
Originally published in the book: Gray, Ken & Nadeau, Thomas. Network Function Virtualization, 1st Edition. (2016). Morgan Kaufman, also available here.
This book by Ken and Tom on NFV is perhaps the first time they’ve laid out both a fantastic review of the vast landscape of technologies related to virtualized networking and woven in a subtle argument and allusion to what the future of this technology holds. I may be drunk on my own Koolaid, but I certainly read the book with a specific lens which is one in which I asked the question “Where are we on the maturity continuum of the technology and how close is it to what operators and customers need or want to deploy?” The answer I believe I read from Tom and Ken is that “We’ve only just begun.” (Now try and get Karen Carpenter out of your head while reading the rest of this :)) What I mean by this is that over the last say 6 years of trade-rag-eye-ball-seeking articles, the industry has lived through huge hype cycles and ‘presumptive close’ arguments of download-install-transition-your-telco/mso to a whole new business.
What K/T lay out is not only an industry in transition but one that is completely dependent on the pace being set by the integration of huge open source projects and proprietary products, proprietary implementations of newly virtualized appliances, huge holes in the stack of SW required to make the business: resilient, anti-fragile, predictable, supportable, able to migrate across DCs, flexibly re-arrangeable, a whole mess of additional x-ilities and most importantly… operate-able and billable. Thing is, this transition MUST happen for the industry and it MUST happen in many networking dependent industries. Why? Because the dominant architecture of many SPs is one in which flexible data centers were not considered part of the service delivery network. On-demand user choice was not the norm. Therefore, trucking in a bunch of compute-storage-switching (aka Data Centers) does not by itself deliver a service. SPs build services in which there are SLAs (many by regulation in addition to service guarantees), guarantees of experience, giving access to any and all new devices that arrive on the market and as a goal focus on building more and more uses of their network. The key thing that this book lays out is that: it’s complex, there are a ton of moving parts, there are layers upon layers, there are very few people if in fact any that can hold the entire architecture in their head and keep track of it. And most importantly: we are closer to the starting line than the finish line.
Thankfully as K/T laid out in another book, we have made it through the SDN-hype cycle and it’s being rolled out across the industry. We watched the movie “Rise of the Controllers” and the industry is settled down and deploying the technology widely. Now we are to the point where virtualizing everything is the dominant topic. Technology progresses. Thing is, it requires a lot of “stack”, and all that’s necessary in that stack doesn’t exist today and is in various stages of completeness, but not integrated into something consistent or coherent yet. Also, when someone says VNF (virtualized network function) or NFV (network function virtualization): A) it applies to more than networking related stuff, see video production and playout services and B) the terms were defined when hypervisors where the only choice for virtualization. Now that containers are available; we have to clearly set the industry goal that “cloud native” (which is basically a synonym for containerized applications) is the ultimate endpoint; until the next wave comes in. The real point is that lifting and shifting of physical appliances to hypervisor based VNFs (necessary first step but not sufficient) led to one particular stack of technology but cloud-native leads to a different variant. One in which use of DC resources is dramatically lower, time to boot/active service is faster and parallelism is the central premise. For the love of all the G*ds, I truly hope that the industry doesn’t stall prematurely. Without knowing what K/T are up to next; it’s an easy prediction to make that this book will have a potential for 42 versions of publication as today it documents the first steps toward this industry revolution.
The implicit argument that I read throughout the book is that we are seeing the end of the feudal reign of siloed organizations and technical structure of long lasting beliefs of the architecture of the Internet. The next conclusion I came to is that we are at the point where the OSI model should only be taught in history books. It’s close to irrelevant and assumptions that don’t hold water today. What K/T laid out (although they don’t spell it out this way so I’ll take the liberty) is that there are now so many more explicit first-class citizens in the Internet architecture that our old notions of layering have to be wholesale rejected. What are these new first class citizens? Identity, encapsulation/tunneling, specific application treatment, service chains, security, privacy, content as endpoint, dependent applications performing as workflows, access agnosticism, multi-homing, location independence, flat addressing schemes, unique treatment/augmentation per person, and a desire that the network and the service someone or some business requested reacts to repair itself and reacts to experience that is desired… to name a few.
