lead to new wave of breakthroughs in AI in the last 5 years or so. Today enterprises are rushing to apply AI in every part of the organization for a wide range of task, from making better decisions, to optimizing their processes.
However, to reap the benefit of AI, one needs significant investments into teams who understand the entire AI lifecycle, especially how to understand, design and tune the mathematical models that apply to their use cases. Often these models use bespoke techniques that are known to a select few who are highly trained in the field. Without this tuning, an enterprise can spend lots of opex running models by following the canonical models. How can we help the enterprise accelerate this step? One way is AutoML
AutoML is a broad class of techniques that help to solve the pain of iterative designing and tuning of models without the personnel investment. It ranges from tuning an existing model (e.g. in hyper parameter search) to designing new network models automatically. For those leveraging Deep Learning, one way is to use Neural Architecture Search (NAS), which aims to find the best neural network topology for a given task, automatically.
In recent years, several automated NAC methods have been proposed using techniques such as evolutionary algorithms and reinforcement learning. These methods have found neural network architectures that outperform bespoke, human designed architectures on problems such as image classification and language modeling and have improved the state of the art on accuracy. However, these methods have been largely limited by the resources needed to search for the best architecture.

We present a method for NAS called Neural Architecture Construction (NAC) [1] – it is a automated method to construct deep network architectures with close to state of art accuracy, in less than 1 GPU day — faster than current state of the art neural architecture search methods. NAC works by pruning and expansion of a small base network called an EnvelopeNet. It runs a truncated training cycle and compares the utility of different network blocks and prunes and expands the base network based on these statistics. Most conventional neural architecture search methods iterate through a full training cycle of a number of intermediate networks, comparing their accuracy, before discovering a final network. The time needed to discover the final network is limited by the need to run a full training and evaluation cycle on each intermediate network generated, resulting in large search times. In contrast, NAC speeds up the construction process because the pruning and expansion can be done without needing to wait for a full training cycle to complete.
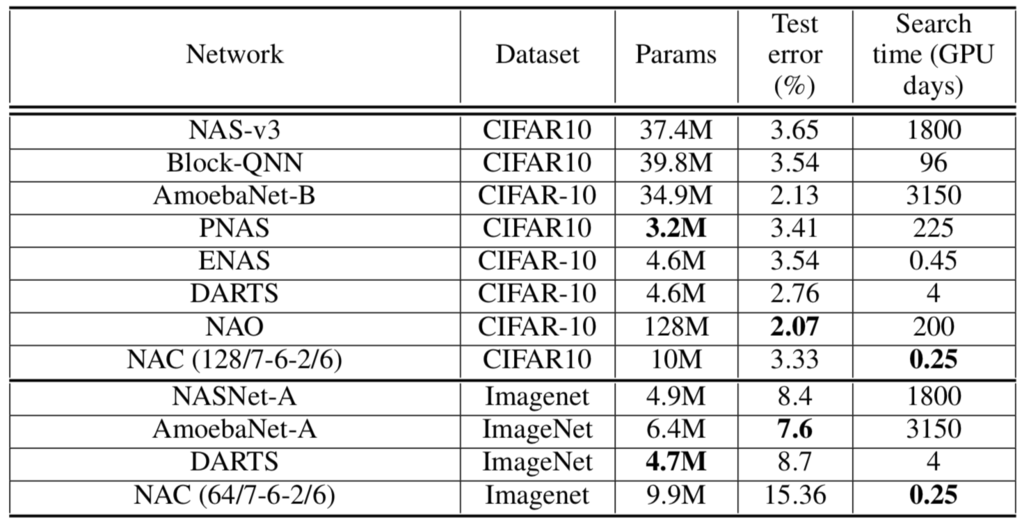
Figure 1: Results comparing our NAC with other state of the art work. Note the search time for both the dataset. The NAC numbers for ImageNet are preliminary.
Interestingly, our NAC algorithm mirrors theories on the ontogenesis of neurons in the brain. Brain development is believed to consist of neurogenesis, where the neural structure initially develops, gradually followed by apoptosis, where neural cells are eliminated, hippocampal neurogenesis, where more neurons are introduced, and synaptic pruning, where synapses are eliminated. Our NAC algorithm consists of analogous steps run in iterations: model initialization with a prior (neurogenesis), a truncated training cycle, pruning filters (apoptosis), adding new cells (hippocampal neurogenesis), and pruning of skip connections (synaptic pruning). Artificial neurogenesis has been previously studied as, among others, a method for continuous learning in neural networks.
We also open sourced a tool called AMLA [2,3], an Automated Machine Learning frAmework for implementing and deploying neural architecture search algorithms. AMLA is designed to deploy these algorithms at scale and allow comparison of the performance of the networks generated by different AutoML algorithms. Its key architectural features are the decoupling of the network generation from the network evaluation, support for network instrumentation, open model specification, and a microservices based architecture for deployment at scale. In AMLA, AutoML algorithms and training/evaluation code are written as containerized microservices that can be deployed at scale on a public or private infrastructure. The microservices communicate via well defined interfaces and models are persisted using standard model definition formats, allowing the plug and play of the AutoML algorithms as well as the AI/ML libraries. This makes it easy to prototype, compare, benchmark, and deploy different AutoML algorithms in production.
To help users incorporate NAS into their regular AI/ML workflows, we are working on integrating our NAS efforts into Kubeflow[4], an opensource platform to simplify the management of AI/ML lifecycles on Kubernetes based infrastructure. Once integrated, these NAS tools will help users optimize network architectures in addition to hyper parameter optimization (e.g. Katib tool within Kubeflow).
We believe that this is just the tip of the iceberg (of AutoML and NAS in particular). However these early results have given us confidence that we can design better mechanisms for AutoML that require less resources to operate, in a step towards accelerating the adoption of AI in the enterprise.
References:
- P. Kamath, A. Singh, D. Dutta “Neural Architecture Construction using EnvelopeNets”, To appear in Neural Information and Processing System (NIPS), Metalearning Workshop, December 2018 . Full version: CoRR, March 2018 https://arxiv.org/abs/1803.06744
- P. Kamath, A. Singh, D. Dutta “AMLA: an AutoML frAmework for Neural Network Design”, International Workshop on Automatic Machine Learning (AutoML Workshop 2018 at ICML 2018), July 2018.
- https://github.com/CiscoAI/amla
- http://kubeflow.org
- Blog: Towards #ConsistentAI





