
![]() Following part two of our Big Data in Security series on University of California, Berkeley’s AMPLab stack, I caught up with talented data scientists Michael Howe and Preetham Raghunanda to discuss their exciting graph analytics work.
Following part two of our Big Data in Security series on University of California, Berkeley’s AMPLab stack, I caught up with talented data scientists Michael Howe and Preetham Raghunanda to discuss their exciting graph analytics work.
Where did graph databases originate and what problems are they trying to solve?
Michael: Disparate data types have a lot of connections between them and not just the types of connections that have been well represented in relational databases. The actual graph database technology is fairly nascent, really becoming prominent in the last decade. It’s been driven by the cheaper costs of storage and computational capacity and especially the rise of Big Data.
There have been a number of players driving development in this market, specifically research communities and businesses like Google, Facebook, and Twitter. These organizations are looking at large volumes of data with lots of inter-related attributes from multiple sources. They need to be able to view their data in a much cleaner fashion so that the people analyzing it don’t need to have in-depth knowledge of the storage technology or every particular aspect of the data. There are a number of open source and proprietary graph database solutions to address these growing needs and the field continues to grow.

You mention very large technology companies, obviously Cisco falls into this category as well – how is TRAC using graph analytics to improve Cisco Security products?
Michael: How we currently use graph analytics is an extension of the work we have been doing for some time. We have been pulling data from different sources like telemetry and third-party feeds in order to look at the relationships between them, which previously required a lot of manual work. We would do analysis on one source and analysis on another one and then pull them together. Now because of the benefits of graph technology we can shift that work to a common view of the data and give people the ability to quickly access all the data types with minimal overhead using one tool. Rather than having to query multiple databases or different types of data stores, we have a polyglot store that pulls data in from multiple types of databases to give us a unified view. This allows us two avenues of investigation: one, security investigators now have the ability to rapidly analyze data as it arrives in an ad hoc way (typically used by security response teams) and the response times dramatically drop as they can easily view related information in the correlations. Second are the large-scale data analytics. Folks with traditional machine learning backgrounds can apply algorithms that did not work on previous data stores and now they can apply those algorithms across a well-defined data type – the graph.
[A polyglot store in this context re-emphasizes pulling data from different database types into one central location. For more information on “telemetry” please visit http://www.cisco.com/web/siteassets/legal/isa_supp.html and http://www.cisco.com/en/US/prod/collateral/vpndevc/ps10142/ps11720/at_a_glance_c45-729616.pdf]
For intelligence analysts, being able to pivot quickly across multiple disparate data sets from a visual perspective is crucial to accelerating the process of attribution.
Michael: Absolutely. Graph analytics is enabling a much more agile approach from our research and analysis teams. Previously when something of interest was identified there was an iterative process of query, analyze the results, refine the query, wash, rinse, and repeat. This process moves from taking days or hours down to minutes or seconds. We can quickly identify the known information, but more importantly, we can identify what we don’t know. We have a comprehensive view that enables us to identify data gaps to improve future use cases.
Fundamentally a graph database is a relational model that is explained via edges and nodes.
Michael: Yes that is the common terminology that people prefer to use. Going back to high school geometry, this is a very intuitive notion of how relationships exist and it’s very generic. Now we can describe things in terms that everyone is familiar with, we don’t have to appeal to more complicated descriptions. This allows everyone to discuss data relationships and how future data should be pursued. For example, in the information security world, we have network level data such as IP addresses, domains, DNS records, WHOIS information, etc. and as we begin to populate that data into a graph model, we start to see the holes and everyone can communicate very clearly about what they see.
Right, because the results coming back seem to be immediately interpretable from a visual – spatial perspective, which is the way that most people’s brains naturally work.
Michael: It is. When we deal with large data sets – say millions or billions of nodes and a high level of connectivity between nodes – the visual perspective isn’t as useful at that scale; it’s just too much information to process. Yet anytime that we have a smaller collection of entities we can effectively ignore the rest of the graph and look at that smaller scale – like one hundred nodes – and really engage the higher level complex thoughts from security professionals who aren’t necessarily experts at development work or the peculiarities of database implementations. We know that everyone who looks at a graph will understand it, since it’s a universal translator.