Ok, let me dial it back a little and try and explain how I got this worked up. I reached the same point K/T discuss in the book that the stack to virtualize networks goes way beyond the concepts of SDN. As the reader probably understands, SDN is a key ingredient to enable NFV but alone it only does part of the job. I’m going to switch terms from what K/T use and describe the high-level goal as “Reactive Networking.”
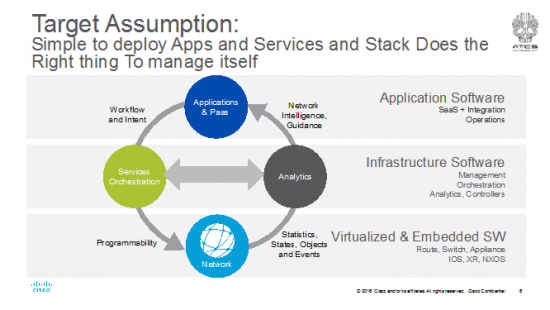
The industry has been making progress towards this target in the open source community and somewhat in standards bodies (e.g. MEF, IETF, ETSI etc). Services orchestration now includes SDN controllers. Many are working toward an implementation of MANO, the orchestration framework that can create virtualized services per tenants or customers. There are service orchestration products on the market; I lumped them all together in the greenish bubble on the left. The network can now be built around strong, programmable forwarders. Providing a solid analytics platform is needed immediately and work is already underway. This is key because in this day and age we can’t actually correlate a network failure to video quality analytics. Meaning that a country full of video viewers just had their content tile because a link went down somewhere and no one has any idea what caused it. Yep, it’s the case right now we can’t correlate any networking or NFV event to service quality analytics. It’s all siloed. Everything today is compartmentalized to its fiefdom or rigidly stuck in it’s OSI layer. One of the magical cloud’s most important contributions to the industry is the notion of a PaaS. Request a service and voilà, it’s working. We need to get NFV to the PaaS and cloud designs for relevancy. But, at the same time, have to make networking relevant in the PaaS layer. Today you can dialup/request CPU, RAM, Storage but not networking (even bandwidth) in any cloud.
That last fact is horribly depressing to me, but I understand some of the reasons why. In cloudy DCs available today the Internet is considered ubiquitous and infinite. The services put in the cloud are built on that assumption and are most often not IO constrained (note that there are just about no VNFs available either); they are CPU, RAM and Storage constrained. They are built for web services type workloads. When they are IO bound, you pay for it (aka $) in a big way via massive egress bandwidth charges. As mentioned, you can pay for it but you can’t provision it. Sucks. But read what I wrote way above, in SP cloudy DCs, the Internet is also ubiquitous but they have a big business around SLAs, best of class experiences and stuck dealing with regulations. Therefore, in an SP network the Internet is also infinite, but it is purposefully engineered to meet those goals of best in class, on-all-the-time and guaranteed. VNFs in an SP cloud are sources and sinks of mostly IO and the VNFs are chained together and orchestrated as a complete service. For example, a virtual router, load balancer, firewall, anti-DDOS, anti-malware, IPS, cloud storage, etc. are all one bundle for the end-customer. For the SP, it’s a service chain per tenant (yes, it could also be deployed as a multi-tenanted service chain) who also fundamentally bought a 1 or 10Gig end-to-end access and security service++. Therefore, the virtualized services are directly tied to a residential or business customer who is buying a complete turnkey service. And they want something new tomorrow. Not only more and more bandwidth but services available that are cool, valuable and going to solve their problems. The fact the SP uses VNFs to reduce cost, add more flexibility to service delivery (aka new stuff all the time) is great for the end customer, but the SP has to build an end-to-end service from access through to VNFs and to the Internet seamlessly. The DC has to be orchestrated as a part of the complete network and not as an island. The stack to do this is across domains, as K/T explain is very complex.
