
I’ve written about NUMA effects and process affinity on this blog lots of times in the past. It’s a complex topic that has a lot of real-world affects on your MPI and HPC applications. If you’re not using processor and memory affinity, you’re likely experiencing performance degradation without even realizing it.
In short:
- If you’re not booting your Linux kernel in NUMA mode, you should be.
- If you’re not using processor affinity with your MPI/HPC applications, you should be.
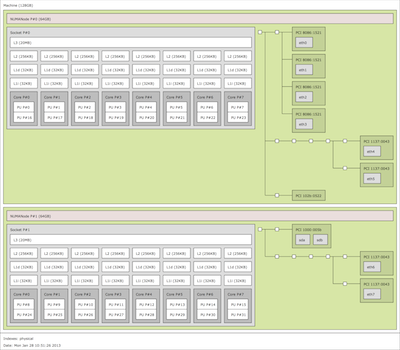
Take the look at this hwloc-drawn schematic of the inside of a modern Intel “Sandy Bridge”-based server (click on it for the full-sized image). Notice a few things about it:
- Each processor core has its own L1 and L2 caches. They aren’t shared.
- The L3 cache is shared among all processor cores on the same processor socket.
- Nothing is shared — not even back-end RAM — between processor cores on different processor sockets.
- There’s multiple different network interfaces, and each is local to a specific NUMA node.
I mention these things because they all have distinct performance implications in an HPC application. Let’s go through each of those points again, in order:
- You absolutely do not want any individual HPC process to migrate to a different processor core. Doing so would invalidate all your L1 and L2 cache entries, which could cause all manner of cache misses and pipeline stalls. If this happens frequently, overall performance can plummet.
- The L3 on this particular chip (Intel ) is fairly large (20MB) — it somewhat mitigates the cost of process movement within a single processor socket. This is good. But if your process is L1/L2-cache sensitive, it may not be enough.
- If the OS decides to move your process to a different processor socket, you’ve lost it all — your immediate data in the L1 and L2 caches, whatever secondary storage you had cached in L3… all of it. Ouch. L1 and L2 cache misses are bad enough; L3 cache misses and resulting pipeline stalls… Ouch.
- When sending and receiving MPI messages, if your application is latency-sensitive, you really only want to use the network interfaces that are on the same NUMA node as the target process. Otherwise, your MPI message has to traverse to the other NUMA node before it gets to the network hardware, thereby incurring additional delay.
There are actually two performance effects from these three items. We already discussed how overall latency can be affected on each operation.
But don’t forget that network congestion is another important performance effect.
“That’s crazy talk!” you say. “We’re talking about the inside of a single server. There’s no network here!”
Not so, my friend. Don’t forget what connects all the NUMA nodes and processor sockets together: QPI (or HyperTransport in AMD machines). That’s a network. A full-blown, real network. With protocols, packets, and checksums. Oh my!
You can’t completely eliminate the amount of traffic that is flowing across the NUMA-node-connecting-network, but you do want to minimize it. Networking 101 tells us that, in many cases, reducing congestion and contention on network links leads to overall better performance of the fabric. The same principle is true on networks inside a server as it is for networks outside of a server.
Using processor and memory affinity helps minimize all of the effects described above. Processes start and stay in a single location, and all the data they use in RAM tends to stay on the same NUMA node (thereby making it local). Caches aren’t thrashed. Well-behaved MPI implementations use local NICs (when available). Less inter-NUMA-node traffic = more efficient computation.
With all that background, let’s go back and address the two first points from this blog entry:
- If your Linux kernel (and/or BIOS) is ignoring the NUMA layout of RAM, the memory associated with one process may be located on a remote NUMA node. Result: lots of inter-NUMA-node traffic to get to that memory. Bad. When Linux is NUMA-aware, it will (by default) make an effort to use memory on the NUMA node local to the allocating process.
- Process affinity controls in modern MPI implementations and operating systems are getting pretty good. By telling the MPI implementation to bind processes to unique cores or sockets (typically via a command line parameter or environment variable), the OS won’t migrate processes around, and you might see a bit of a performance boost in your applications. For free.
Use affinity. It’s a Good Thing. And it’s likely free and easy to enable in your MPI implementation / operating system already.
(Final note: the particular server shown in this example only has one processor socket per NUMA node. Things get even more… interesting… if there are multiple sockets per NUMA node.)