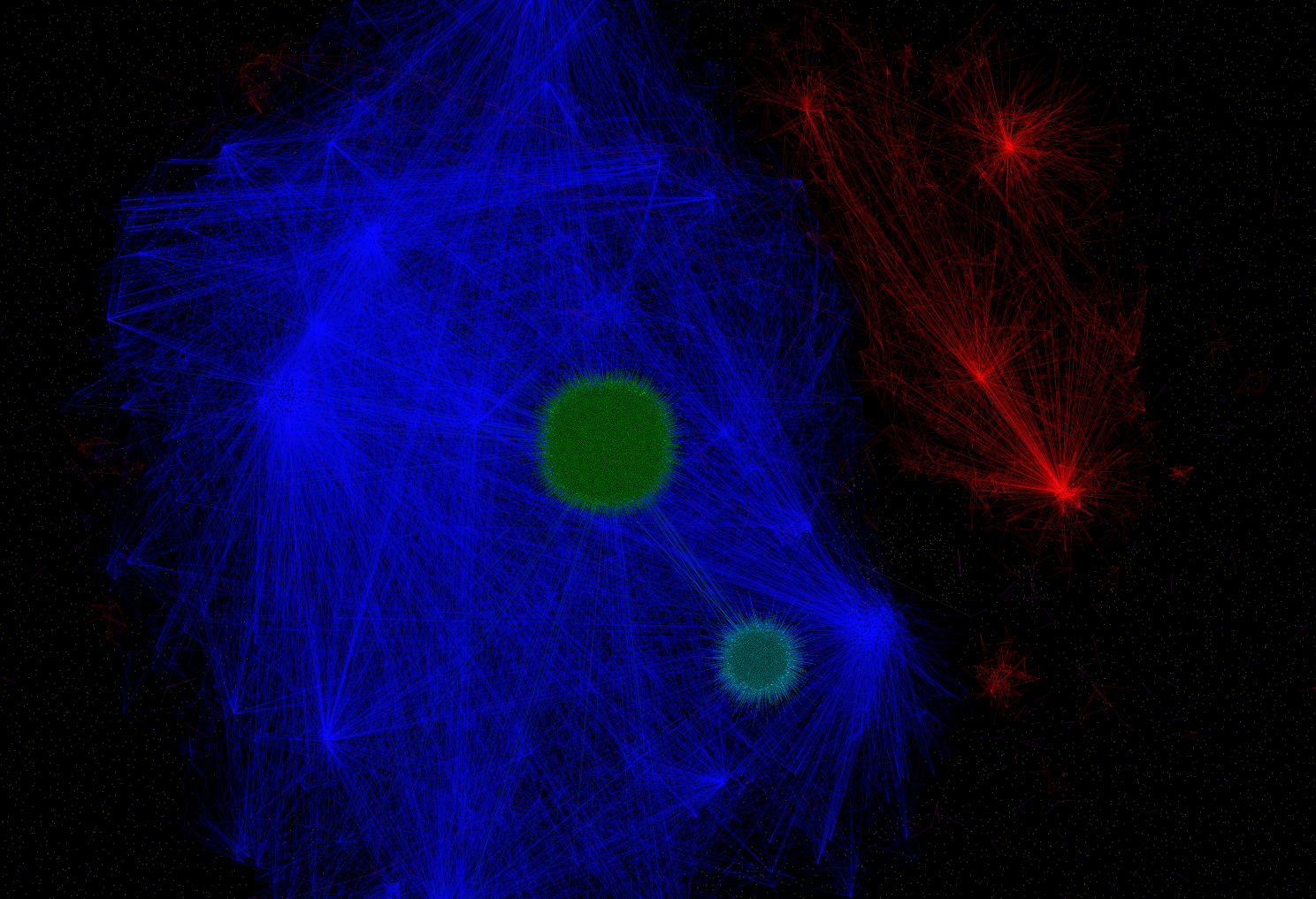
500,000 nodes and edges represented
There are many commercial and open source graph database solutions currently in the marketplace all competing for attention and user share. How did TRAC decide on a graph database solution?
Michael: We did preliminary investigations on a long list of open source solutions and we looked at newer commercial vendors that tie into the Hadoop ecosystem. What we found is that each solution has its benefits and flaws so we are taking a very pragmatic approach, which is to define our use cases first and then determine who best meets our requirements. We are looking at Objectivity’s InfiniteGraph solution because we determined that it has a higher level of throughput than what we have seen in some of the open source options. There are still some tradeoffs, as we may need to move data between stores versus using a solution like Titan that integrates much easier with our Hadoop stack.
Preetham: The current graph database solutions are really divided into smaller solutions designed to run on a single node (even a MacBook) and solutions that leverage the existing framework of distributed computing and distributed storage and add the advantage of graph data presentation on top. So for instance, Titan is an additional layer on an existing Hadoop framework. Generally, this is how the NoSQL landscape is currently divided.
End users like security analysts aren’t as familiar with new proprietary query languages for graph database solutions. Do you consider this when choosing the graph database?
Preetham: We definitely thought about this when we were evaluating different solutions and we knew we needed a query language that a wide range of end users would be comfortable with. Titan supports a query language called Gremlin, which is intuitive and graph database solution agnostic.
Where has the graph database solved a specific challenge for TRAC?
Michael: We are looking at the relationships in our security data, specifically between domains and IP addresses in registry data to verify some of the third-party feeds that we receive in order to identify and whitelist false positives.
Preetham: To Michael’s point, there is a lot of low-hanging fruit that can be easily solved with graph analytics and we will be improving additional data sets that aren’t very structured like WHOIS data, where a country can be represented in different forms such as U.S., USA, United States, etc.
That concludes today’s conversation around graph analytics. Don’t forget to catch-up on this week’s previous Big Data in Security blogs featuring conversations around The AMPLab Stack and TRAC Tools.
Tomorrow, I will be discussing email Auto Rule Scoring (ARS) on Hadoop with Dazhuo Li.
Michael Howe is a TRAC security researcher. Prior to Cisco, he was engaged in cognitive modeling research at the University of Texas at Austin and CU-Boulder. He frequently hops between research and development, pragmatically finding suboptimal solutions in the realms of big and little data.
 Preetham Raghunanda has been an integral part of Cisco’s security business for the past five years doing both research and development. He is enthusiastic about how TRAC is pioneering the application of data science and big data technologies within Cisco Security. In 2008, he earned a master’s degree in computer science from the University of Illinois at Chicago. Prior to that, he held various software engineering roles.
Preetham Raghunanda has been an integral part of Cisco’s security business for the past five years doing both research and development. He is enthusiastic about how TRAC is pioneering the application of data science and big data technologies within Cisco Security. In 2008, he earned a master’s degree in computer science from the University of Illinois at Chicago. Prior to that, he held various software engineering roles.