That last note on complexity is the key to the point of the picture above. The stack for NFV has to be fully reactive and does the right thing to manage itself. Elastic services (expanding and contracting on demand), migrating workloads (aka VNFs), life-cycle management, low-cost compute and storage failures, constantly changing load in the network, load engineering in the DC all require that bus between the analytics platform and orchestration to be functioning well or we are going to end up with an old-school event->alarm->notify->trouble ticketing system of the last decades all over again.
As K/T explain throughout the book and really do a great job at simplifying: the stack is complex. Towards that end, there’s another concept in the industry of the “whole stack” developer. This concept is that for an app developer or service designer in the NFV space, to do their job well, they need to understand the “whole stack” of orchestration++ infrastructure below their app or service to get their job done. The goal for the NFV industry hopefully isn’t going to be towards this end. <This tangent is a moderately interesting argument in the intro of a book that attempts to describe the whole stack and how important it is to understand.> Where I differ and I’d bet that K/T might agree, is that the industry target has to be to a “No Stack” developer. That’s the point of having a fully reactive, do-what-I-need, do-what-I-want set of orchestration and analytics software. A service designer for NFV probably doesn’t want to know the goop and infinite layers below and IMHO, shouldn’t care less. It’s all being swapped out and upgraded to the latest and greatest new set of tools and services tomorrow anyways. I posited above that there are very few, if any people that could fit the entire architecture at any point in time into their heads anyways. Let alone all the APIs, function call flows, events, triggers and fubars that’s happening underneath at any point in deployment.
So, I offer this diagram derived from the chapters of the book and my own hallucinations:
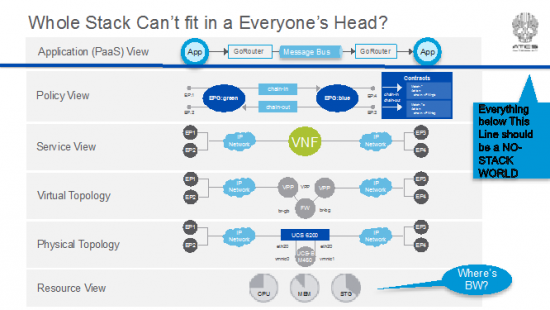
Everything below that blue line represents all the networking layers that the NFV stack has to config/provision, spew telemetry data, collect and correlate in the analytics platform, react to changes in the network, reprogram the network, spin up elastic VNFs, life-cycle manage them, create service chains, apply to tenants changing service requests, etc, etc, etc. Please see the book attached to the intro for details. 🙂
All the service designer or app developer or the SP’s OSS/BSS should see as a result is way up at the top programmed and managed via the Service Platform. In industry terms it’s a PaaS layer (which today doesn’t exist for NFV but IT is exactly the target the industry needs to hit). The history of SDN, controllers, changes to embedded OS’ that enable generic apps to run on them, orchestration platforms and biggest data platforms is one of chasing the developer. The industry chased each new building block during the creation of the stack believing that developers would be attracted to their API set and developer platform. Apps on the router/switch, apps on the SDN controller, analytics apps… in fact they all were right in the end and all wrong. But to date, none have emerged as more than pieces of infrastructure in the stack and as application platforms for very specific outcomes. This point is often really hard to explain. An SDN controller is both infrastructure and an app platform? Yes. In an overall NFV or orchestration stack, it’s infrastructure. It’s the thing that speaks SDN protocols to program the virtual and physical topologies and ultimate resources. As an app platform, it’s unbelievably awesome for an IT pro or engineer trying to debug or program something very specific. But, it may not be the right tool for an overall NFV lifecycle manager and service orchestrator. Rinse and repeat the argument for the on-box apps or analytics platform. Great for certain types of apps in specific scenarios, but awesome as infra in an overall infrastructure orchestration stack. And perfect if linked together by high performance message busses to enable reactive networking.
