
 We are ramping up another news cycle around our Nexus 1000V and cloud network services portfolio this week at Cisco live! in London. Among the updates, business security solutions vendor Imperva is demonstrating integration of its SecureSphere Web Application Firewall (WAF) into the Nexus 1000V vPath service insertion architecture. This marks the first third party product to participate in the Cisco vPath architecture, which allows virtual services to be easily inserted and chained into Cisco virtual networks and virtual overlays.
We are ramping up another news cycle around our Nexus 1000V and cloud network services portfolio this week at Cisco live! in London. Among the updates, business security solutions vendor Imperva is demonstrating integration of its SecureSphere Web Application Firewall (WAF) into the Nexus 1000V vPath service insertion architecture. This marks the first third party product to participate in the Cisco vPath architecture, which allows virtual services to be easily inserted and chained into Cisco virtual networks and virtual overlays.
[Note: Join Cisco for a Live Announcement Webinar on Cloud Innovations on February 5: Register Here]
Regular readers of our data center and cloud blog will probably recall the importance of vPath in enabling virtual services for virtualized multi-tenant cloud environments, and for allowing policy mobility along with VM mobility. The Cisco vPath architecture currently supports our own virtual services including Virtual Security Gateway (VSG), the ASA 1000V Cloud Firewall, and virtual WAAS for WAN optimization. vPath also boosts performance of service traffic paths and orchestrates service chaining so that VM traffic is processed in a ordered chain defined by policy.
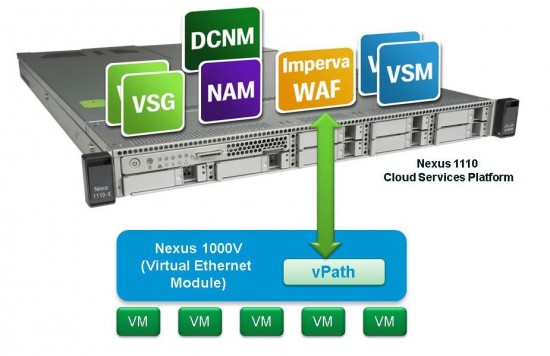
Last year, Imperva announced integration with the Nexus 1110 Cloud Services Platform. This latest demonstration shows further simplification through interactions with the Nexus 1000V vPath, as the above diagram shows. The vPath architecture is flexible and extensible, providing greater options in the future for customers through a broader 3rd party ecosystem, including Imperva. (Yesterday we also blogged about Citrix’ virtual NetScaler VPX on the Nexus 1110).
For securing virtualized and cloud environments, customers need a defense-in-depth security architecture that demands multiple virtual firewalls, including zone-based firewall, tenant-edge firewall and web application firewall (WAF). The Imperva SecureSphere WAF, in conjunction with Cisco’s Virtual Security Gateway (VSG) and ASA 1000V cloud firewalls, can offer customers a comprehensive multi-tier virtual firewall solution. Together, the joint solution can simplify deployment of Web application security in virtualized data centers.
The SecureSphere WAF with Cisco Nexus 1000V vPath support helps customers to:
- Steer Web traffic through the SecureSphere WAF, even in complex and heterogeneous datacenters with multiple virtual services.
- Migrate SecureSphere WAF virtual machines to new host machines without impacting application sessions.
- Maximize application uptime through fail open Web application firewall configuration.
Imperva is hosting a technology preview of the Cisco Nexus interoperability at Cisco Live London starting today. The demonstration showcases the Imperva SecureSphere WAF hosted on the Cisco Nexus 1110 and the SecureSphere WAF interoperating with Cisco Nexus 1000V and vPath. If you are at the show in London, please visit them in booth E1.
Related: More on the Imperva and Cisco Collaboration (Imperva blog)
Related: Citrix NetScaler VPX Gets Going on the Nexus 1110 Virtual Services Platform