Here’s a pic of the situation:
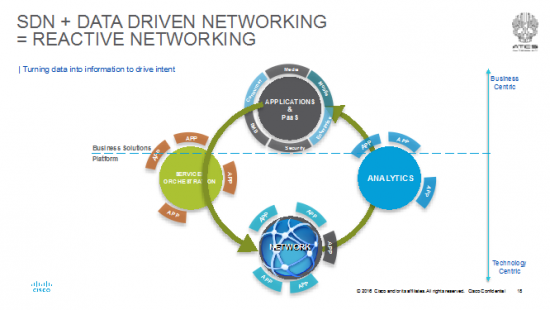
Assume the dashed line in this picture is in the same location as the solid blue line in the previous picture. The more technology centric you get, the more the apps become very specific for a task or job. All the action for an SP or Enterprise to deliver a business outcome or service is at the PaaS layer. The reason I say this is that dragging all the APIs and data models from lower layers in the layered stack all the way to the NFV service designer or app developer == dragging every single feature, event, trigger and state to the top. No one builds a cloud service that way and it would be a modification to the old saying and now be “Luke, use the 1 Million APIs.”
Projecting forward to future versions of K/T’s book, the argument I read in this book and conclusion I came to could be a world that looks something like this:
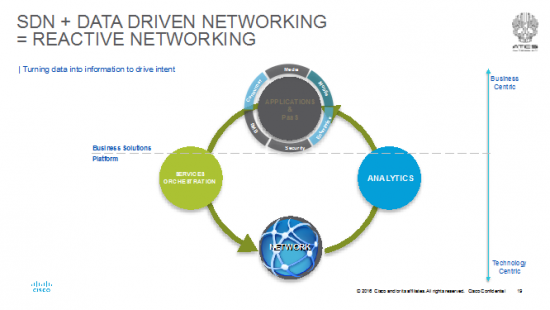
The “No Stack” developer, designer and deployer is in an industry where there’s a PaaS that has a rich catalogue of VNFs and VxFs (I hate to admit it, but not everything is Networking related; e.g. transcoders for JIT, CDN caches, etc). The Stack takes care of itself. The entire network (including DCs) is load, delay, jitter engineered as a whole; services are bought and sold on demand and the entire system reacts and can recover from any change in conditions.
Note this 100% does NOT mean that there has to be a grand unification theory of controllers, orchestration systems, analytics platforms to achieve this. K/T go to great lengths to describe access != WAN != DC != peering policy != content caching policy. This does mean there’s room for NNI interfaces in between specific controllers for access, campus, WAN, DC as each of the resource, physical and virtual devices, etc. is unique. But it does mean that a cross domain orchestration system that can place and manage VNFs on-prem, in a CO or head end or centralized DC is a reality. As much as I dislike grand-unification theories, I dislike centralized vs distributed and on-prem vs cloud debates. As K/T describe, they are pointless arguments and really boring conversations at a dinner party. All of the scenarios are going to emerge. Sooner we face up to it, the sooner we can get building it and not get wrapped around the axle of use-case jousting.
This being said, there are some fundamentals that make this challenging and a ton of work to round out the different mechanisms to orchestrate VNFs wherever they may be placed. Let me give a couple examples. How much resource does a VNF need? What I mean is in terms of: CPU cores/cycles, RAM, Storage and what are the capabilities and attributes of the VNF? Can it fling 10Gpbs? 1? 100? How/ where can we describe this? That “manifest” format doesn’t exist yet, though there is work being done specifically for VNFs. Note that it doesn’t really exist for anything virtualized via hypervisors or containers in general either. Virtualized forwarding (switching or routing) recently was a trouble area but this status has recently changed w/ the introduction of fd.io. The platform for network data analytics is just about to emerge as I write this. Most VNFs are not cloud native yet and are stuck in the lift and shift model and in heavyweight hypervisors. Yep, the industry is making it work but for how long before economic and complexity collapse? Can I reduce the overlay/underlay operational headache to a single flat layer with a flat addressing scheme like IPv6 could provide? Probably yes. Linkages to OSS/BSS and other management systems haven’t been defined. Is the PaaS I describe above really the new (re)formulation of a SPs OSS/BSS? Some operators are alluding to it. As a customer, am I going to have the cloud-based experience to see the state of my entire network services? I say this because most often a customer has no way of verifying except packets are flowing or not. What about the user experience of different roles within the enterprise or SP? Thankfully, the notion of bring this to a PaaS layer means these different questions appear to have some answers as the orchestration and analytics platforms can both be utilized at the “outcome” services of PaaS. This enables someone to re-render the data into an operational experience that meets the different roles of an operator and necessary information to an end-customer. The earlier diagrams Jedi-mind trick “these are not the layers you are looking for” into an outcome like this:
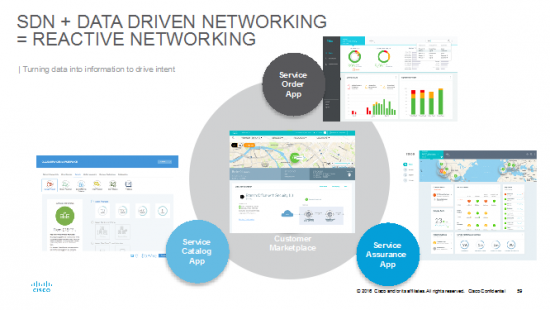
This is all the same data available at the PaaS to enable:
- an on demand customer marketplace for the end-user
- service catalogue app for the service designer
- service order app for the product manager (what’s the status of my customer’s deployment)
- service assurance app for the operator (in which the layers and services have been identified and tracked to render the data from resource to policy and every way of viewing in between)
Ok, I’ve been riffing and ranting for a while and you really want to get to the book so, let’s start bringing this to a close. The overall goal, drawn slightly differently again, is to deploy VNFs as a part of an engineered end-to-end service. There are physical resources of compute, switching storage (hopefully orchestrated in a “hyper converged manner”) which is enabled by a cloud platform using hypervisors, containers, both programmed by SDN controllers with telemetry data spewing out to the Model Driven orchestration and analytics platforms.
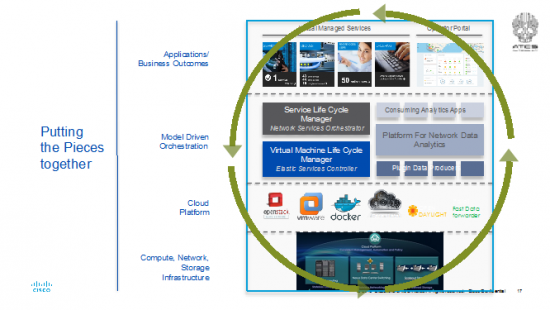
Topped off by a service rich PaaS that may emerge in future revisions of the book as being segment specific because of service differences. Also, we already know some of the immediate next scenes in this screenplay. One of the immediate scenes required is an answer to the question “What do I need to install to deploy X Tbps of Y NFV service?” Today, there are no academic or engineering models that can answer that question. Particularly with the lack of IO optimized computer platforms on the market. As mentioned NFV services are IO bound and not necessarily cycle or RAM (and certainly not storage) bound. A lift and shift architecture to get a physical device into a hypervisor isn’t particularly hard but also not particularly efficient. So another scene is going to be how fast are VNFs enabled as cloud native. Another one is going to be around common data models that have to emerge in the standards bodies to be able to orchestrate a rich ecosystem of suppliers.
As mentioned right up front, this is a fast moving space with a lot of details and coordination that has to occur which MUST be simplified to “No Stack” delivery. BUT the whole purpose of continuing on with the book is to get the details of why, how, where, what-were-they-thinking with respect to the big NFV story from Ken and Tom. I certainly hope that K/T have great success and I fully predict they have a great career writing the next 41 revisions of the book as this area of technology is moving FAST.
Dave Ward, Cisco
2016.04





Great article, and of course for mi OSI will be relegated to history books, thanks to the continue evolution of available technology and yet the one to come.